监控您的应用程序#
本节将帮助您通过以下方式调试和监控您的 Serve 应用程序:
查看 Ray Dashboard
查看
serve status输出使用 Ray 日志记录和 Loki
检查内置的 Ray Serve 指标
将指标导出到 Arize 平台
Ray Dashboard#
您可以使用 Ray Dashboard 来获取 Ray 集群和 Ray Serve 应用程序状态的高层概览。这包括以下详细信息:
当前正在运行的部署副本数量
Serve 控制器、部署副本和代理的日志
Ray 集群中运行的 Ray 节点(即机器)。
您可以通过集群 URI 上的端口 8265 访问 Ray Dashboard。例如,如果您在本地运行 Ray Serve,可以通过浏览器访问 https://:8265 来访问 Dashboard。
通过访问 Serve 页面 来查看有关您应用程序的重要信息。
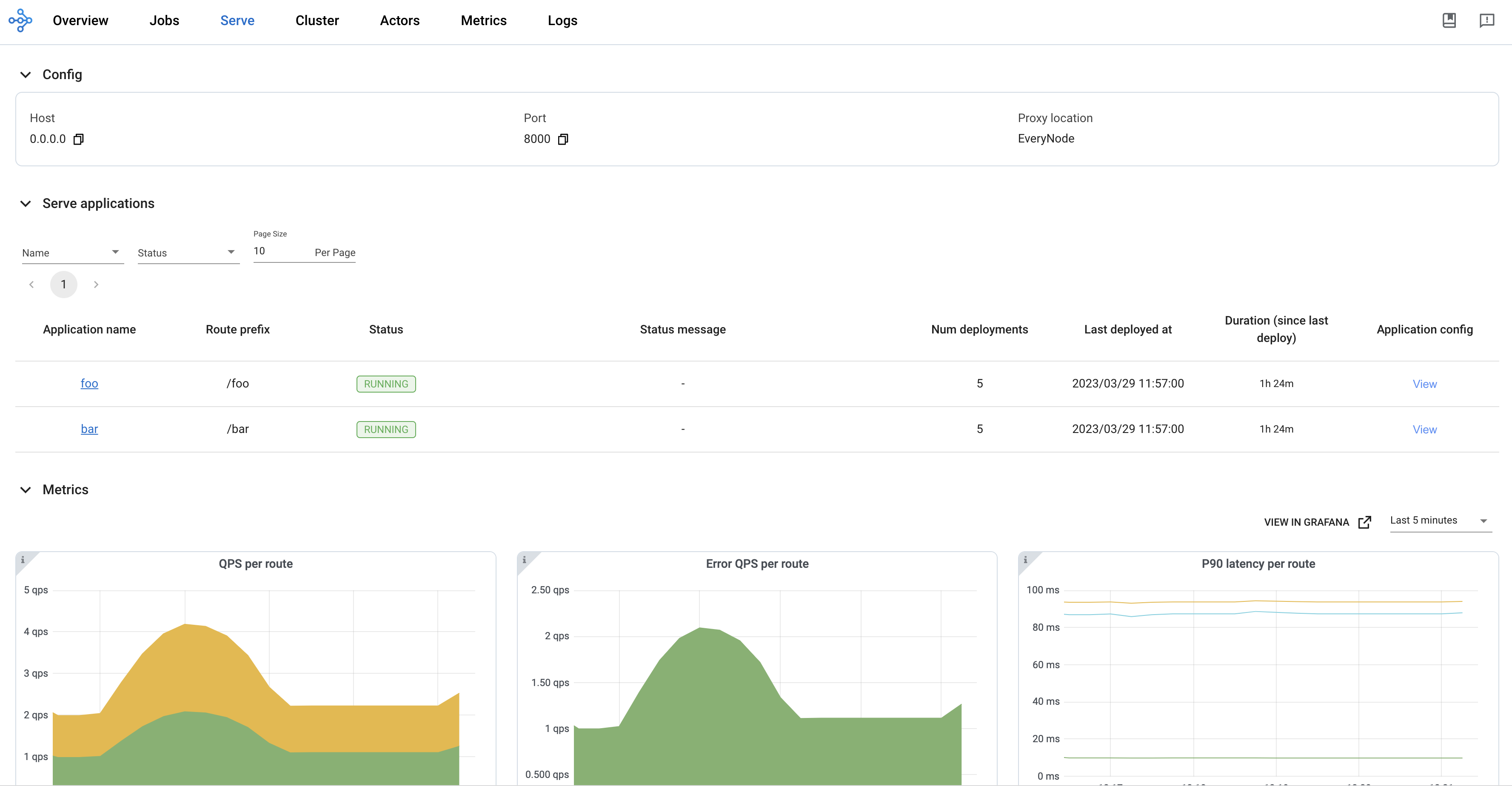
此示例有一个运行名为 Translator 的部署的单节点集群。此部署有 2 个副本。
通过浏览 Serve 页面查看这些副本的详细信息。在每个副本的详细信息页面上。在那里,您可以查看副本的元数据以及副本的日志,包括副本进程生成的 logging 和 print 语句。
另一个有用的视图是 Actors 视图。此示例 Serve 应用程序使用了四个 Ray actors
1 个 Serve 控制器
1 个 HTTP 代理
2 个
Translator部署副本
您可以在 Serve 页面和 Actor 页面上看到这些实体的详细信息。此页面包含其他有用的信息,例如每个 Actor 的进程 ID (PID) 以及指向每个 Actor 日志的链接。您还可以查看任何特定 Actor 是否处于活动状态或已终止,以帮助您调试潜在的集群故障。
提示
要了解有关 Serve 控制器 Actor、HTTP 代理 Actor、部署副本以及它们如何协同工作的更多信息,请查看 Serve 架构 文档。
有关 Ray Dashboard 的详细概述,请参阅 Dashboard 文档。
使用 Serve CLI 检查应用程序#
两个 Serve CLI 命令可以帮助您检查生产环境中的 Serve 应用程序:serve config 和 serve status。如果您有远程集群,serve config 和 serve status 还有一个 --address/-a 参数来访问集群。有关此参数的更多信息,请参阅 VM 部署。
serve config 获取 Ray 集群收到的最新配置文件。此配置文件代表 Serve 应用程序的目标状态。Ray 集群通过部署部署、恢复失败的副本以及执行其他相关操作,不断努力实现并维持此状态。
使用 生产指南 中的 serve_config.yaml 示例
$ ray start --head
$ serve deploy serve_config.yaml
...
$ serve config
name: default
route_prefix: /
import_path: text_ml:app
runtime_env:
pip:
- torch
- transformers
deployments:
- name: Translator
num_replicas: 1
user_config:
language: french
- name: Summarizer
num_replicas: 1
serve status 获取您的 Serve 应用程序的当前状态。此命令报告 Ray 集群上运行的 proxies 和 applications 的状态。
proxies 列出每个代理的状态。每个代理都由其运行节点的节点 ID 标识。代理有三种可能的状态:
STARTING:代理正在启动,尚未准备好处理请求。HEALTHY:代理能够处理请求。它运行正常。UNHEALTHY:代理的健康检查失败。它将被终止,并在该节点上启动一个新的代理。DRAINING:代理健康但已关闭新请求。它可能包含仍在处理的待处理请求。DRAINED:代理已关闭新请求。没有待处理请求。
applications 包含应用程序列表、它们的总体状态以及它们的部署状态。`applications` 中的每个条目将应用程序名称映射到四个字段:
status:Serve 应用程序有四种可能的总体状态:"NOT_STARTED":此集群上尚未部署任何应用程序。"DEPLOYING":应用程序当前正在执行serve deploy请求。它正在部署新部署或更新现有部署。"RUNNING":应用程序处于稳定状态。它已完成任何先前的serve deploy请求的执行,并正在尝试维持最新serve deploy请求设定的目标状态。"DEPLOY_FAILED":最新的serve deploy请求失败。
message:提供当前状态的上下文。deployment_timestamp:Serve 收到最后一个serve deploy请求的 UNIX 时间戳。时间戳是使用ServeController的本地时钟计算的。deployments:代表每个部署状态的条目列表。每个条目将部署名称映射到三个字段:status:Serve 部署有六种可能的状态:"UPDATING":部署正在更新以满足先前deploy请求设定的目标状态。"HEALTHY":部署健康且以目标副本数量运行。"UNHEALTHY":部署已更新但随后变得不健康。这种情况可能是由于副本无法扩容、副本健康检查失败或通用的系统或机器错误。"DEPLOY_FAILED":部署启动或更新失败。这种情况很可能是由于部署构造函数中的错误。"UPSCALING":部署(启用自动扩缩容)正在增加副本数量。"DOWNSCALING":部署(启用自动扩缩容)正在减少副本数量。
replica_states:副本状态列表以及处于该状态的副本数量。每个副本有五种可能的状态:STARTING:副本正在启动,尚未准备好处理请求。UPDATING:副本正在进行reconfigure更新。RECOVERING:副本正在恢复其状态。RUNNING:副本正在正常运行并能够处理请求。STOPPING:副本正在被停止。
message:提供当前状态的上下文。
使用 serve status 命令来检查部署部署后的状态以及在整个生命周期中的状态。
使用 前面的部分 中的 serve_config.yaml 示例
$ ray start --head
$ serve deploy serve_config.yaml
...
$ serve status
proxies:
cef533a072b0f03bf92a6b98cb4eb9153b7b7c7b7f15954feb2f38ec: HEALTHY
applications:
default:
status: RUNNING
message: ''
last_deployed_time_s: 1694041157.2211847
deployments:
Translator:
status: HEALTHY
replica_states:
RUNNING: 1
message: ''
Summarizer:
status: HEALTHY
replica_states:
RUNNING: 1
message: ''
对于具有 KubeRay 的 Kubernetes 部署,serve status 与 Kubernetes 的集成更加紧密。请参阅 在 Kubernetes 中获取 Serve 应用程序的状态。
