处理故障和节点抢占#
重要
本用户指南介绍了如何通过启用环境变量 RAY_TRAIN_V2_ENABLED=1 来配置从 Ray 2.43 开始提供的全新 Ray Train V2 的容错功能。本用户指南假设已启用此环境变量。
有关弃用和迁移的信息,请参见此处。
Ray Train 在三个级别提供容错功能
工作进程容错处理一个或多个 Train 工作进程在执行用户定义训练函数时发生的错误。
工作节点容错处理训练期间可能发生的节点故障。
Job 驱动器容错处理 Ray Train 驱动进程崩溃,以及训练需要再次启动(可能从新集群启动)的情况。
本用户指南介绍如何配置和使用这些容错机制。
工作进程和节点容错#
工作进程故障是指训练工作进程的用户定义训练函数中发生的错误,例如 GPU 内存不足 (OOM) 错误、云存储访问错误或其他运行时错误。
节点故障是指导致整个节点崩溃的错误,包括节点抢占、OOM、网络分区或其他硬件故障。本节介绍工作节点故障。主节点故障的恢复将在下一节讨论。
Ray Train 可以配置为自动从工作进程和工作节点故障中恢复。检测到故障后,所有工作进程将被关闭,必要时会添加新节点,并启动一组新的工作进程。重新启动的训练工作进程可以通过加载最新的检查点来恢复训练。
为了在恢复时保留进度,您的训练函数应实现保存和加载检查点的逻辑。否则,训练将从头开始。
从工作进程或节点故障中每次恢复都被视为一次重试。重试次数可以通过传递给 Trainer 的 RunConfig 中设置的 FailureConfig 参数的 max_failures 属性进行配置。默认情况下,工作进程容错被禁用,max_failures=0。
import ray.train
# Tries to recover a run up to this many times.
failure_config = ray.train.FailureConfig(max_failures=2)
# No limit on the number of retries.
failure_config = ray.train.FailureConfig(max_failures=-1)
这是一个启用了工作进程容错的 Torch 训练脚本示例,如下所示:
import tempfile
import uuid
import ray.train
import ray.train.torch
def train_fn_per_worker(train_loop_config: dict):
# [1] Train worker restoration logic.
checkpoint = ray.train.get_checkpoint()
if checkpoint:
with checkpoint.as_directory() as temp_checkpoint_dir:
# model.load_state_dict(torch.load(...))
...
# [2] Checkpoint saving and reporting logic.
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
# torch.save(...)
ray.train.report(
{"loss": 0.1},
checkpoint=ray.train.Checkpoint.from_directory(temp_checkpoint_dir),
)
