架构概述#
Ray Serve LLM 是一个专门针对分布式 LLM 服务工作负载的 Ray Serve 原始组件框架。本指南将解释支持可扩展且高效的 LLM 推理的核心组件、服务模式和路由策略。
Ray Serve LLM 提供什么#
Ray Serve LLM 能够利用单个推理引擎(如 vLLM)的性能,并将其扩展以支持
水平扩展:在同一节点或跨节点的多 GPU 上复制推理。
高级分布式策略:协调多个引擎实例以实现预填充-解码分离、数据并行注意力以及专家并行。
模块化部署:将基础设施逻辑与应用程序逻辑分离,实现清晰、可维护的部署。
Ray Serve LLM 在高度分布式的多节点推理工作负载中表现出色,其中扩展单元跨越多个节点
跨节点流水线并行:服务无法容纳在单个节点上的大型模型。
预填充-解码分离:独立扩展预填充和解码阶段,以获得更好的资源利用率。
集群范围并行:将数据并行注意与专家并行结合,用于服务大型稀疏 MoE 架构,如 Deepseek-v3、GPT OSS 等。
Ray Serve 原始组件#
在深入了解架构之前,您应该了解这些 Ray Serve 原始组件
部署 (Deployment):定义扩展单元的类。
副本 (Replica):部署的一个实例,对应一个 Ray actor。多个副本可以分布在集群中。
部署句柄 (Deployment handle):一个对象,允许一个副本调用其他部署的副本。
有关更多详细信息,请参阅 Ray Serve 核心概念。
核心组件#
Ray Serve LLM 提供两个主要组件,它们协同工作以服务 LLM 工作负载
LLMServer#
LLMServer 是一个 Ray Serve *部署*,用于管理单个推理引擎实例。此*部署*的*副本*可以三种模式运行
独立模式:每个*副本*独立处理请求(水平扩展)。
部署内协调:多个*副本*协同工作(数据并行注意力)。
跨部署协调:副本与不同部署协同工作(预填充-解码分离)。
以下示例演示了如何单独使用 LLMServer 的框架
from ray import serve
from ray.serve.llm import LLMConfig
from ray.serve.llm.deployment import LLMServer
llm_config = LLMConfig(...)
# Get deployment options (placement groups, etc.)
serve_options = LLMServer.get_deployment_options(llm_config)
# Decorate with serve options
server_cls = serve.deployment(LLMServer).options(
stream=True, **serve_options)
