数据并行注意力#
数据并行注意力 (DP) 是一种服务模式,它创建多个推理引擎实例来并行处理请求。这种模式在与稀疏 MoE 模型的专家并行结合使用时最有用。在这种情况下,专家并行分布在多台机器上,而注意力 (QKV) 层则复制到各个 GPU 上,这为跨请求分片提供了机会。
在此服务模式中,引擎副本并非相互隔离。事实上,它们需要相互同步运行,才能同时服务大量请求。
架构概述#
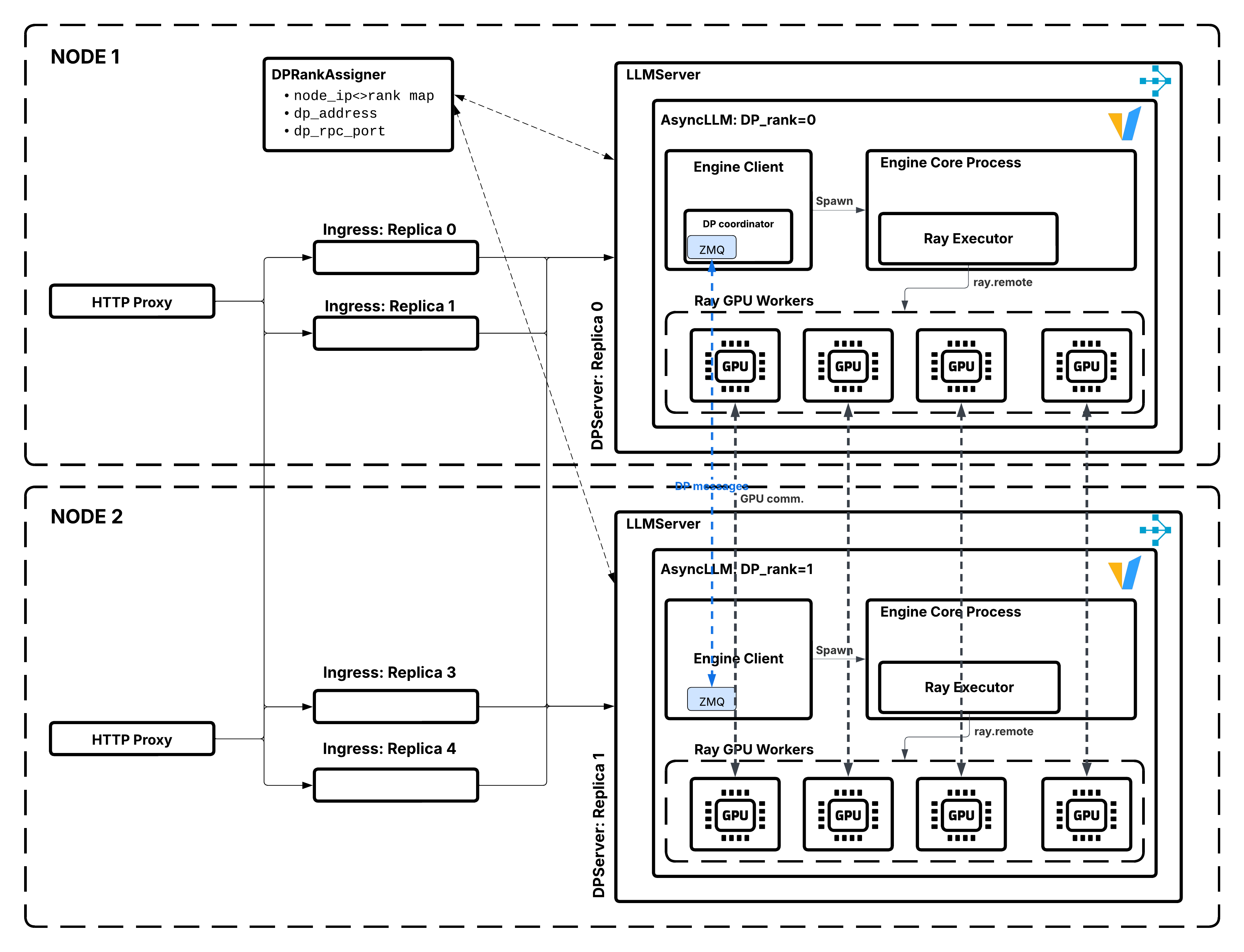
数据并行注意力架构,展示了 DPRankAssigner 协调多个 LLMServer 副本。#
在数据并行注意力服务中
系统会创建
dp_size个 LLM 服务器的副本。每个副本都运行一个独立的、具有相同模型的推理引擎。
请求通过 Ray Serve 的路由分布到各个副本。
所有副本作为一个整体协同工作。
何时使用 DP#
数据并行注意力服务在以下情况最有效:
大型稀疏 MoE 与 MLA:通过更有效地利用专家的稀疏性,可以达到更大的批量大小。MLA(多头潜在注意力)可减少 KV 缓存的内存需求。
需要高吞吐量:您需要同时处理许多请求。
KV 缓存受限:增加 KV 缓存容量可提高吞吐量,因此专家并行化可以有效地增加 KV 缓存的处理并发请求的能力。
何时不使用 DP#
考虑替代方案,当
低到中等吞吐量:如果您无法使 MoE 层饱和,请勿使用 DP。
非 MLA 注意力且具有足够的 TP:DP 最适合与 MLA(多头潜在注意力)结合使用,在这种情况下,KV 缓存无法沿头维度分片。对于具有 GQA(分组查询注意力)的模型,您可以使用 TP 来分片 KV 缓存,直到
TP_size <= num_kv_heads。超过这一点后,TP 需要复制 KV 缓存,这会浪费内存——DP 成为避免重复的更好选择。例如,对于 Qwen-235b,使用DP=2, TP=4, EP=8比DP=8, EP=8更有意义,因为您仍然可以在需要复制 KV 缓存之前使用 TP=4 进行分片。使用您的工作负载对这些配置进行基准测试,以确定最佳设置。非 MoE 模型:以这种复杂性为代价使用 DP 的主要原因是为了在解码过程中提高有效批量大小,以使专家饱和。
组件#
以下是 DP 部署的主要组成部分
DPServer#
DPServer 扩展了 LLMServer,加入了数据并行注意力的协调。以下伪代码展示了其结构。
from ray import serve
class DPServer(LLMServer):
"""LLM server with data parallel attention coordination."""
async def __init__(
self,
llm_config: LLMConfig,
rank_assigner_handle: DeploymentHandle,
dp_size: int,
