Placement Group#
Placement Group 允许用户跨多个节点原子地预留资源组(即,协同调度)。然后可以使用它们来调度 Ray 任务和 Actor,使其紧密打包以实现本地性 (PACK),或分散 (SPREAD)。Placement Group 通常用于 Actor 的协同调度,但也支持任务。
以下是一些实际用例
分布式机器学习训练:分布式训练(例如,Ray Train 和 Ray Tune)使用 Placement Group API 来启用协同调度。在这些设置中,一个试验的所有资源必须同时可用。协同调度是实现深度学习训练全有或全无调度的关键技术。
分布式训练中的容错:Placement Group 可用于配置容错。在 Ray Tune 中,将单个试验的相关资源打包在一起可能是有益的,这样节点故障对试验数量的影响就会很小。在支持弹性训练的库(例如 XGBoost-Ray)中,将资源分散到多个节点有助于确保即使节点发生故障,训练也能继续进行。
关键概念#
Bundle#
一个 Bundle 是“资源”的集合。它可以是单个资源 {"CPU": 1},也可以是一组资源 {"CPU": 1, "GPU": 4}。Bundle 是 Placement Group 的预留单位。“调度 Bundle”意味着我们找到一个适合该 Bundle 的节点并预留该 Bundle 指定的资源。一个 Bundle 必须能够容纳在 Ray 集群上的单个节点中。例如,如果您只有一个 8 核 CPU 节点,而您有一个 Bundle 需要 {"CPU": 9},则此 Bundle 无法调度。
Placement Group#
一个 Placement Group 预留集群中的资源。预留的资源只能由使用 PlacementGroupSchedulingStrategy 的任务或 Actor 使用。
Placement Group 由一个 Bundle 列表表示。例如,
{"CPU": 1} * 4表示您想预留 4 个 1 CPU 的 Bundle(即,预留 4 个 CPU)。然后根据集群中节点上的 Placement 策略 来放置 Bundle。
创建 Placement Group 后,任务或 Actor 即可根据 Placement Group 甚至在单个 Bundle 上进行调度。
创建 Placement Group (预留资源)#
您可以使用 ray.util.placement_group() 创建 Placement Group。Placement Group 接受 Bundle 列表和 Placement 策略。请注意,每个 Bundle 必须能够容纳在 Ray 集群上的单个节点中。例如,如果您只有一个 8 核 CPU 节点,而您有一个 Bundle 需要 {"CPU": 9},则此 Bundle 无法调度。
Bundle 通过字典列表指定,例如 [{"CPU": 1}, {"CPU": 1, "GPU": 1}])。
CPU对应于ray.remote中使用的num_cpus。GPU对应于ray.remote中使用的num_gpus。memory对应于ray.remote中使用的memory其他资源对应于
ray.remote中使用的resources(例如,ray.init(resources={"disk": 1})可以有一个{"disk": 1}的 Bundle)。
Placement Group 调度是异步的。ray.util.placement_group 会立即返回。
from pprint import pprint
import time
# Import placement group APIs.
from ray.util.placement_group import (
placement_group,
placement_group_table,
remove_placement_group,
)
from ray.util.scheduling_strategies import PlacementGroupSchedulingStrategy
# Initialize Ray.
import ray
# Create a single node Ray cluster with 2 CPUs and 2 GPUs.
ray.init(num_cpus=2, num_gpus=2)
# Reserve a placement group of 1 bundle that reserves 1 CPU and 1 GPU.
pg = placement_group([{"CPU": 1, "GPU": 1}])
// Initialize Ray.
Ray.init();
// Construct a list of bundles.
Map<String, Double> bundle = ImmutableMap.of("CPU", 1.0);
List<Map<String, Double>> bundles = ImmutableList.of(bundle);
// Make a creation option with bundles and strategy.