在 Python 中获取应用程序详细信息#
调用 serve.status() API 以在 Python 中获取 Serve 应用程序详细信息。`serve.status()` 返回的信息与 `serve status` CLI 命令相同,并且封装在 `dataclass` 中。在部署或 Ray 驱动程序脚本中使用此方法以获取 Ray 集群上 Serve 应用程序的实时信息。例如,此 `monitoring_app` 报告集群上所有 `RUNNING` 的 Serve 应用程序。
from typing import List, Dict
from ray import serve
from ray.serve.schema import ServeStatus, ApplicationStatusOverview
@serve.deployment
def get_healthy_apps() -> List[str]:
serve_status: ServeStatus = serve.status()
app_statuses: Dict[str, ApplicationStatusOverview] = serve_status.applications
running_apps = []
for app_name, app_status in app_statuses.items():
if app_status.status == "RUNNING":
running_apps.append(app_name)
return running_apps
monitoring_app = get_healthy_apps.bind()
Ray 日志记录#
为了理解系统级行为并在运行时展示应用程序级细节,您可以利用 Ray 日志记录。
Ray Serve 使用 Python 的标准 `logging` 模块,其 logger 名称为 `"ray.serve"`。默认情况下,日志会从 actor 发送到每个节点的 `stderr` 以及磁盘上的 `/tmp/ray/session_latest/logs/serve/`。这包括来自 Serve 控制器和代理的系统级日志,以及部署副本内部产生的访问日志和自定义用户日志。
在开发过程中,日志会流式传输到驱动程序 Ray 程序(调用 `serve.run()` 或 `serve run` CLI 命令的 Python 脚本),因此在调试时保持驱动程序运行会很方便。
例如,我们来运行一个基本的 Serve 应用程序并查看它发出的日志。
首先,让我们创建一个简单的部署,当它被查询时会记录一条自定义日志消息
# File name: monitoring.py
from ray import serve
import logging
from starlette.requests import Request
logger = logging.getLogger("ray.serve")
@serve.deployment
class SayHello:
async def __call__(self, request: Request) -> str:
logger.info("Hello world!")
return "hi"
say_hello = SayHello.bind()
使用 `serve run` CLI 命令运行此部署
$ serve run monitoring:say_hello
2023-04-10 15:57:32,100 INFO scripts.py:380 -- Deploying from import path: "monitoring:say_hello".