**kwargs
):
self.rank_assigner = rank_assigner_handle
self.dp_size = dp_size
# Get assigned rank from coordinator and pass it to engine.
replica_id = serve.get_replica_context().replica_id
llm_config.rank = await self.rank_assigner.assign_rank.remote(replica_id)
# Call parent initialization
await super().__init__(llm_config, **kwargs)
关键职责
向 rank 分配协调器注册。
获取一个唯一的 rank(从 0 到
dp_size-1)。与其他副本协调以进行集体操作。
处理副本故障和重新注册。
DPRankAssigner#
DPRankAssigner 是一个单例协调器,负责管理数据并行注意力副本的 rank 分配。以下伪代码展示了其结构。
class DPRankAssigner:
"""Coordinator for data parallel attention rank assignment."""
def __init__(self, dp_size: int):
self.dp_size = dp_size
self.assigned_ranks: Set[int] = set()
self.rank_to_replica: Dict[int, str] = {}
self.lock = asyncio.Lock()
async def assign_rank(self, replica_id: str) -> int:
"""Assign a rank to a replica.
Returns:
int: Assigned rank (0 to dp_size-1)
"""
async with self.lock:
# Find first available rank
for rank in range(self.dp_size):
if rank not in self.assigned_ranks:
self.assigned_ranks.add(rank)
self.rank_to_replica[rank] = replica_id
return rank
async def release_rank(self, rank: int):
"""Release a rank when replica dies."""
async with self.lock:
self.assigned_ranks.discard(rank)
self.rank_to_replica.pop(rank, None)