trainer = ray.train.torch.TorchTrainer(
train_fn_per_worker,
scaling_config=ray.train.ScalingConfig(num_workers=4),
run_config=ray.train.RunConfig(
# (If multi-node, configure S3 / NFS as the storage path.)
# storage_path="s3://...",
name=f"train_run-{uuid.uuid4().hex}",
# [3] Enable worker-level fault tolerance to gracefully handle
# Train worker failures.
failure_config=ray.train.FailureConfig(max_failures=3),
),
)
trainer.fit()
将恢复哪个检查点?#
Ray Train 会使用报告给 Ray Train 的最新可用检查点填充ray.train.get_checkpoint()。此方法返回的Checkpoint对象具有 as_directory() 和 to_directory() 方法,用于将检查点从 RunConfig(storage_path) 下载到本地磁盘。
注意
as_directory() 和 to_directory() 每个节点只会下载一次检查点,即使节点上有多个工作进程也是如此。工作进程在本地磁盘上共享同一个检查点目录。
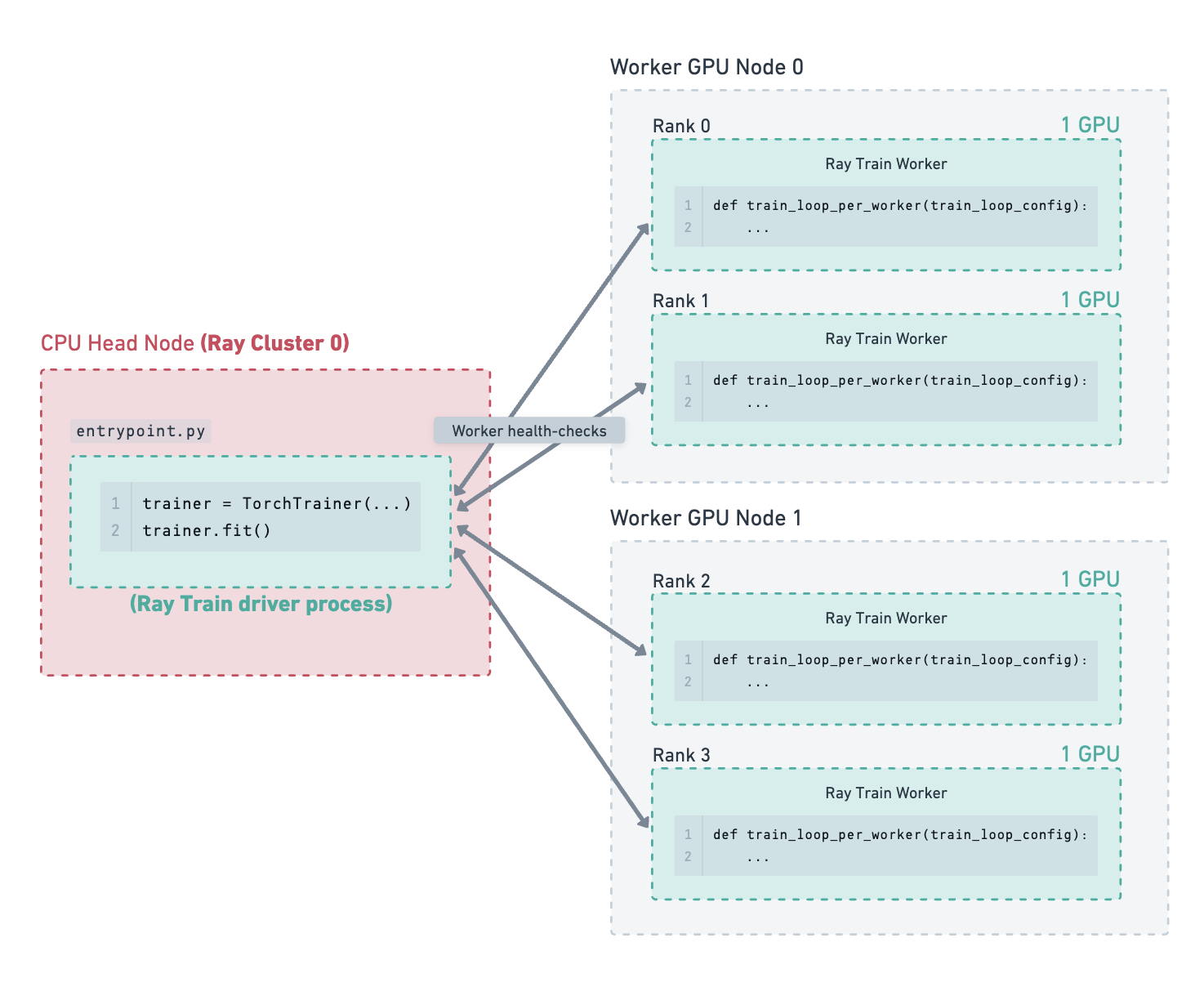
图示示例#
考虑以下示例:一个集群包含一个 CPU 主节点和 2 个 GPU 工作节点。在这 2 个工作节点上运行着 4 个 GPU 训练工作进程。存储路径已配置为使用云存储,检查点就保存在那里。
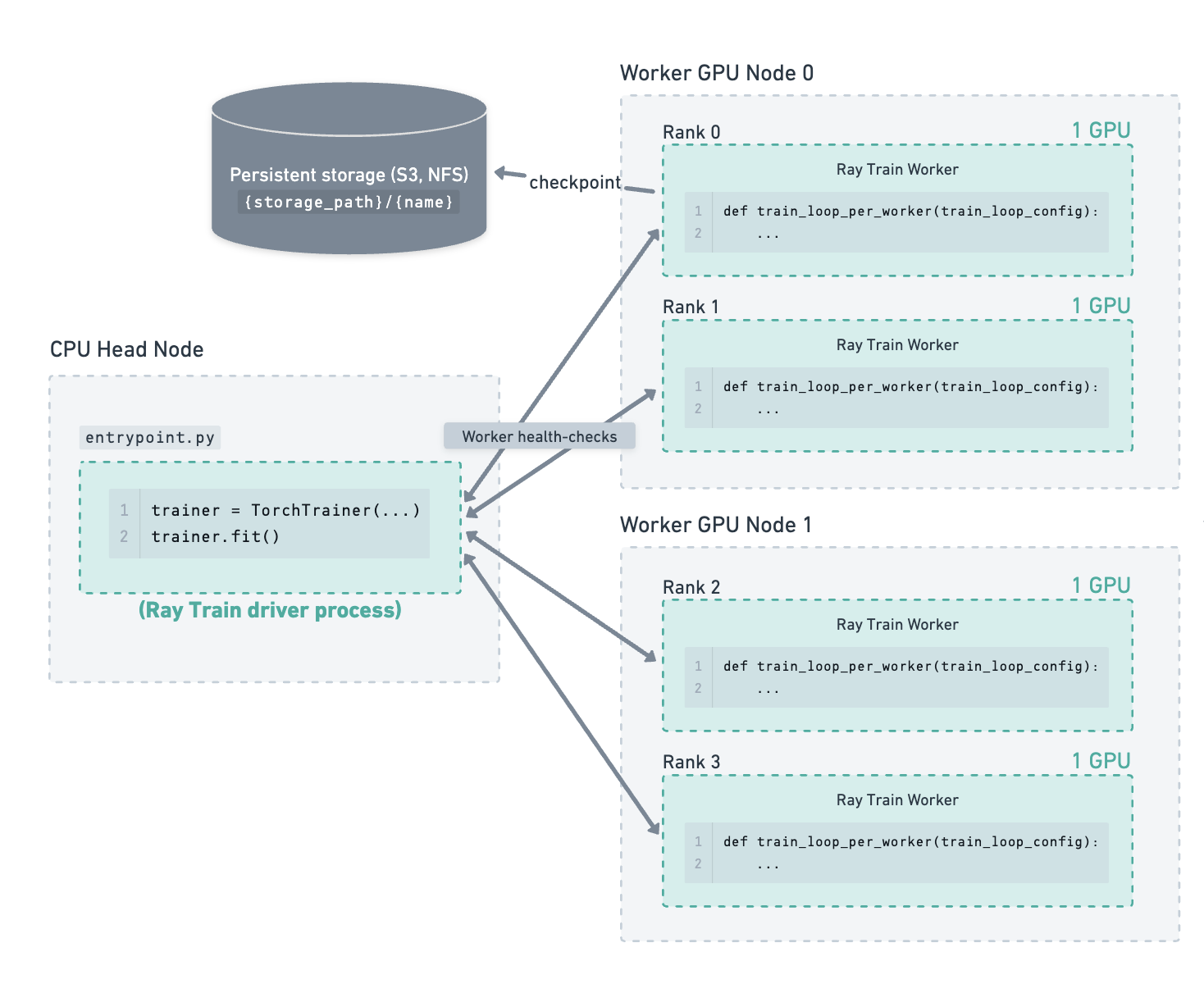
训练已运行一段时间,最新的检查点已保存到云存储。#
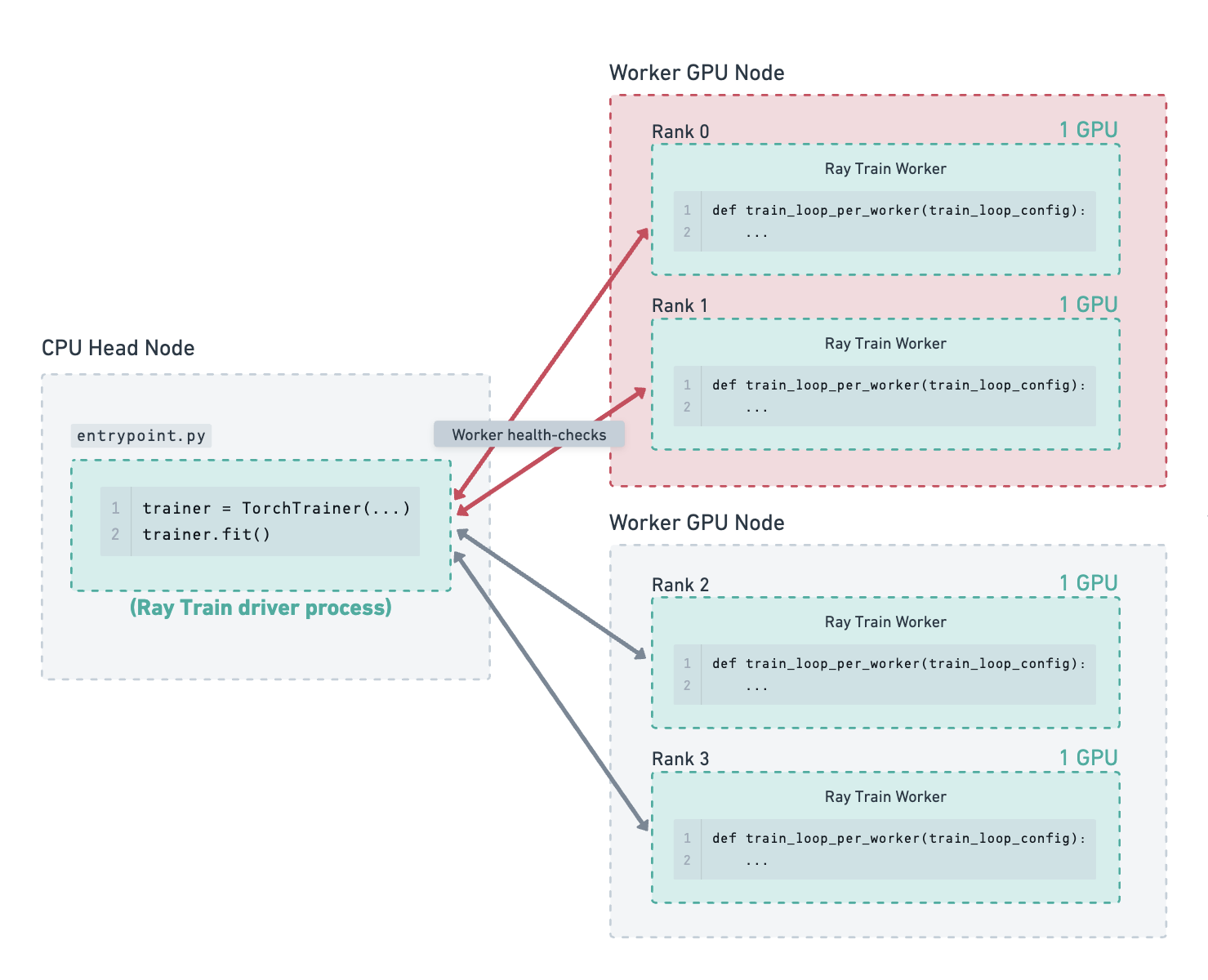
其中一个工作 GPU 节点因硬件故障而失败。Ray Train 检测到此故障并关闭所有工作进程。由于目前检测到的故障次数少于配置的 max_failures,Ray Train 将尝试重新启动训练,而不是退出并抛出错误。#