PlacementGroupCreationOptions options =
new PlacementGroupCreationOptions.Builder()
.setBundles(bundles)
.setStrategy(PlacementStrategy.STRICT_SPREAD)
.build();
PlacementGroup pg = PlacementGroups.createPlacementGroup(options);
// Initialize Ray.
ray::Init();
// Construct a list of bundles.
std::vector<std::unordered_map<std::string, double>> bundles{{{"CPU", 1.0}}};
// Make a creation option with bundles and strategy.
ray::internal::PlacementGroupCreationOptions options{
false, "my_pg", bundles, ray::internal::PlacementStrategy::PACK};
ray::PlacementGroup pg = ray::CreatePlacementGroup(options);
您可以使用以下两种 API 之一阻塞程序,直到 Placement Group 就绪
# Wait until placement group is created.
ray.get(pg.ready(), timeout=10)
# You can also use ray.wait.
ready, unready = ray.wait([pg.ready()], timeout=10)
# You can look at placement group states using this API.
print(placement_group_table(pg))
// Wait for the placement group to be ready within the specified time(unit is seconds).
boolean ready = pg.wait(60);
Assert.assertTrue(ready);
// You can look at placement group states using this API.
List<PlacementGroup> allPlacementGroup = PlacementGroups.getAllPlacementGroups();
for (PlacementGroup group: allPlacementGroup) {
System.out.println(group);
}
// Wait for the placement group to be ready within the specified time(unit is seconds).
bool ready = pg.Wait(60);
assert(ready);
// You can look at placement group states using this API.
std::vector<ray::PlacementGroup> all_placement_group = ray::GetAllPlacementGroups();
for (const ray::PlacementGroup &group : all_placement_group) {
std::cout << group.GetName() << std::endl;
}
让我们验证 Placement Group 是否成功创建。
# This API is only available when you download Ray via `pip install "ray[default]"`
ray list placement-groups
======== List: 2023-04-07 01:15:05.682519 ========
Stats:
------------------------------
Total: 1
Table:
------------------------------
PLACEMENT_GROUP_ID NAME CREATOR_JOB_ID STATE
0 3cd6174711f47c14132155039c0501000000 01000000 CREATED
Placement Group 已成功创建。在 {"CPU": 2, "GPU": 2} 资源中,Placement Group 预留了 {"CPU": 1, "GPU": 1}。预留的资源只能在您使用 Placement Group 调度任务或 Actor 时使用。下图展示了 Placement Group 预留的“1 CPU 和 1 GPU”Bundle。
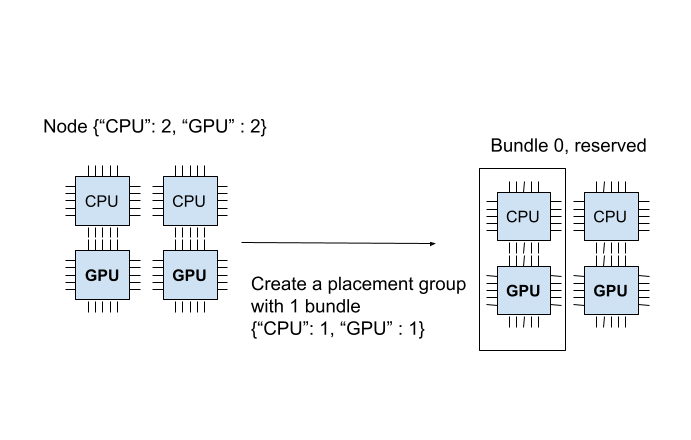
Placement Group 是原子创建的;如果任何 Bundle 无法放入当前任何节点,则整个 Placement Group 将不就绪,且不预留任何资源。为了说明这一点,让我们创建另一个需要 {"CPU":1}, {"GPU": 2}(2 个 Bundle)的 Placement Group。
# Cannot create this placement group because we
# cannot create a {"GPU": 2} bundle.
pending_pg = placement_group([{"CPU": 1}, {"GPU": 2}])
# This raises the timeout exception!
try:
ray.get(pending_pg.ready(), timeout=5)
except Exception as e:
print(
"Cannot create a placement group because "
"{'GPU': 2} bundle cannot be created."
)
print(e)
您可以验证新的 Placement Group 正在等待创建。
# This API is only available when you download Ray via `pip install "ray[default]"`
ray list placement-groups
======== List: 2023-04-07 01:16:23.733410 ========
Stats:
------------------------------
Total: 2
Table:
------------------------------
PLACEMENT_GROUP_ID NAME CREATOR_JOB_ID STATE
0 3cd6174711f47c14132155039c0501000000 01000000 CREATED
1 e1b043bebc751c3081bddc24834d01000000 01000000 PENDING <---- the new placement group.
