存储和依赖项的最佳实践#
本文档包含关于在 Kubernetes 上部署 Ray 时设置存储和处理应用依赖项的建议。
当您在 Kubernetes 上设置 Ray 时,KubeRay 文档提供了关于如何配置 Operator 来执行和管理 Ray 集群生命周期的概览。然而,作为管理员,您可能仍然对实际用户工作流程有疑问。例如:
如何在 Ray 集群上分发或运行代码?
应该为工件设置哪种类型的存储系统?
如何处理应用的包依赖项?
这些问题的答案在开发和生产环境之间有所不同。下表总结了每种情况下的推荐设置:
交互式开发 |
生产 |
|
|---|---|---|
集群配置 |
KubeRay YAML |
KubeRay YAML |
代码 |
在头节点上运行驱动程序或 Jupyter notebook |
将代码打包到 Docker 镜像中 |
工件存储 |
设置 EFS |
设置 EFS |
包依赖项 |
安装到 NFS |
打包到 Docker 镜像中 |
表 1:开发和生产推荐设置对比表。
交互式开发#
为了给数据科学家和 ML 工程师提供交互式开发环境,我们建议以一种减少开发者上下文切换并缩短迭代时间的方式来设置代码、存储和依赖项。
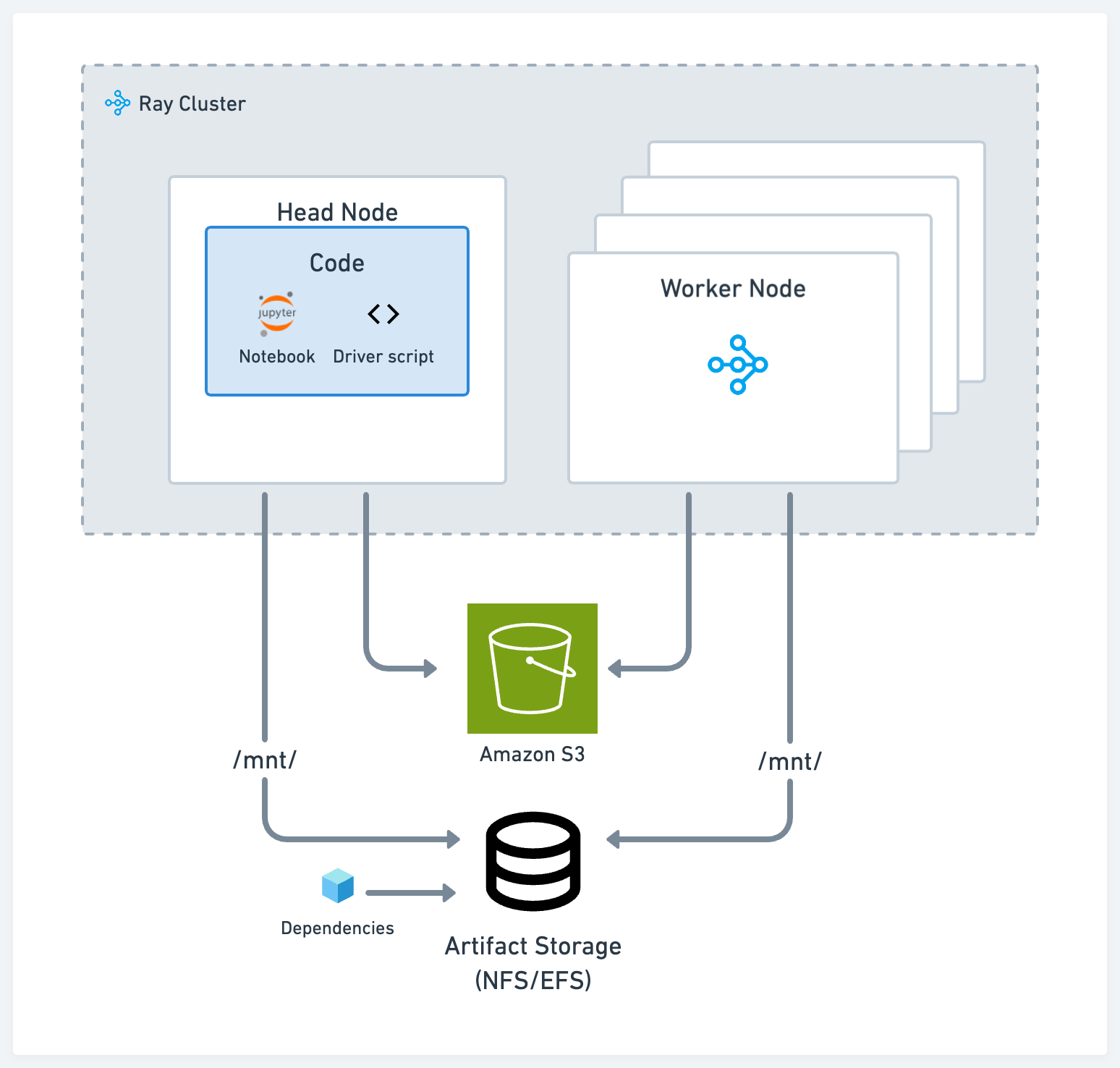