Ray Train 已请求新的工作节点加入集群,并正在等待其启动。#
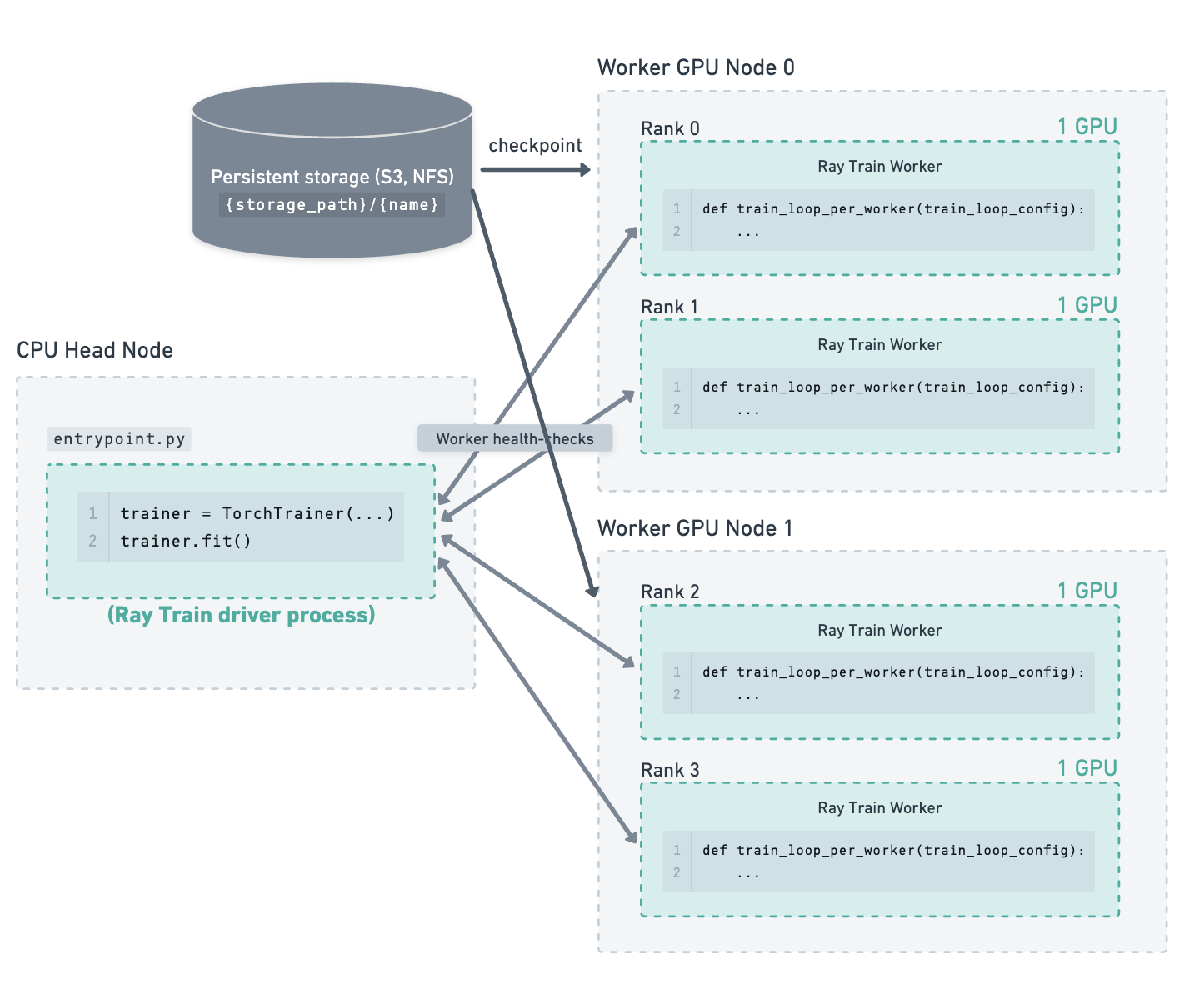
新的工作节点已加入集群。Ray Train 重新启动所有工作进程,并向它们提供最新的检查点。工作进程从存储下载检查点并用它来恢复训练。#
Job 驱动器容错#
Job 驱动器容错用于处理 Ray Train 驱动进程中断的情况。Ray Train 驱动进程是调用 trainer.fit() 的进程,通常位于集群的主节点上。
驱动进程可能由于以下原因之一被中断:
用户手动中断了运行(例如,Ctrl+C)。
运行驱动进程的节点(主节点)崩溃(例如,内存不足,磁盘空间不足)。
整个集群宕机(例如,影响所有节点的网络错误)。
在这些情况下,Ray Train 驱动器(调用 trainer.fit())需要再次启动。重新启动的 Ray Train 驱动器需要找到少量的运行状态,以便从上次运行中断的地方继续。此状态包括最新的报告的检查点,这些检查点位于存储路径。Ray Train 从存储中获取最新的检查点信息,并将其传递给新启动的工作进程以恢复训练。
为了找到此运行状态,Ray Train 依赖于传入与上次运行相同的 RunConfig(storage_path, name) 对。如果 storage_path 或 name 不匹配,Ray Train 将无法找到之前的运行状态,并将从头开始新的运行。
警告
如果无意中重复使用了 name,Ray Train 将会获取之前的运行状态,即使用户是想启动一个新的运行。因此,在启动新运行时,始终传递一个唯一的运行名称。换句话说,name 应该是一个训练作业的唯一标识符。
注意
Job 驱动器崩溃和中断不计入工作进程容错的 max_failures 限制。
以下是一个突出了 Job 驱动器容错最佳实践的训练脚本示例:
# entrypoint.py
import argparse
import tempfile
import uuid
import ray.train
import ray.train.torch
def train_fn_per_worker(train_loop_config: dict):