# Bind the decorated class to its constructor parameters
server_app = server_cls.bind(llm_config)
# Run the application
serve_handle = serve.run(server_app)
# Use the deployment handle
result = serve_handle.chat.remote(request=...).result()
物理放置#
LLMServer 通过放置组 (placement groups) 控制其组成 actor 的物理放置。默认情况下,它使用
{CPU: 1}用于副本 actor 本身(无 GPU 资源)。world_size个{GPU: 1}捆绑包用于 GPU 工作进程。
world_size 计算为 tensor_parallel_size × pipeline_parallel_size。vLLM 引擎根据捆绑包的邻近性分配 TP 和 PP 等级,优先在同一节点上分配 TP 等级。
PACK 策略尝试将所有资源放置在单个节点上,但在必要时会提供不同的节点。这对于大多数部署都很有效,尽管异构模型部署有时会在节点之间运行 TP。

GPU 工作进程的物理放置策略#
引擎管理#
当 LLMServer 启动时,它会
创建一个 vLLM 引擎客户端。
启动一个后台进程,该进程使用 Ray 的分布式执行器后端。
使用父 actor 的放置组来实例化子 GPU 工作进程 actor。
在这些 GPU 工作进程上执行模型的正向传播。
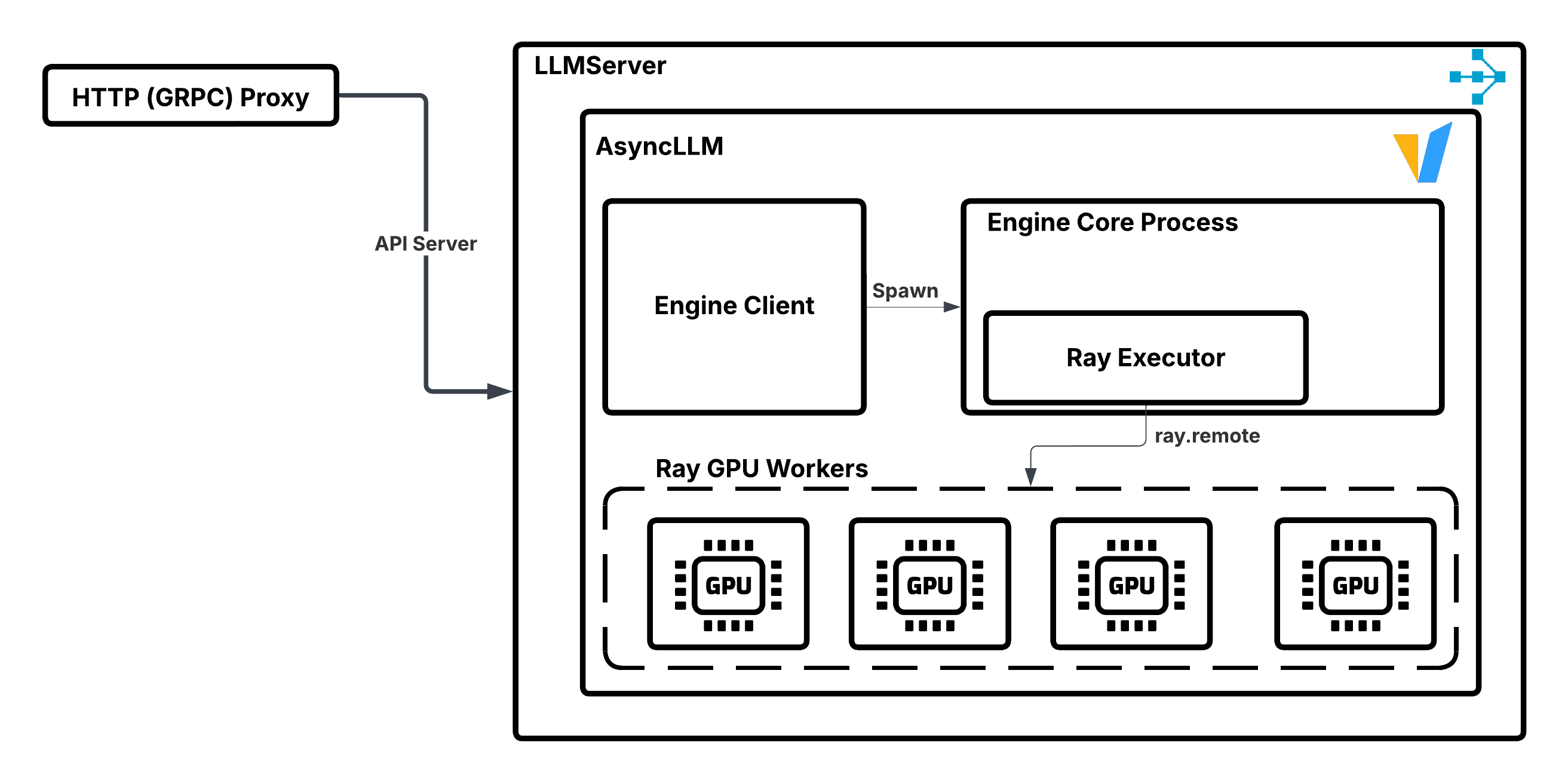
LLMServer 管理 vLLM 引擎实例的说明。#
OpenAiIngress#
OpenAiIngress 提供了一个兼容 OpenAI 的 FastAPI 入口,用于将流量路由到合适的模型。它处理
标准端点定义:
/v1/chat/completions、/v1/completions、/v1/embeddings等。请求路由逻辑:自定义路由逻辑的执行(例如,基于前缀或基于会话的路由)。
模型多路复用:LoRA 适配器管理和路由。
以下示例展示了一个包含 OpenAiIngress 的完整部署
from ray import serve
from ray.serve.llm import LLMConfig
from ray.serve.llm.deployment import LLMServer
from ray.serve.llm.ingress import OpenAiIngress, make_fastapi_ingress
llm_config = LLMConfig(...)
