Data-Juicer 中的分布式数据处理#
Data-Juicer 支持基于 Ray 和阿里云 PAI 的大规模分布式数据处理。
通过专门的设计,几乎所有 Data-Juicer 在独立模式下实现的算子都可以在 Ray 分布式模式下无缝执行。Data-Juicer 团队持续针对大规模场景进行引擎特定优化,例如平衡文件数量和 worker 的数据子集分割策略,以及针对 Ray 和 Apache Arrow 的 JSON 文件流式 I/O 补丁。
作为参考,在 25 到 100 个阿里云节点上的实验表明,Ray 模式下的 Data-Juicer 可以在 6400 个 CPU 核上用 2 小时处理包含 700 亿样本的数据集,在 3200 个 CPU 核上用 0.45 小时处理包含 70 亿样本的数据集。此外,Ray 模式下基于 MinHash-LSH 的去重算子可以在 8 个节点共 1280 个 CPU 核上用 3 小时对 PB 级别的数据集进行去重。
更多细节请参阅论文 Data-Juicer 2.0: 面向基础模型的云规模自适应数据处理。
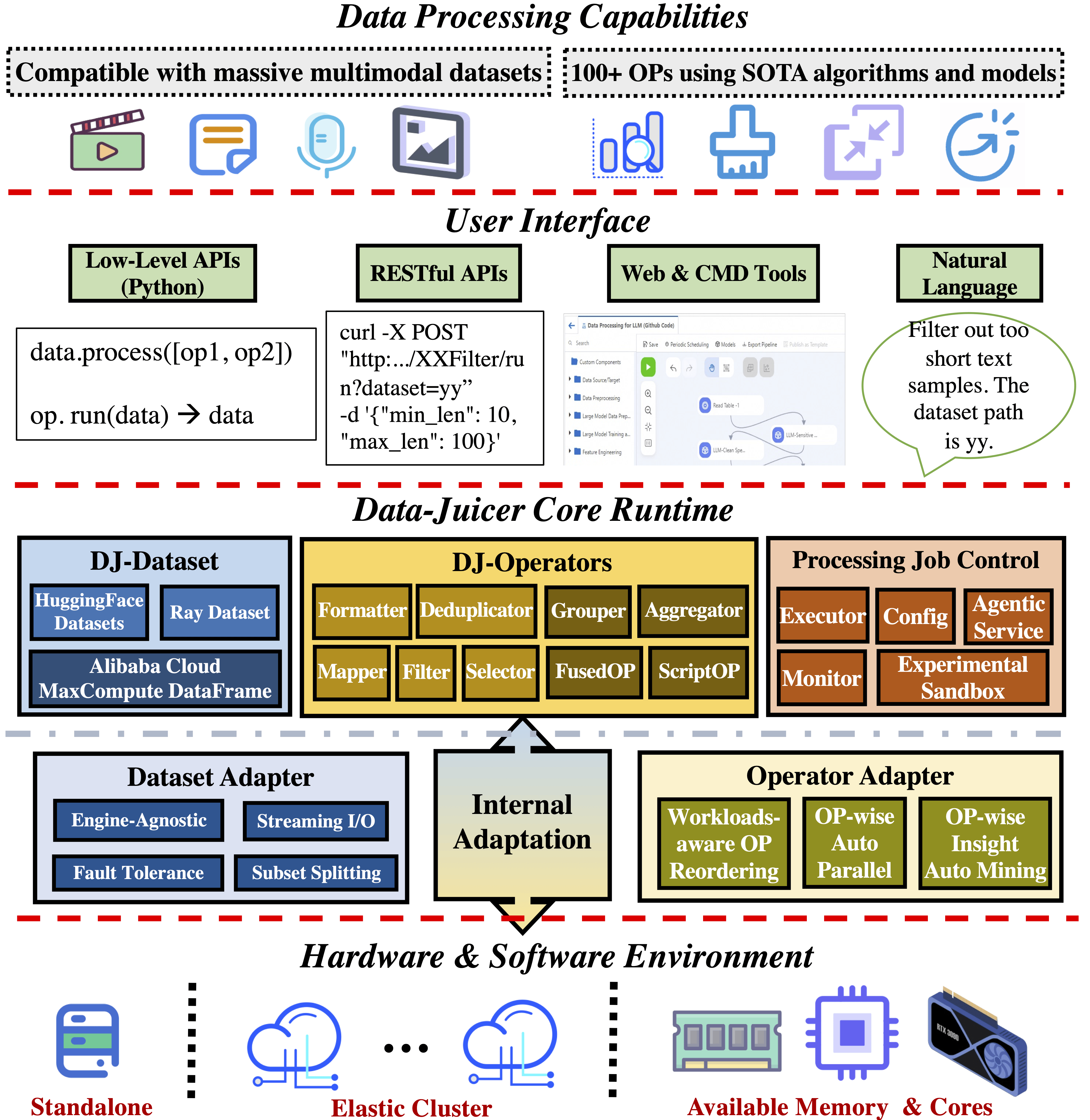
实现和优化#
Data-Juicer 中的 Ray 模式#
对于大多数 Data-Juicer 算子的实现,核心处理函数与引擎无关。算子之间的互操作性主要通过 RayDataset 和 RayExecutor 来管理,它们分别是基础类
DJDataset和BaseExecutor的子类,并且支持 Ray 任务 (Tasks) 和 Actor。例外是去重算子,它们在独立模式下难以扩展。这些算子的名称遵循
ray_xx_deduplicator的模式。
子集分割#
当集群拥有数万个节点但数据集文件很少时,Ray 会根据可用资源分割数据集文件并将块分发到所有节点,这会带来高昂的网络通信成本并降低 CPU 利用率。更多详细信息,请参阅 Ray 的 _autodetect_parallelism 函数 和 Ray 的输出块调优。
这种默认执行计划对于节点数量庞大的场景效率很低。为了优化此类情况下的性能,Data-Juicer 会提前自动将原始数据集分割成更小的文件,同时考虑 Ray 和 Arrow 的特性。当遇到此类性能问题时,你可以使用此功能或根据自己的偏好分割数据集。在这种自动分割策略中,单个文件大小约为 128MB,并且分割后的子文件数量应至少是集群中可用 CPU 核总数的两倍。
JSON 文件流式读取#
JSON 文件流式读取是基础模型数据处理中的常见需求,因为许多数据集采用 JSONL 格式且体积庞大。然而,Ray Datasets 当前的实现依赖于底层 Arrow 库(截至 Ray 版本 2.40 和 Arrow 版本 18.1.0),不支持 JSON 文件的流式读取。
为了解决原生不支持流式 JSON 数据的问题,Data-Juicer 团队开发了流式加载接口,并为 Apache Arrow 贡献了一个内部 补丁(仓库 PR)。该补丁有助于缓解内存溢出问题。有了这个补丁,Ray 模式下的 Data-Juicer 默认使用流式加载接口加载 JSON 文件。此外,已经支持 CSV 和 Parquet 文件的流式读取。