[2023-04-10 15:57:33] INFO ray._private.worker::Started a local Ray instance. View the dashboard at http://127.0.0.1:8265
(ServeController pid=63503) INFO 2023-04-10 15:57:35,822 controller 63503 deployment_state.py:1168 - Deploying new version of deployment SayHello.
(ProxyActor pid=63513) INFO: Started server process [63513]
(ServeController pid=63503) INFO 2023-04-10 15:57:35,882 controller 63503 deployment_state.py:1386 - Adding 1 replica to deployment SayHello.
2023-04-10 15:57:36,840 SUCC scripts.py:398 -- Deployed Serve app successfully.
serve run 会立即打印一些日志消息。请注意,其中一些消息以以下标识符开头:
(ServeController pid=63881)
这些消息是来自 Ray Serve actors 的日志。它们描述了是哪个 actor(Serve 控制器、代理或部署副本)创建了日志,以及它的进程 ID 是什么(这在区分不同的部署副本或代理时很有用)。其余的日志消息是 actor 生成的实际日志语句。
当 `serve run` 运行时,我们可以在单独的终端窗口中查询部署
curl -X GET http://localhost:8000/
这会导致 HTTP 代理和部署副本向运行 `serve run` 的终端打印日志语句。
(ServeReplica:SayHello pid=63520) INFO 2023-04-10 15:59:45,403 SayHello SayHello#kTBlTj HzIYOzaEgN / monitoring.py:16 - Hello world!
(ServeReplica:SayHello pid=63520) INFO 2023-04-10 15:59:45,403 SayHello SayHello#kTBlTj HzIYOzaEgN / replica.py:527 - __CALL__ OK 0.5ms
注意
日志消息包括日志级别、时间戳、部署名称、副本标签、请求 ID、路由、文件名和行号。
您可以在 `/tmp/ray/session_latest/logs/serve/` 找到这些存储的日志副本。您可以使用 ELK 或 Loki 等日志栈来解析这些存储的日志,以便能够按部署或副本进行搜索。
Serve 支持通过设置环境变量 `RAY_ROTATION_MAX_BYTES` 和 `RAY_ROTATION_BACKUP_COUNT` 来对这些日志进行 日志轮换。
要禁用副本级别的日志或以其他方式配置日志记录,请 **在部署构造函数内部** 配置 `"ray.serve"` logger。
import logging
logger = logging.getLogger("ray.serve")
@serve.deployment
class Silenced:
def __init__(self):
logger.setLevel(logging.ERROR)
这可以控制哪些日志被写入 STDOUT 或磁盘上的文件。除了标准的 Python logger 外,Serve 还支持自定义日志记录。自定义日志记录允许您控制哪些消息被写入 STDOUT/STDERR、磁盘文件或两者。
有关 Ray 中日志记录的详细概述,请参阅 Ray 日志记录。
配置 Serve 日志记录#
从 ray 2.9 开始,`logging_config` API 用于配置 Ray Serve 的日志记录。您可以为 Ray Serve 配置日志记录。将 `LoggingConfig` 的字典或对象传递给 `serve.run` 或 `@serve.deployment` 的 `logging_config` 参数。
配置日志格式#
您可以通过将 `encoding=JSON` 传递给 `serve.run` 或 `@serve.deployment` 的 `logging_config` 参数来配置 JSON 日志格式。
import requests
from ray import serve
from ray.serve.schema import LoggingConfig
@serve.deployment
class Model:
def __call__(self) -> int:
return "hello world"
serve.run(Model.bind(), logging_config=LoggingConfig(encoding="JSON"))
resp = requests.get("https://:8000/")
import requests
from ray import serve
from ray.serve.schema import LoggingConfig
@serve.deployment(logging_config=LoggingConfig(encoding="JSON"))
class Model:
def __call__(self) -> int:
return "hello world"
serve.run(Model.bind())
resp = requests.get("https://:8000/")
在 `Model` 副本的日志文件中,您应该看到以下内容:
# cat `ls /tmp/ray/session_latest/logs/serve/replica_default_Model_*`
{"levelname": "INFO", "asctime": "2024-02-27 10:36:08,908", "deployment": "default_Model", "replica": "rdofcrh4", "message": "replica.py:855 - Started initializing replica."}
{"levelname": "INFO", "asctime": "2024-02-27 10:36:08,908", "deployment": "default_Model", "replica": "rdofcrh4", "message": "replica.py:877 - Finished initializing replica."}