您还可以使用 ray status CLI 命令验证 {"CPU": 1, "GPU": 2} Bundle 无法分配。
ray status
Resources
---------------------------------------------------------------
Usage:
0.0/2.0 CPU (0.0 used of 1.0 reserved in placement groups)
0.0/2.0 GPU (0.0 used of 1.0 reserved in placement groups)
0B/3.46GiB memory
0B/1.73GiB object_store_memory
Demands:
{'CPU': 1.0} * 1, {'GPU': 2.0} * 1 (PACK): 1+ pending placement groups <--- 1 placement group is pending creation.
当前集群有 {"CPU": 2, "GPU": 2}。我们已经创建了一个 {"CPU": 1, "GPU": 1} Bundle,所以集群中只剩下 {"CPU": 1, "GPU": 1}。如果我们创建 2 个 Bundle {"CPU": 1}, {"GPU": 2},我们可以成功创建第一个 Bundle,但无法调度第二个 Bundle。由于我们无法在集群上创建所有 Bundle,因此 Placement Group 未创建,包括 {"CPU": 1} Bundle。
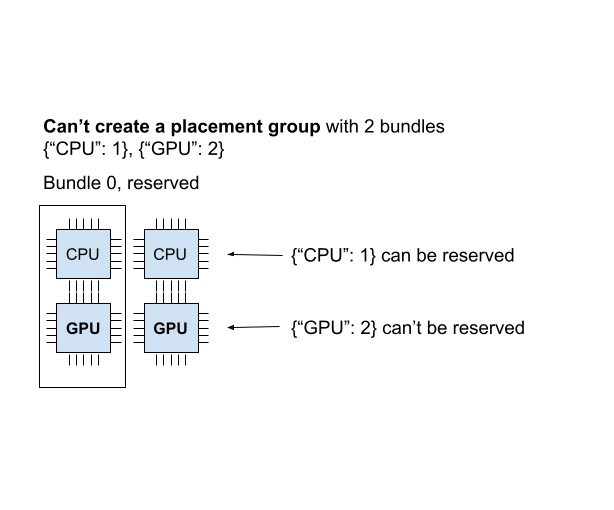
当 Placement Group 无法以任何方式调度时,称为“不可行(infeasible)”。想象您调度了一个 {"CPU": 4} Bundle,但您只有一个 2 核 CPU 的节点。您的集群无法创建此 Bundle。Ray 自动伸缩器了解 Placement Group,并会根据需要自动伸缩集群,以确保挂起中的组可以放置。
如果 Ray 自动伸缩器无法提供资源来调度 Placement Group,Ray 不会 打印有关不可行组以及使用这些组的任务和 Actor 的警告。您可以从 仪表板或状态 API 中观察 Placement Group 的调度状态。
将任务和 Actor 调度到 Placement Group (使用预留资源)#
在上一节中,我们创建了一个 Placement Group,该组从一个 2 核 CPU 和 2 个 GPU 节点预留了 {"CPU": 1, "GPU: 1"}。
现在让我们将一个 Actor 调度到该 Placement Group。您可以使用 options(scheduling_strategy=PlacementGroupSchedulingStrategy(...)) 将 Actor 或任务调度到 Placement Group。
@ray.remote(num_cpus=1)
class Actor:
def __init__(self):
pass
def ready(self):
pass
# Create an actor to a placement group.
actor = Actor.options(
scheduling_strategy=PlacementGroupSchedulingStrategy(
placement_group=pg,
)
).remote()
# Verify the actor is scheduled.
ray.get(actor.ready.remote(), timeout=10)
public static class Counter {
private int value;
public Counter(int initValue) {
this.value = initValue;
}
public int getValue() {
return value;
}
public static String ping() {
return "pong";
}
}
// Create GPU actors on a gpu bundle.
for (int index = 0; index < 1; index++) {
Ray.actor(Counter::new, 1)
.setPlacementGroup(pg, 0)
.remote();
}
class Counter {
public:
Counter(int init_value) : value(init_value){}
int GetValue() {return value;}
std::string Ping() {
return "pong";
}
private:
int value;
};
// Factory function of Counter class.