# Construct the LLMServer deployment
serve_options = LLMServer.get_deployment_options(llm_config)
server_cls = serve.deployment(LLMServer).options(**serve_options)
llm_server = server_cls.bind(llm_config)
# Get ingress default options
ingress_options = OpenAiIngress.get_deployment_options([llm_config])
# Decorate with FastAPI app
ingress_cls = make_fastapi_ingress(OpenAiIngress)
# Make it a serve deployment with the right options
ingress_cls = serve.deployment(ingress_cls, **ingress_options)
# Bind with llm_server deployment handle
ingress_app = ingress_cls.bind([llm_server])
# Run the application
serve.run(ingress_app)
注意
您可以创建自己的入口部署并将其连接到现有的 LLMServer 部署。当您想自定义请求跟踪、身份验证层等时,这非常有用。
网络拓扑和 RPC 模式#
当入口通过部署句柄向 LLMServer 发起 RPC 调用时,它可以访问任何节点上的任何副本。然而,默认请求路由器会优先考虑同一节点上的副本,以最大限度地减少跨节点 RPC 开销,这在 LLM 服务应用中(在高并发下对 TTFT 的影响只有几毫秒)影响不大。
下图说明了数据流
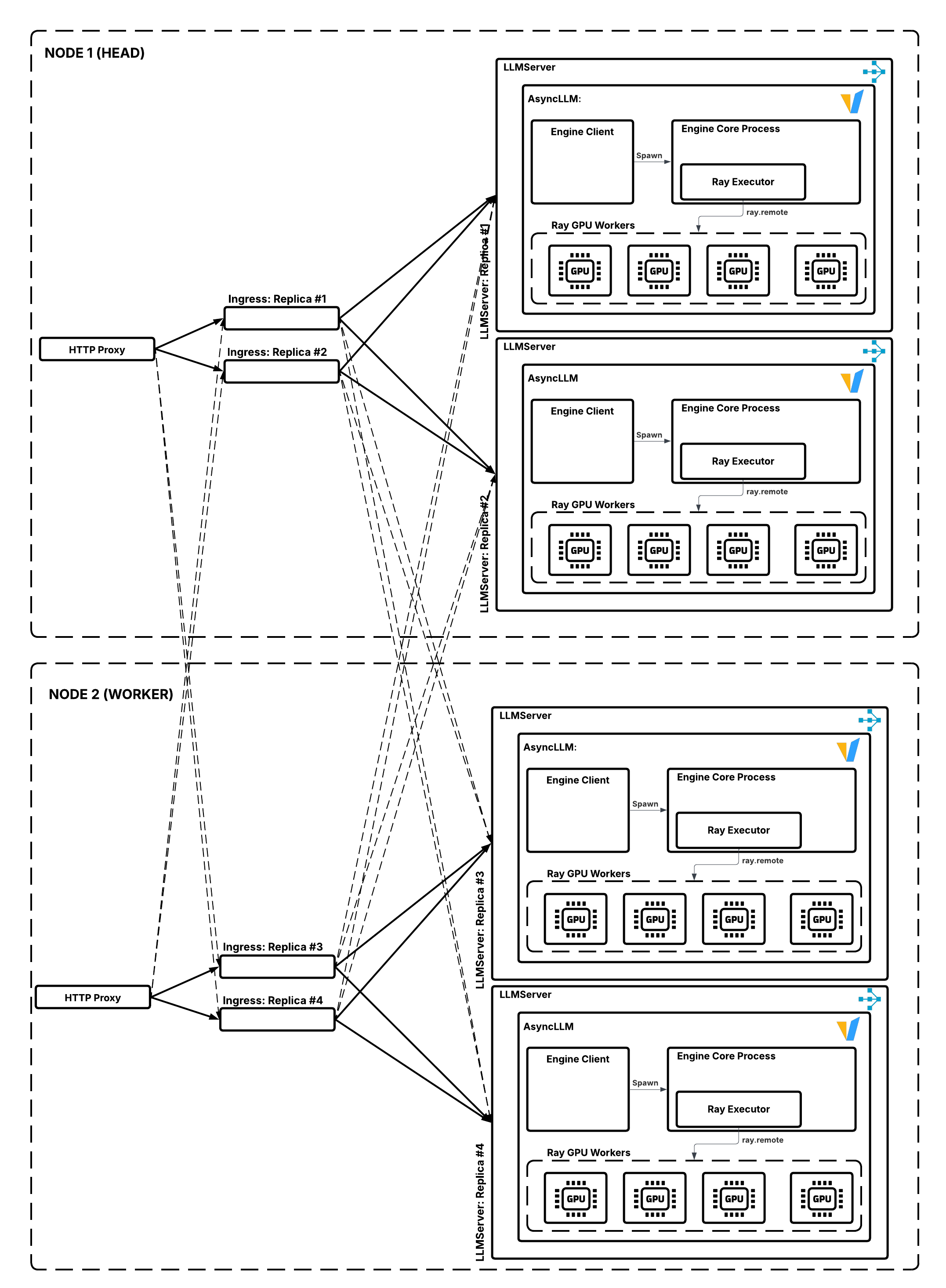
从入口到 LLMServer 副本的请求路由。实线表示首选的本地 RPC 调用;虚线表示当本地副本繁忙时可能发生的跨节点 RPC 调用。#