{"levelname": "INFO", "asctime": "2024-02-27 10:36:10,127", "deployment": "default_Model", "replica": "rdofcrh4", "request_id": "f4f4b3c0-1cca-4424-9002-c887d7858525", "route": "/", "application": "default", "message": "replica.py:1068 - Started executing request to method '__call__'."}
{"levelname": "INFO", "asctime": "2024-02-27 10:36:10,127", "deployment": "default_Model", "replica": "rdofcrh4", "request_id": "f4f4b3c0-1cca-4424-9002-c887d7858525", "route": "/", "application": "default", "message": "replica.py:373 - __CALL__ OK 0.6ms"}
注意
正在弃用 `RAY_SERVE_ENABLE_JSON_LOGGING=1` 环境变量,将在下一个版本中移除。要全局启用 JSON 日志记录,请使用 `RAY_SERVE_LOG_ENCODING=JSON`。
禁用访问日志#
注意
访问日志是 Ray Serve 的流量日志,它按请求打印到代理日志文件和副本日志文件。有时它有助于调试,但它也可能很嘈杂。
您还可以通过将 `disable_access_log=True` 传递给 `@serve.deployment` 的 `logging_config` 参数来禁用访问日志。例如:
import requests
import logging
from ray import serve
@serve.deployment(logging_config={"enable_access_log": False})
class Model:
def __call__(self):
logger = logging.getLogger("ray.serve")
logger.info("hello world")
serve.run(Model.bind())
resp = requests.get("https://:8000/")
`Model` 副本的日志文件不包含 Serve 流量日志,您应该只在日志文件中看到应用程序日志。
# cat `ls /tmp/ray/session_latest/logs/serve/replica_default_Model_*`
INFO 2024-02-27 15:43:12,983 default_Model 4guj63jr replica.py:855 - Started initializing replica.
INFO 2024-02-27 15:43:12,984 default_Model 4guj63jr replica.py:877 - Finished initializing replica.
INFO 2024-02-27 15:43:13,492 default_Model 4guj63jr 2246c4bb-73dc-4524-bf37-c7746a6b3bba / <stdin>:5 - hello world
配置不同部署和应用程序中的日志记录#
您还可以通过将 `logging_config` 传递给 `serve.run` 来在应用程序级别配置日志记录。例如:
import requests
import logging
from ray import serve
@serve.deployment
class Router:
def __init__(self, handle):
self.handle = handle
async def __call__(self):
logger = logging.getLogger("ray.serve")
logger.debug("This debug message is from the router.")
return await self.handle.remote()
@serve.deployment(logging_config={"log_level": "INFO"})
class Model:
def __call__(self) -> int:
logger = logging.getLogger("ray.serve")
logger.debug("This debug message is from the model.")
return "hello world"
serve.run(Router.bind(Model.bind()), logging_config={"log_level": "DEBUG"})
resp = requests.get("https://:8000/")
在 Router 的日志文件中,您应该看到以下内容:
# cat `ls /tmp/ray/session_latest/logs/serve/replica_default_Router_*`
INFO 2024-02-27 16:05:10,738 default_Router cwnihe65 replica.py:855 - Started initializing replica.
INFO 2024-02-27 16:05:10,739 default_Router cwnihe65 replica.py:877 - Finished initializing replica.
INFO 2024-02-27 16:05:11,233 default_Router cwnihe65 4db9445d-fc9e-490b-8bad-0a5e6bf30899 / replica.py:1068 - Started executing request to method '__call__'.
DEBUG 2024-02-27 16:05:11,234 default_Router cwnihe65 4db9445d-fc9e-490b-8bad-0a5e6bf30899 / <stdin>:7 - This debug message is from the router.