去重#
Data-Juicer 在 Ray 模式下提供了一个优化的基于 MinHash-LSH 的去重算子。它利用 Ray Actor 中的多进程 Union-Find 集合以及负载均衡的分布式算法 BTS 来完成等价类合并。该算子可以在 1280 个 CPU 核上用 3 小时对 PB 级别的数据集进行去重。Data-Juicer 团队的消融研究表明,与该去重算子的普通版本相比,针对 Ray 模式的专门优化带来了 2 到 3 倍的速度提升。
性能结果#
不同规模下的数据处理#
Data-Juicer 团队对包含数十亿样本的数据集进行了实验。他们准备了一个 56 万样本的多模态数据集,并通过不同的因子(1 倍到 125000 倍)进行扩展,创建了不同大小的数据集。实验结果如下图所示,展示了良好的可伸缩性。
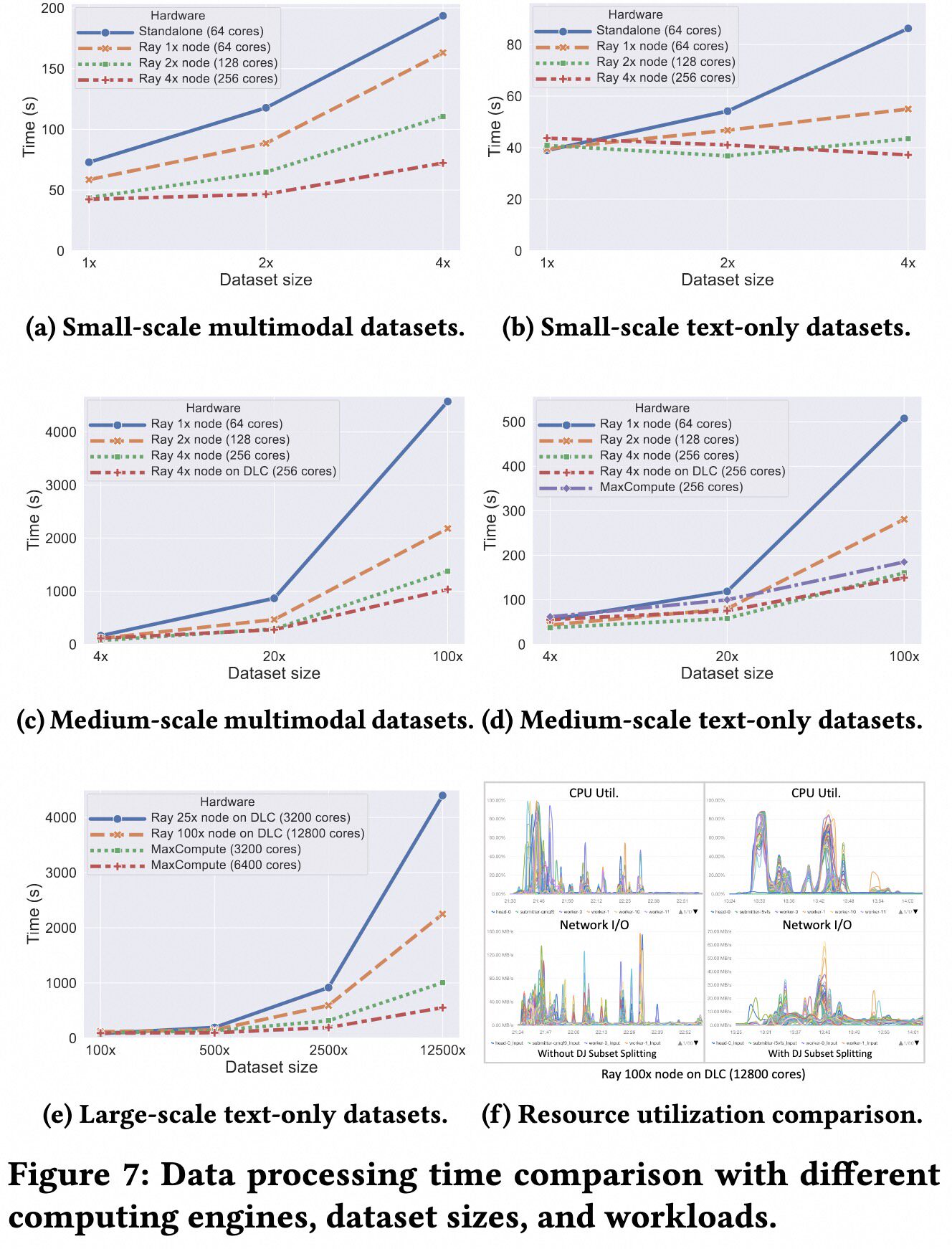
大规模数据集上的分布式去重#
Data-Juicer 团队在 200 GB、1 TB 和 5 TB 大小的数据集上测试了基于 MinHash 的 RayDeduplicator,使用了从 640 到 1280 个 CPU 核。如下表所示,当数据大小增加 5 倍时,处理时间增加了 4.02 倍到 5.62 倍。当 CPU 核数翻倍时,处理时间减少到原始时间的 58.9% 到 67.1%。
# CPU |
200 GB 时间 |
1 TB 时间 |
5 TB 时间 |
|---|---|---|---|
4 * 160 |
640 |
1280 |
11.13 分钟 |
8 * 160 |
50.83 分钟 |
285.43 分钟 |
7.47 分钟 |
30.08 分钟
168.10 分钟
pip install -v -e . # Install the minimal requirements of Data-Juicer
pip install -v -e ".[dist]" # Include dependencies on Ray and other distributed libraries
快速开始#
# Start a cluster as the head node
ray start --head
# (Optional) Connect to the cluster on other nodes/machines.
ray start --address='{head_ip}:6379'
开始之前,你应该安装 Data-Juicer 及其 dist 依赖
demos/process_on_ray
├── configs
│ ├── demo.yaml
│ └── dedup.yaml
└── data
├── demo-dataset.json
└── demo-dataset.jsonl
然后启动一个 Ray 集群(更多详情请参阅 Ray 文档)
Data-Juicer 在目录 demos/process_on_ray/ 中提供了简单的演示,其中包含两个配置文件和两个测试数据集。