static Counter *CreateCounter() {
return new Counter();
};
RAY_REMOTE(&Counter::Ping, &Counter::GetValue, CreateCounter);
// Create GPU actors on a gpu bundle.
for (int index = 0; index < 1; index++) {
ray::Actor(CreateCounter)
.SetPlacementGroup(pg, 0)
.Remote(1);
}
注意
默认情况下,Ray Actor 在调度时需要 1 个逻辑 CPU,但调度后不占用任何 CPU 资源。换句话说,默认情况下,Actor 无法在零 CPU 节点上调度,但任意数量的 Actor 可以在任何非零 CPU 节点上运行。因此,在使用默认资源需求和 Placement Group 调度 Actor 时,创建 Placement Group 的 Bundle 必须至少包含 1 个 CPU(因为 Actor 调度时需要 1 个 CPU)。然而,Actor 创建后不消耗任何 Placement Group 资源。
为了避免意外,请始终明确为 Actor 指定资源需求。如果明确指定了资源,则调度时和执行时都需要这些资源。
Actor 现在已调度!一个 Bundle 可以被多个任务和 Actor 使用(即,Bundle 与任务(或 Actor)之间是一对多关系)。在这种情况下,由于 Actor 使用了 1 个 CPU,Bundle 中还剩余 1 个 GPU。您可以使用 CLI 命令 ray status 进行验证。您可以看到 1 个 CPU 被 Placement Group 预留,并且使用了 1.0(由我们创建的 Actor 使用)。
ray status
Resources
---------------------------------------------------------------
Usage:
1.0/2.0 CPU (1.0 used of 1.0 reserved in placement groups) <---
0.0/2.0 GPU (0.0 used of 1.0 reserved in placement groups)
0B/4.29GiB memory
0B/2.00GiB object_store_memory
Demands:
(no resource demands)
您还可以使用 ray list actors 验证 Actor 已创建。
# This API is only available when you download Ray via `pip install "ray[default]"`
ray list actors --detail
- actor_id: b5c990f135a7b32bfbb05e1701000000
class_name: Actor
death_cause: null
is_detached: false
job_id: '01000000'
name: ''
node_id: b552ca3009081c9de857a31e529d248ba051a4d3aeece7135dde8427
pid: 8795
placement_group_id: d2e660ac256db230dbe516127c4a01000000 <------
ray_namespace: e5b19111-306c-4cd8-9e4f-4b13d42dff86
repr_name: ''
required_resources:
CPU_group_d2e660ac256db230dbe516127c4a01000000: 1.0
serialized_runtime_env: '{}'
state: ALIVE
由于还剩余 1 个 GPU,让我们创建一个需要 1 个 GPU 的新 Actor。这次,我们还指定了 placement_group_bundle_index。Placement Group 中的每个 Bundle 都有一个“索引”。例如,包含 2 个 Bundle [{"CPU": 1}, {"GPU": 1}] 的 Placement Group,索引 0 的 Bundle 是 {"CPU": 1},索引 1 的 Bundle 是 {"GPU": 1}。由于我们只有一个 Bundle,所以只有索引 0。如果您不指定 Bundle,Actor(或任务)将调度到具有未分配预留资源的随机 Bundle 上。
@ray.remote(num_cpus=0, num_gpus=1)
class Actor:
def __init__(self):
pass
def ready(self):
pass
# Create a GPU actor on the first bundle of index 0.
actor2 = Actor.options(
scheduling_strategy=PlacementGroupSchedulingStrategy(
placement_group=pg,
placement_group_bundle_index=0,
)
).remote()