INFO 2024-02-27 16:05:11,238 default_Router cwnihe65 4db9445d-fc9e-490b-8bad-0a5e6bf30899 / router.py:308 - Using router <class 'ray.serve._private.replica_scheduler.pow_2_scheduler.PowerOfTwoChoicesReplicaScheduler'>.
DEBUG 2024-02-27 16:05:11,240 default_Router cwnihe65 long_poll.py:157 - LongPollClient <ray.serve._private.long_poll.LongPollClient object at 0x10daa5a80> received updates for keys: [(LongPollNamespace.DEPLOYMENT_CONFIG, DeploymentID(name='Model', app='default')), (LongPollNamespace.RUNNING_REPLICAS, DeploymentID(name='Model', app='default'))].
INFO 2024-02-27 16:05:11,241 default_Router cwnihe65 pow_2_scheduler.py:255 - Got updated replicas for deployment 'Model' in application 'default': {'default#Model#256v3hq4'}.
DEBUG 2024-02-27 16:05:11,241 default_Router cwnihe65 long_poll.py:157 - LongPollClient <ray.serve._private.long_poll.LongPollClient object at 0x10daa5900> received updates for keys: [(LongPollNamespace.DEPLOYMENT_CONFIG, DeploymentID(name='Model', app='default')), (LongPollNamespace.RUNNING_REPLICAS, DeploymentID(name='Model', app='default'))].
INFO 2024-02-27 16:05:11,245 default_Router cwnihe65 4db9445d-fc9e-490b-8bad-0a5e6bf30899 / replica.py:373 - __CALL__ OK 12.2ms
在 Model 的日志文件中,您应该看到以下内容:
# cat `ls /tmp/ray/session_latest/logs/serve/replica_default_Model_*`
INFO 2024-02-27 16:05:10,735 default_Model 256v3hq4 replica.py:855 - Started initializing replica.
INFO 2024-02-27 16:05:10,735 default_Model 256v3hq4 replica.py:877 - Finished initializing replica.
INFO 2024-02-27 16:05:11,244 default_Model 256v3hq4 4db9445d-fc9e-490b-8bad-0a5e6bf30899 / replica.py:1068 - Started executing request to method '__call__'.
INFO 2024-02-27 16:05:11,244 default_Model 256v3hq4 4db9445d-fc9e-490b-8bad-0a5e6bf30899 / replica.py:373 - __CALL__ OK 0.6ms