重要提示: 如果你在多个节点上运行这些演示,你需要将演示数据集放到共享磁盘(例如,网络附加存储)上,并且通过修改配置文件的 dataset_path 和 export_path,也将结果数据集导出到该共享磁盘。
...
dataset_path: './demos/process_on_ray/data/demo-dataset.jsonl'
export_path: './outputs/demo/demo-processed'
executor_type: 'ray' # Set the executor type to "ray"
ray_address: 'auto' # Set an automatic Ray address
...
Ray 模式运行示例#
# Run the tool from source
python tools/process_data.py --config demos/process_on_ray/configs/demo.yaml
# Use the command-line tool
dj-process --config demos/process_on_ray/configs/demo.yaml
在 demo.yaml 配置文件中,它将执行器类型设置为“ray”并指定一个自动 Ray 地址。
运行演示以使用 12 个常规 OP 处理数据集
Data-Juicer 使用演示配置文件处理演示数据集,并将结果数据集导出到配置文件中由 export_path 参数指定的目录。
project_name: 'demo-dedup'
dataset_path: './demos/process_on_ray/data/'
export_path: './outputs/demo-dedup/demo-ray-bts-dedup-processed'
executor_type: 'ray' # Set the executor type to "ray"
ray_address: 'auto' # Set an automatic Ray address
# process schedule
# a list of several process operators with their arguments
process:
- ray_bts_minhash_deduplicator: # a distributed version of minhash deduplicator
tokenization: 'character'
分布式去重运行示例#
# Run the tool from source
python tools/process_data.py --config demos/process_on_ray/configs/dedup.yaml
# Use the command-line tool
dj-process --config demos/process_on_ray/configs/dedup.yaml
在 dedup.yaml 配置文件中,它将执行器类型设置为“ray”并指定一个自动 Ray 地址。并且它使用专门的分布式 MinHash 去重算子来对数据集进行去重。