# Verify that the GPU actor is scheduled.
ray.get(actor2.ready.remote(), timeout=10)
我们成功调度了 GPU Actor!下图描述了调度到 Placement Group 中的 2 个 Actor。
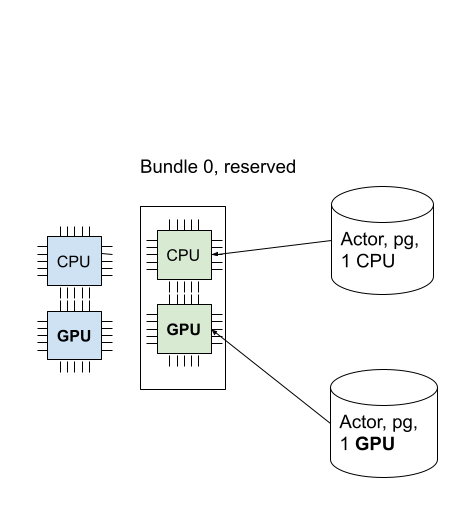
您还可以使用 ray status 命令验证预留资源是否已全部使用。
ray status
Resources
---------------------------------------------------------------
Usage:
1.0/2.0 CPU (1.0 used of 1.0 reserved in placement groups)
1.0/2.0 GPU (1.0 used of 1.0 reserved in placement groups) <----
0B/4.29GiB memory
0B/2.00GiB object_store_memory
Placement 策略#
Placement Group 提供的功能之一是为 Bundle 之间添加 Placement 约束。
例如,您可能希望将 Bundle 打包到同一节点上,或者尽可能分散到多个节点上。您可以通过 strategy 参数指定策略。这样,您可以确保您的 Actor 和任务可以根据某些 Placement 约束进行调度。
下面的示例创建了一个包含 2 个 Bundle 并使用 PACK 策略的 Placement Group;两个 Bundle 都必须在同一节点中创建。请注意,这是一个软策略。如果 Bundle 无法打包到单个节点中,它们将被分散到其他节点。如果您想避免这个问题,可以使用 STRICT_PACK 策略,如果 Placement 要求无法满足,这些策略将无法创建 Placement Group。
# Reserve a placement group of 2 bundles
# that have to be packed on the same node.
pg = placement_group([{"CPU": 1}, {"GPU": 1}], strategy="PACK")
下图演示了 PACK 策略。其中三个 {"CPU": 2} Bundle 位于同一节点中。
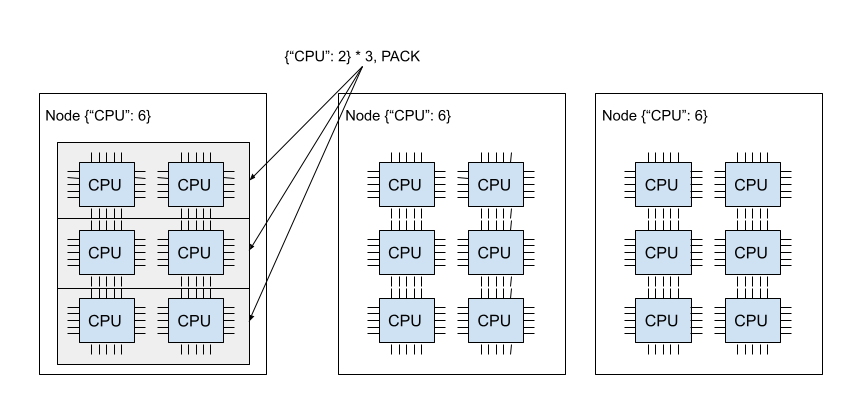
下图演示了 SPREAD 策略。三个 {"CPU": 2} Bundle 各自位于三个不同的节点中。
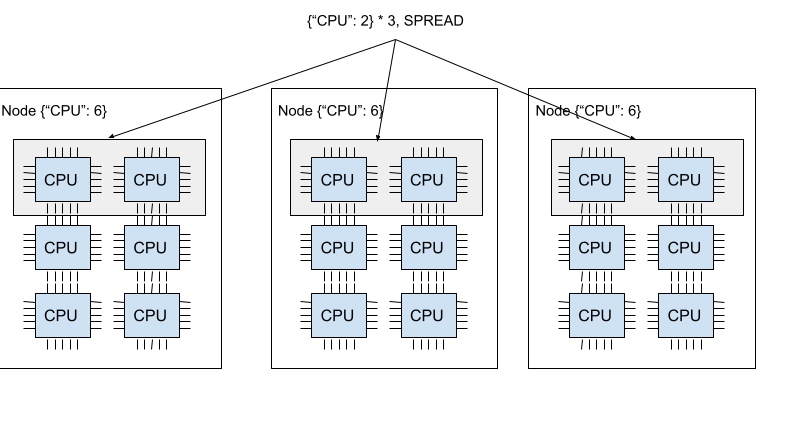
Ray 支持四种 Placement Group 策略。默认的调度策略是 PACK。
STRICT_PACK
所有 Bundle 都必须放置在集群上的单个节点中。当您想最大化本地性时使用此策略。
PACK
所有提供的 Bundle 在尽力而为的基础上打包到单个节点上。如果严格打包不可行(即,某些 Bundle 不适合该节点),Bundle 可以放置在其他节点上。
STRICT_SPREAD
每个 Bundle 必须调度在单独的节点中。
SPREAD
每个 Bundle 在尽力而为的基础上分散到单独的节点上。如果严格分散不可行,Bundle 可以放置在重叠的节点上。
移除 Placement Group (释放预留资源)#
默认情况下,Placement Group 的生命周期限定于创建 Placement Group 的驱动程序(除非您将其设置为 detached placement group)。当 Placement Group 从 detached actor 创建时,生命周期限定于该 detached actor。在 Ray 中,驱动程序是调用 ray.init 的 Python 脚本。
创建 Placement Group 的驱动程序或 detached actor 退出时,Placement Group 的预留资源 (Bundle) 会自动释放。要手动释放预留资源,请使用 remove_placement_group API 移除 Placement Group(这也是一个异步 API)。
注意
当您移除 Placement Group 时,仍然使用预留资源的 Actor 或任务将被强制终止。
# This API is asynchronous.
remove_placement_group(pg)
# Wait until placement group is killed.
time.sleep(1)
# Check that the placement group has died.
pprint(placement_group_table(pg))
"""
{'bundles': {0: {'GPU': 1.0}, 1: {'CPU': 1.0}},
'name': 'unnamed_group',
'placement_group_id': '40816b6ad474a6942b0edb45809b39c3',