当您在应用程序级别设置 `logging_config` 时,Ray Serve 会将其应用于应用程序中的所有部署。当您同时在部署级别设置 `logging_config` 时,部署级别的配置将覆盖应用程序级别的配置。
为 Serve 组件配置日志记录#
您还可以通过将 `logging_config` 传递给 `serve.start` 来更新 Serve 控制器和代理的日志记录配置,方法与上述类似。
from ray import serve
serve.start(
logging_config={
"encoding": "JSON",
"log_level": "DEBUG",
"enable_access_log": False,
}
)
设置请求 ID#
您可以通过在请求标头中包含 `X-Request-ID` 并从响应中检索请求 ID 来为每个 HTTP 请求设置自定义请求 ID。例如:
from ray import serve
import requests
@serve.deployment
class Model:
def __call__(self) -> int:
return 1
serve.run(Model.bind())
resp = requests.get("https://:8000", headers={"X-Request-ID": "123-234"})
print(resp.headers["X-Request-ID"])
自定义请求 ID `123-234` 可以在打印到 HTTP 代理日志文件和部署日志文件的访问日志中看到。
HTTP 代理日志文件
INFO 2023-07-20 13:47:54,221 http_proxy 127.0.0.1 123-234 / default http_proxy.py:538 - GET 200 8.9ms
部署日志文件
(ServeReplica:default_Model pid=84006) INFO 2023-07-20 13:47:54,218 default_Model default_Model#yptKoo 123-234 / default replica.py:691 - __CALL__ OK 0.2ms
注意
请求 ID 用于将系统中的日志关联起来。避免发送重复的请求 ID,这在调试时可能会导致混淆。
使用 Loki 过滤日志#
您可以使用 Loki 来探索和过滤您的日志。在 Kubernetes 上进行设置和配置非常简单,但作为一个教程,我们手动设置 Loki。
对于本教程,您需要 Loki 和 Promtail,它们都受 Grafana Labs 支持。请按照 Grafana 网站上的安装说明获取 Loki 和 Promtail 的可执行文件。为了方便起见,请将 Loki 和 Promtail 可执行文件保存在同一个目录中,然后在终端中导航到该目录。
现在,让我们使用 Promtail 将您的日志导入 Loki。
将以下文件另存为 `promtail-local-config.yaml`
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: https://:3100/loki/api/v1/push
scrape_configs:
- job_name: ray
static_configs:
- labels:
job: ray
__path__: /tmp/ray/session_latest/logs/serve/*.*
对于 Ray Serve 相关的内容是 `static_configs` 字段,我们在其中使用 `__path__` 指示了我们的日志文件的位置。表达式 `*.*` 将匹配所有文件,但不会匹配目录,因为它们会导致 Promtail 出错。
我们将本地运行 Loki。在终端中使用以下命令获取 Loki 的默认配置文件:
wget https://raw.githubusercontent.com/grafana/loki/v2.1.0/cmd/loki/loki-local-config.yaml