扩展注意事项#
入口与 LLMServer 的比例:在高并发下,入口事件循环可能会成为瓶颈。在这种情况下,增加入口副本的数量可以缓解 CPU 争用。我们建议入口副本的数量与 LLMServer 副本的数量至少保持 2:1 的比例。这种架构允许系统动态地扩展瓶颈组件。
自动缩放协调:为了在自动缩放期间保持适当的比例,请成比例地配置 target_ongoing_requests
分析您的 vLLM 配置,找到最大并发请求数(例如,64 个请求)。
选择入口与 LLMServer 的比例(例如,2:1)。
将 LLMServer 的
target_ongoing_requests设置为最大容量的 75% 左右(例如,48)。将入口的
target_ongoing_requests设置为维持比例(例如,24)。
架构模式#
Ray Serve LLM 支持多种部署模式,以适应不同的扩展场景
数据并行注意力模式#
创建多个推理引擎实例,它们并行处理请求,同时跨专家层进行协调,并将请求分片到注意力层。适用于为高吞吐量工作负载提供稀疏 MoE 模型。
何时使用:高请求量、kv-cache 受限、需要最大化吞吐量。
参见:数据并行注意力
预填充-解码分离#
分离预填充和解码阶段,以优化资源利用率并独立扩展每个阶段。
何时使用:预填充密集型工作负载,预填充和解码之间存在冲突,使用不同 GPU 类型进行成本优化。
参见:预填充-解码分离
自定义请求路由#
实现自定义路由逻辑,以实现特定的优化目标,如缓存局部性或会话亲和性。
何时使用:具有重复提示、基于会话的交互或特定路由要求的工作负载。
参见:请求路由
设计原则#
Ray Serve LLM 遵循以下关键设计原则
引擎无关:通过
LLMEngine协议支持多种推理引擎(vLLM、SGLang 等)。可组合模式:结合服务模式(数据并行注意力、预填充-解码、自定义路由)来实现复杂部署。
构建器模式:使用构建器以声明式方式构建复杂的部署图。
关注点分离:将基础设施逻辑(放置、扩展)与应用程序逻辑(路由、处理)分开。
基于协议的可扩展性:为引擎、服务器和入口定义清晰的协议,以实现自定义实现。