'state': 'REMOVED',
'strategy': 'PACK'}
"""
PlacementGroups.removePlacementGroup(placementGroup.getId());
PlacementGroup removedPlacementGroup = PlacementGroups.getPlacementGroup(placementGroup.getId());
Assert.assertEquals(removedPlacementGroup.getState(), PlacementGroupState.REMOVED);
ray::RemovePlacementGroup(placement_group.GetID());
ray::PlacementGroup removed_placement_group = ray::GetPlacementGroup(placement_group.GetID());
assert(removed_placement_group.GetState(), ray::PlacementGroupState::REMOVED);
观察和调试 Placement Group#
Ray 提供了几个有用的工具来检查 Placement Group 的状态和资源使用情况。
Ray Status 是一个 CLI 工具,用于查看 Placement Group 的资源使用情况和调度资源需求。
Ray Dashboard 是一个 UI 工具,用于检查 Placement Group 的状态。
Ray State API 是一个 CLI,用于检查 Placement Group 的状态。
CLI 命令 ray status 提供集群的自动伸缩状态。它提供未调度 Placement Group 的“资源需求”以及资源预留状态。
Resources
---------------------------------------------------------------
Usage:
1.0/2.0 CPU (1.0 used of 1.0 reserved in placement groups)
0.0/2.0 GPU (0.0 used of 1.0 reserved in placement groups)
0B/4.29GiB memory
0B/2.00GiB object_store_memory
前提供了 Placement Group 表,显示 Placement Group 的调度状态和元数据。仪表板作业视图
注意
仅当使用 pip install "ray[default]" 安装 Ray 时,Ray 仪表板才可用。
Ray 状态 API 是一个 CLI 工具,用于检查 Ray 资源(任务、Actor、Placement Group 等)的状态。
ray list placement-groups 提供 Placement Group 的元数据和调度状态。ray list placement-groups --detail 提供更详细的统计信息和调度状态。
注意
仅当使用 pip install "ray[default]" 安装 Ray 时,State API 才可用
检查 Placement Group 调度状态#
使用上述工具,您可以查看 Placement Group 的状态。状态定义在以下文件中指定
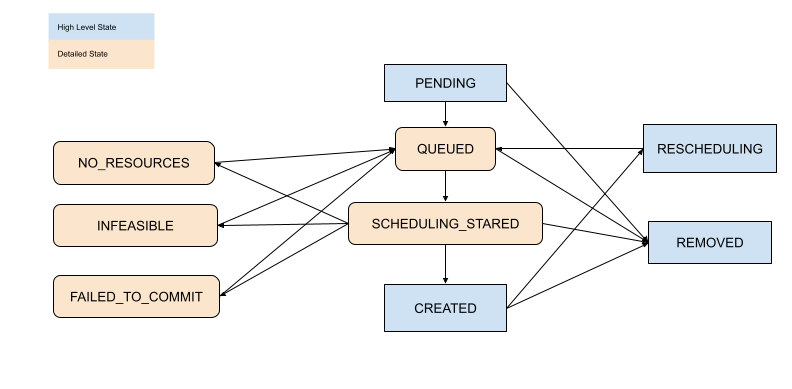
[高级] 子任务和 Actor#
默认情况下,子 Actor 和任务不共享父级使用的 Placement Group。要自动将子 Actor 或任务调度到同一 Placement Group,请将 placement_group_capture_child_tasks 设置为 True。
import ray
from ray.util.placement_group import placement_group
from ray.util.scheduling_strategies import PlacementGroupSchedulingStrategy
ray.init(num_cpus=2)
# Create a placement group.
pg = placement_group([{"CPU": 2}])
ray.get(pg.ready())
@ray.remote(num_cpus=1)
def child():
import time
time.sleep(5)
@ray.remote(num_cpus=1)
def parent():
# The child task is scheduled to the same placement group as its parent,
# although it didn't specify the PlacementGroupSchedulingStrategy.
ray.get(child.remote())