存储#
在开发过程中,根据您的用例,使用以下两种标准解决方案之一用于工件和日志存储:
符合 POSIX 标准的网络文件存储,例如网络文件系统 (NFS) 和弹性文件服务 (EFS):当您希望在不同节点之间以低延迟访问工件或依赖项时,此方法非常有用。例如,在不同 Ray 任务上训练的不同模型的实验日志。
云存储,例如 AWS Simple Storage Service (S3) 或 GCP Google Storage (GS):此方法对于需要高吞吐量访问的大型工件或数据集非常有用。
Ray 的 AI 库,如 Ray Data、Ray Train 和 Ray Tune,都具有开箱即用的功能,可以从云存储以及本地或网络存储读取和写入数据。
驱动脚本#
在集群的头节点上运行主脚本或驱动脚本。Ray Core 和库程序通常假定驱动程序在头节点上,并利用本地存储。例如,Ray Tune 默认在头节点上生成日志文件。
典型的工作流程可能如下所示:
在头节点上启动 Jupyter 服务器
SSH 到头节点并在那里运行驱动脚本或应用程序
使用 Ray Job Submission 客户端将代码从本地机器提交到集群
依赖项#
对于本地依赖项,例如,如果您在单体仓库中工作,或外部依赖项(如 pip 包),请使用以下选项之一:
将代码和安装包放到您的 NFS 上。好处是您可以快速地与代码库和依赖项的其余部分进行交互,而无需每次都将其发送到集群中。
使用 runtime env 和 Ray Job Submission Client,它可以从 S3 拉取代码或将代码从您的本地工作目录发送到远程集群。
将远程和本地依赖项打包到已发布的 Docker 镜像中供所有节点使用。请参阅自定义 Docker 镜像。此方法是将应用程序部署到 Kubernetes 的最常见方式,但也是摩擦力最大的选项。
生产环境#
生产环境的建议与标准的 Kubernetes 最佳实践一致。请参阅下图中的配置:
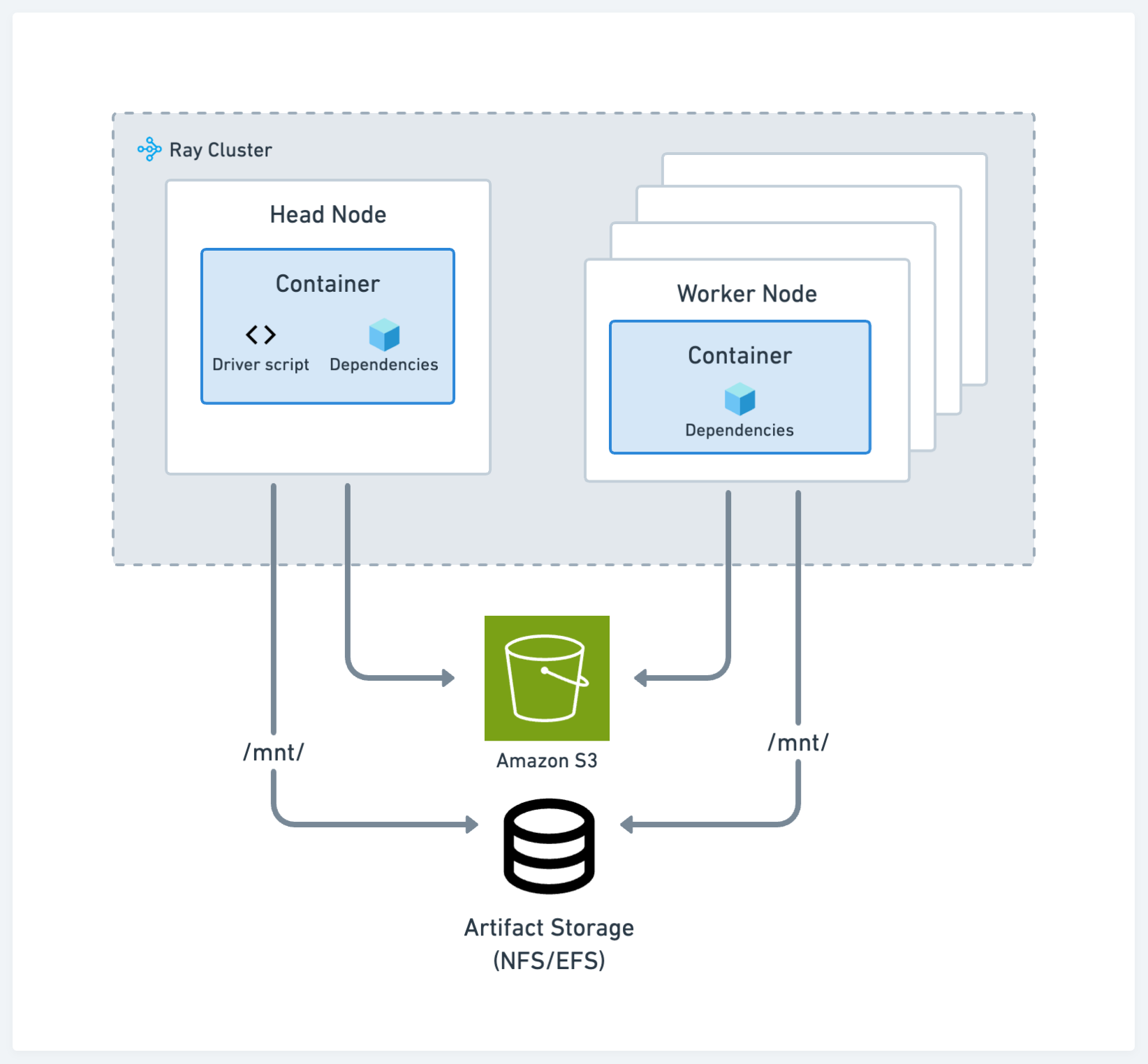
存储#
存储系统的选择在开发和生产环境之间保持一致。
代码和依赖项#
将您的代码、远程和本地依赖项打包到已发布的 Docker 镜像中供集群中的所有节点使用。此方法是将应用程序部署到 Kubernetes 的最常见方式。请参阅自定义 Docker 镜像。
使用云存储和 runtime env 是一个不太推荐的方法,因为它可能不像容器路径那样具有可复现性,但仍然可行。在这种情况下,除了指定运行应用程序所需的 pip 包外,还可以使用运行时环境选项从云存储下载包含代码和其他私有模块的 zip 文件。