# [1] Train worker restoration logic.
checkpoint = ray.train.get_checkpoint()
if checkpoint:
with checkpoint.as_directory() as temp_checkpoint_dir:
# model.load_state_dict(torch.load(...))
...
# [2] Checkpoint saving and reporting logic.
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
# torch.save(...)
ray.train.report(
{"loss": 0.1},
checkpoint=ray.train.Checkpoint.from_directory(temp_checkpoint_dir),
)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--storage_path", type=str, required=True)
parser.add_argument("--run_name", type=str, required=True)
args = parser.parse_args()
trainer = ray.train.torch.TorchTrainer(
train_fn_per_worker,
scaling_config=ray.train.ScalingConfig(num_workers=4),
run_config=ray.train.RunConfig(
# [3] Enable worker-level fault tolerance to gracefully handle
# Train worker failures.
failure_config=ray.train.FailureConfig(max_failures=3),
# [4] (Recommendation) The (storage_path, name) pair should be
# determined by the job submitter and passed in as arguments
# to the entrypoint script.
storage_path=args.storage_path,
name=args.run_name,
),
)
trainer.fit()
然后,可以使用以下命令启动入口点脚本:
python entrypoint.py --storage_path s3://my_bucket/ --run_name unique_run_id=da823d5
如果作业中断,可以使用相同的命令来恢复训练。此示例显示了 da823d5 ID,它由启动作业的人确定。该 ID 通常可用于其他目的,例如设置 wandb 或 mlflow 运行 ID。
图示示例#
考虑以下示例:一个集群包含一个 CPU 主节点和 2 个 GPU 工作节点。在这 2 个工作节点上运行着 4 个 GPU 训练工作进程。存储路径已配置为使用云存储,检查点就保存在那里。
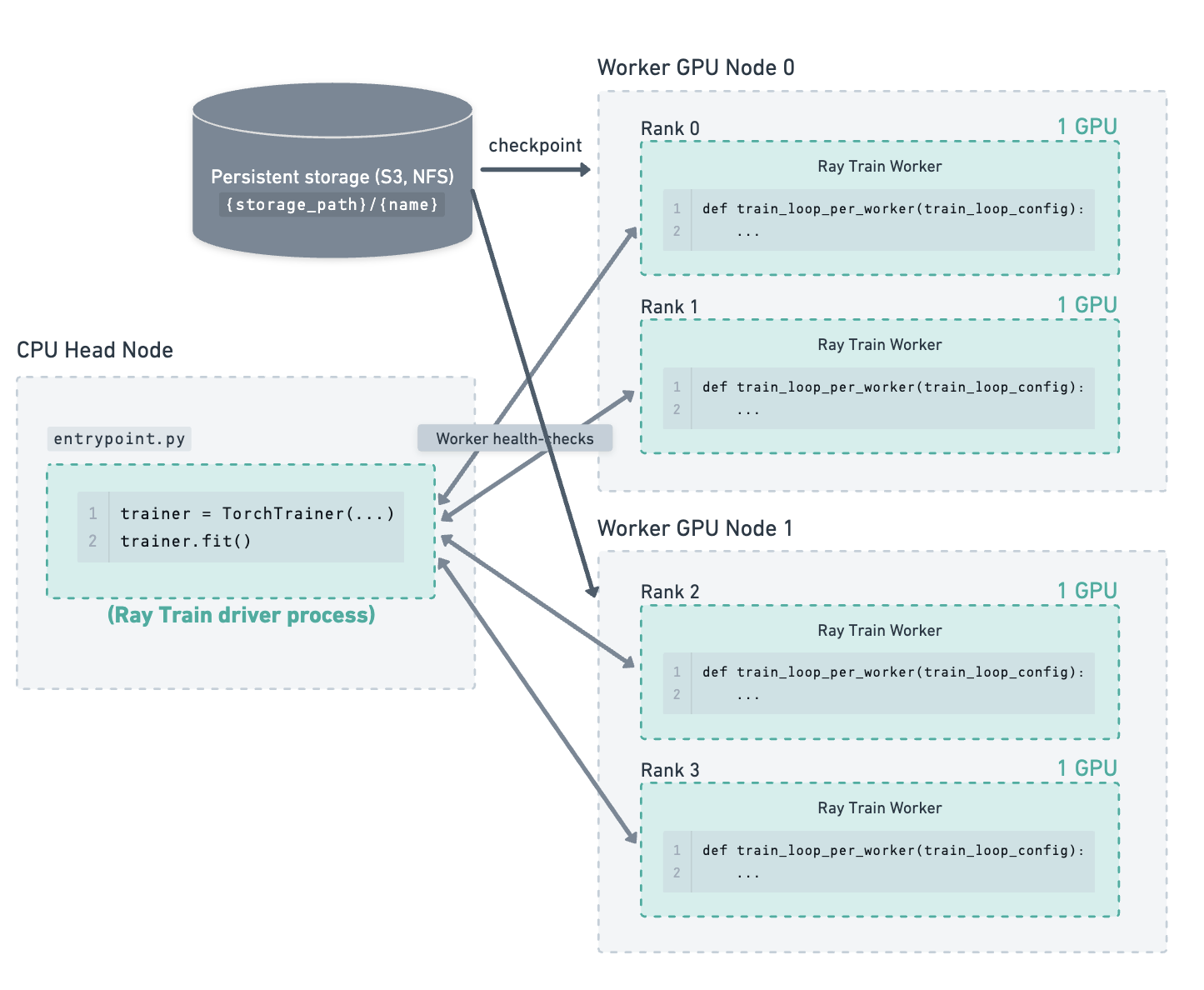
训练已运行一段时间,最新的检查点和运行状态已保存到存储。#
主节点因某种原因(例如,内存不足错误)崩溃,Ray Train 驱动进程中断。#

由于主节点故障,整个集群宕机。#
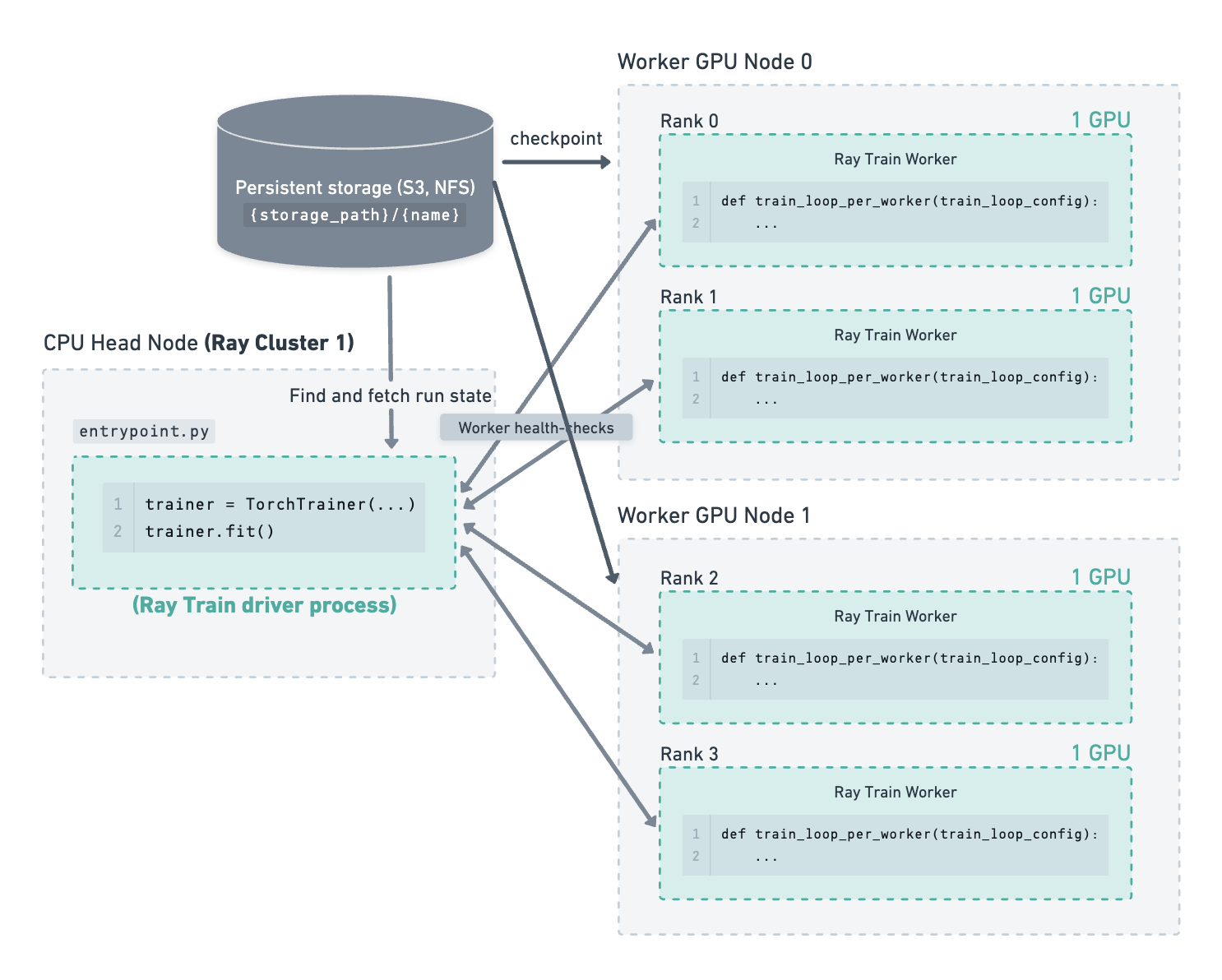
手动重启集群或某个作业提交系统启动了一个新的 Ray 集群。Ray Train 驱动进程在一个新的主节点上运行。Ray Train 从 {storage_path}/{name}(例如,s3://my_bucket/my_run_name)处的存储中获取运行状态信息,并将最新的检查点传递给新启动的工作进程以恢复训练。#