# Since the child and parent use 1 CPU each, the placement group
# bundle {"CPU": 2} is fully occupied.
ray.get(
parent.options(
scheduling_strategy=PlacementGroupSchedulingStrategy(
placement_group=pg, placement_group_capture_child_tasks=True
)
).remote()
)
Java API 尚未实现此功能。
当 placement_group_capture_child_tasks 为 True,但您不想将子任务和 Actor 调度到同一 Placement Group 时,请指定 PlacementGroupSchedulingStrategy(placement_group=None)。
@ray.remote
def parent():
# In this case, the child task isn't
# scheduled with the parent's placement group.
ray.get(
child.options(
scheduling_strategy=PlacementGroupSchedulingStrategy(placement_group=None)
).remote()
)
# This times out because we cannot schedule the child task.
# The cluster has {"CPU": 2}, and both of them are reserved by
# the placement group with a bundle {"CPU": 2}. Since the child shouldn't
# be scheduled within this placement group, it cannot be scheduled because
# there's no available CPU resources.
try:
ray.get(
parent.options(
scheduling_strategy=PlacementGroupSchedulingStrategy(
placement_group=pg, placement_group_capture_child_tasks=True
)
).remote(),
timeout=5,
)
except Exception as e:
print("Couldn't create a child task!")
print(e)
警告
给定 Actor 的 placement_group_capture_child_tasks 值不会继承自其父级。如果您正在创建深度大于 1 的嵌套 Actor 并且它们都应使用同一 Placement Group,则应为每个 Actor 显式设置 placement_group_capture_child_tasks。
[高级] 命名 Placement Group#
在 命名空间 中,您可以为 Placement Group 命名。只要作业在同一命名空间内,您就可以使用 Placement Group 的名称从 Ray 集群中的任何作业中检索该 Placement Group。如果您无法直接将 Placement Group 句柄传递给需要它的 Actor 或任务,或者如果您正在尝试访问由另一个驱动程序启动的 Placement Group,则此功能非常有用。
如果 Placement Group 的生命周期不是 detached,则原始创建作业完成后,Placement Group 将被销毁。您可以通过使用 detached placement group 来避免这种情况
请注意,此功能要求您指定与其关联的 命名空间,否则您将无法跨作业检索 Placement Group。
# first_driver.py
# Create a placement group with a unique name within a namespace.
# Start Ray or connect to a Ray cluster using: ray.init(namespace="pg_namespace")
pg = placement_group([{"CPU": 1}], name="pg_name")
ray.get(pg.ready())
# second_driver.py
# Retrieve a placement group with a unique name within a namespace.
# Start Ray or connect to a Ray cluster using: ray.init(namespace="pg_namespace")
pg = ray.util.get_placement_group("pg_name")
// Create a placement group with a unique name.