关键职责
为副本分配唯一的 rank。
确保恰好有
dp_size个副本在服务。
请求流程#
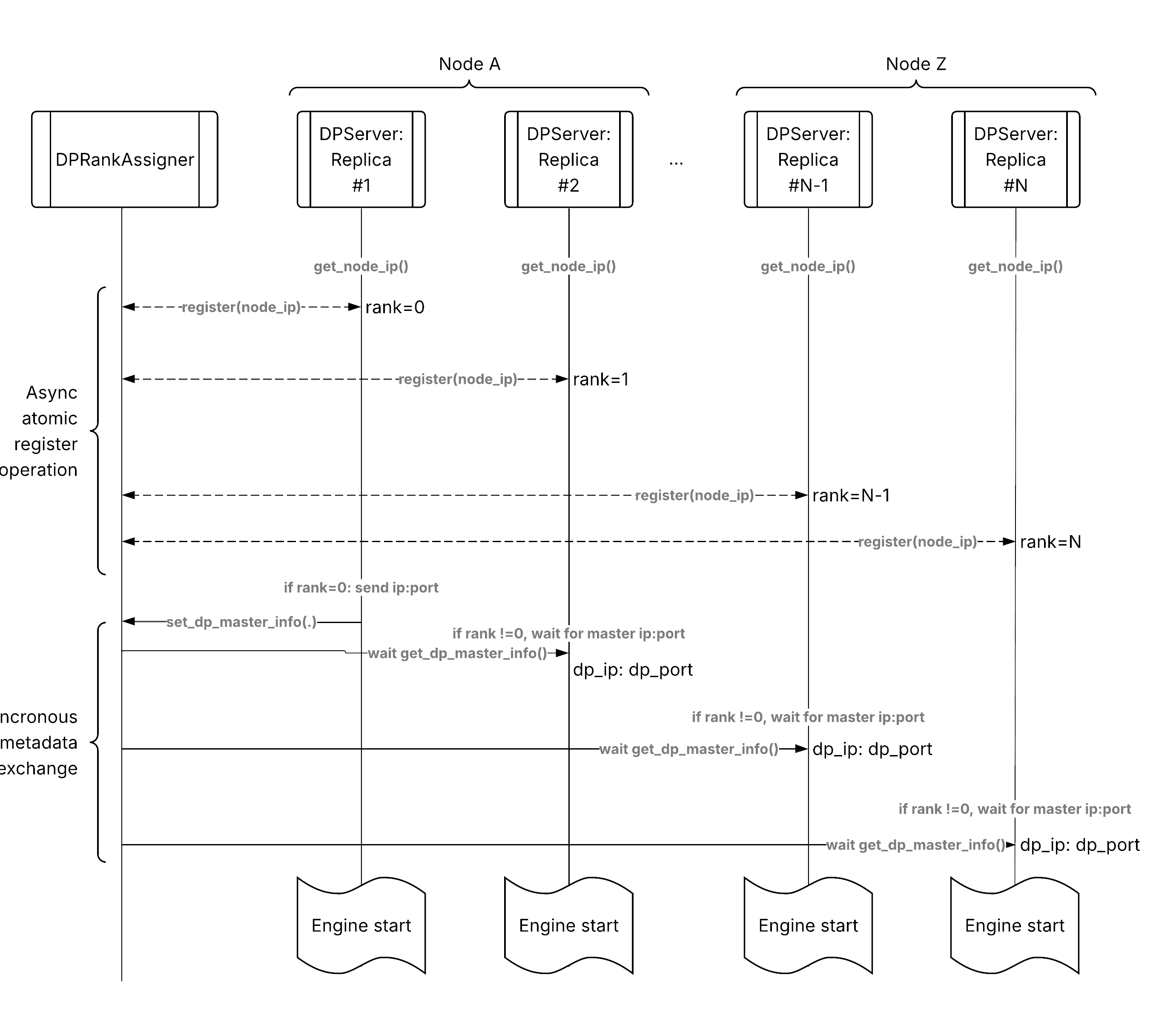
数据并行注意力请求流程,从客户端到分布式副本。#
以下是通过数据并行注意力部署的请求流程:
客户端请求:HTTP 请求到达入口。
入口路由:入口使用部署句柄调用 DPServer。
Ray Serve 路由:Ray Serve 的请求路由器选择一个副本。
默认:二选一(负载均衡)。
自定义:前缀感知、会话感知等。
副本处理:选定的 DPServer 副本处理请求。
引擎推理:vLLM 引擎生成响应。
流式响应:Token 流式返回给客户端。
与基本服务的关键区别在于,所有 dp_size 个副本都在相互协调工作,而不是孤立地工作。
扩展#
扩展行为#
数据并行注意力部署需要固定数量的副本,等于 dp_size,因为此模式不支持自动扩展。您必须将 num_replicas 设置为 dp_size,或者如果使用 autoscaling_config,则 min_replicas 和 max_replicas 都必须等于 dp_size。
设计注意事项#
协调开销#
DPRankAssigner 引入了极小的协调开销。
启动:每个副本进行一次 RPC 来获取其 rank。
运行时:请求处理期间没有协调开销。
单例 Actor 模式可确保启动时的一致性。
部署策略#
PACK 策略将每个副本的资源打包在一起。
单个副本的张量并行工作者尽可能打包在同一节点上。
不同的副本可以在不同的节点上。
这最大限度地减少了每个副本内部的节点间通信。
与其他模式结合#
DP + Prefill-decode 分离#
您可以在 prefill 和 decode 阶段运行数据并行注意力。
┌─────────────────────────────────────────────┐
│ OpenAiIngress │
└─────────────┬───────────────────────────────┘
│
▼
┌─────────────┐
│PDProxyServer│
└──┬───────┬──┘
│ │
┌─────┘ └─────┐
▼ ▼
┌──────────┐ ┌──────────┐
│ Prefill │ │ Decode │
│ DP-2 │ │ DP-4 │
│ │ │ │
│ Replica0 │ │ Replica0 │
│ Replica1 │ │ Replica1 │
└──────────┘ │ Replica2 │
│ Replica3 │
└──────────┘
另请参阅#
架构概述 - 高层架构概述
核心组件 - 核心组件和协议
Prefill-decode 分离 - Prefill-decode 分离架构
请求路由 - 请求路由架构