容错 API 弃用#
<Framework>Trainer.restore API 弃用#
从 Ray 2.43 开始,<Framework>Trainer.restore 和 <Framework>Trainer.can_restore API 已被弃用,并将在未来的版本中移除。
动机#
此 API 更改带来了多项优势:
避免将用户代码保存到 pickled 文件:旧的 API 将用户代码保存到 pickled 文件,这可能导致反序列化问题,从而导致无法恢复的运行。
改进的配置体验:虽然某些配置是从 pickled 文件加载的,但某些参数需要重新指定,而另一部分参数甚至可以可选地重新指定。这让用户对恢复的运行中实际使用的配置集感到困惑。
迁移步骤#
要从旧的 <Framework>Trainer.restore API 迁移到新模式,请执行以下操作:
启用环境变量
RAY_TRAIN_V2_ENABLED=1。将
<Framework>Trainer.restore替换为常规的<Framework>Trainer构造函数,确保传入与上次运行相同的storage_path和name。
<Framework>Trainer(restore_from_checkpoint) API 弃用#
从 Ray 2.43 开始,<Framework>Trainer(restore_from_checkpoint) API 已被弃用,并将在未来的版本中移除。
动机#
此 API 是常见的混淆来源,提供的价值很小。它仅用于设置 ray.train.get_checkpoint() 的初始值,而不加载任何其他运行状态。
迁移步骤#
只需通过 train_loop_config 参数传入初始检查点即可。请参阅下方链接的迁移指南以获取代码示例。
附加资源#
Train V2 迁移指南:Train V2 完整迁移指南
Train V2 REP:关于 API 更改的技术细节
处理故障和节点抢占(已弃用 API):旧 API 的文档