Map<String, Double> bundle = ImmutableMap.of("CPU", 1.0);
List<Map<String, Double>> bundles = ImmutableList.of(bundle);
PlacementGroupCreationOptions options =
new PlacementGroupCreationOptions.Builder()
.setBundles(bundles)
.setStrategy(PlacementStrategy.STRICT_SPREAD)
.setName("global_name")
.build();
PlacementGroup pg = PlacementGroups.createPlacementGroup(options);
pg.wait(60);
...
// Retrieve the placement group later somewhere.
PlacementGroup group = PlacementGroups.getPlacementGroup("global_name");
Assert.assertNotNull(group);
// Create a placement group with a globally unique name.
std::vector<std::unordered_map<std::string, double>> bundles{{{"CPU", 1.0}}};
ray::PlacementGroupCreationOptions options{
true/*global*/, "global_name", bundles, ray::PlacementStrategy::STRICT_SPREAD};
ray::PlacementGroup pg = ray::CreatePlacementGroup(options);
pg.Wait(60);
...
// Retrieve the placement group later somewhere.
ray::PlacementGroup group = ray::GetGlobalPlacementGroup("global_name");
assert(!group.Empty());
我们还在 C++ 中支持非全局命名 Placement Group,这意味着 Placement Group 名称仅在作业内部有效,无法从其他作业访问。
// Create a placement group with a job-scope-unique name.
std::vector<std::unordered_map<std::string, double>> bundles{{{"CPU", 1.0}}};
ray::PlacementGroupCreationOptions options{
false/*non-global*/, "non_global_name", bundles, ray::PlacementStrategy::STRICT_SPREAD};
ray::PlacementGroup pg = ray::CreatePlacementGroup(options);
pg.Wait(60);
...
// Retrieve the placement group later somewhere in the same job.
ray::PlacementGroup group = ray::GetPlacementGroup("non_global_name");
assert(!group.Empty());
[高级] Detached Placement Group#
默认情况下,Placement Group 的生命周期属于驱动程序和 Actor。
如果 Placement Group 由驱动程序创建,则驱动程序终止时它将被销毁。
如果它由 detached actor 创建,则当该 detached actor 被终止时,它也会被终止。
要使 Placement Group 无论其作业或 detached actor 如何都保持活动状态,请指定 lifetime="detached"。例如
# driver_1.py
# Create a detached placement group that survives even after
# the job terminates.
pg = placement_group([{"CPU": 1}], lifetime="detached", name="global_name")
ray.get(pg.ready())
Java API 尚未实现 lifetime 参数。
让我们终止当前脚本并启动一个新的 Python 脚本。调用 ray list placement-groups,您可以看到 Placement Group 未被移除。
请注意,lifetime 选项与名称是解耦的。如果我们只指定了名称而未指定 lifetime="detached",则只有当原始驱动程序仍在运行时才能检索到 Placement Group。建议在创建 detached placement group 时始终指定名称。
[高级] 容错#
在故障节点上重新调度 Bundle#
如果包含 Placement Group 部分 Bundle 的节点发生故障,GCS 会将所有 Bundle 重新调度到不同的节点上(即,我们再次尝试预留资源)。这意味着 Placement Group 的初始创建是“原子性的”,但一旦创建,可能会出现部分 Placement Group。重新调度 Bundle 比其他 Placement Group 调度的优先级更高。
为部分丢失的 Bundle 提供资源#
如果没有足够的资源来调度部分丢失的 Bundle,Placement Group 会等待,假设 Ray 自动伸缩器会启动新节点来满足资源需求。如果无法提供额外资源(例如,您不使用自动伸缩器或自动伸缩器达到资源限制),Placement Group 将无限期地保持部分创建状态。
使用 Bundle 的 Actor 和任务的容错#
使用 Bundle(预留资源)的 Actor 和任务在 Bundle 恢复后将根据其 容错策略 进行重新调度。