现在启动 Loki:
./loki-darwin-amd64 -config.file=loki-local-config.yaml
在这里,您可能需要将 `./loki-darwin-amd64` 替换为您的 Loki 可执行文件的路径,该路径可能因您的操作系统而异。
启动 Promtail 并传入我们之前保存的配置文件的路径:
./promtail-darwin-amd64 -config.file=promtail-local-config.yaml
同样,您可能需要将 `./promtail-darwin-amd64` 替换为您的 Promtail 可执行文件。
运行以下 Python 脚本来部署一个基本的 Serve 部署,其中包含一个 Serve 部署日志记录器,并发出一些请求:
from ray import serve
import logging
import requests
logger = logging.getLogger("ray.serve")
@serve.deployment
class Counter:
def __init__(self):
self.count = 0
def __call__(self, request):
self.count += 1
logger.info(f"count: {self.count}")
return {"count": self.count}
counter = Counter.bind()
serve.run(counter)
for i in range(10):
requests.get("http://127.0.0.1:8000/")
现在,安装并运行 Grafana,然后导航到 `https://:3000`,您可以使用默认凭据登录:
用户名:admin
密码:admin
在欢迎页面上,单击“Add your first data source”(添加您的第一个数据源),然后单击“Loki”以添加 Loki 作为数据源。
现在,单击左侧面板中的“Explore”(探索)。您已准备好运行查询!
要过滤所有这些 Ray 日志以查找与我们的部署相关的日志,请使用以下 LogQL 查询:
{job="ray"} |= "Counter"
您应该会看到类似以下的内容:
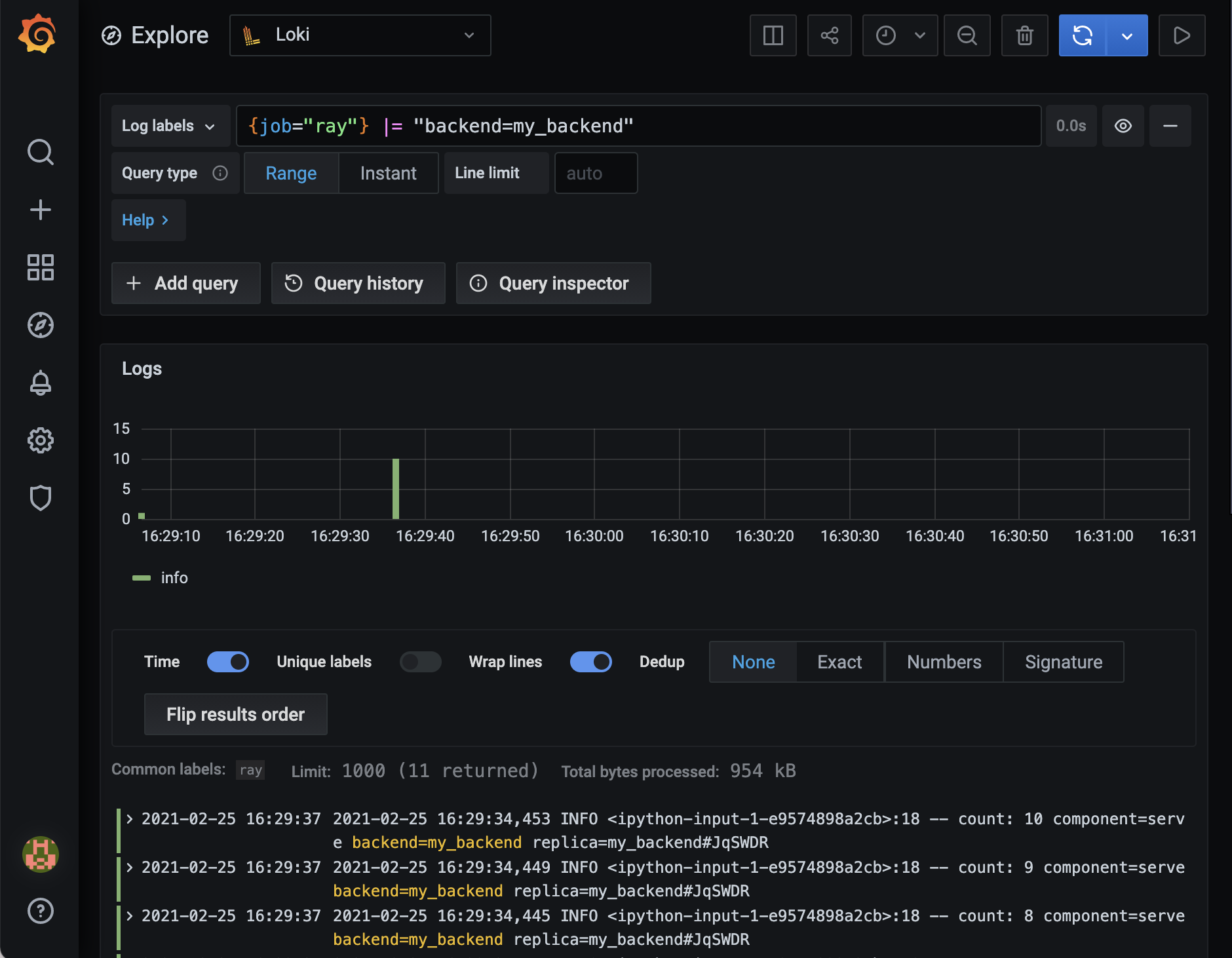
您可以使用 Loki 过滤您的 Ray Serve 日志并更快地收集见解。
内置 Ray Serve 指标#
Ray Serve 通过 Ray 指标监控基础设施 公开了重要的系统指标,例如成功和失败请求的数量。默认情况下,指标以 Prometheus 格式在每个节点上公开。
注意
通过 Python DeploymentHandle 调用部署与通过 HTTP/gRPC 调用部署时,会收集不同的指标。请参阅每个表下方的标记:
[H] - 使用 HTTP/gRPC 代理调用时可用
[D] - 使用 Python
DeploymentHandle调用时可用[†] - 内部指标,用于高级调试;未来版本可能会更改
警告
直方图桶配置
直方图指标使用预定义的桶边界来聚合延迟测量。默认桶为:[1, 2, 5, 10, 20, 50, 100, 200, 300, 400, 500, 1000, 2000, 5000, 10000, 60000, 120000, 300000, 600000](毫秒)。
您可以通过环境变量自定义这些桶:
RAY_SERVE_REQUEST_LATENCY_BUCKETS_MS:控制请求延迟直方图的桶边界。ray_serve_http_request_latency_msray_serve_grpc_request_latency_msray_serve_deployment_processing_latency_ms
RAY_SERVE_MODEL_LOAD_LATENCY_BUCKETS_MS:控制模型复用延迟直方图的桶边界。ray_serve_multiplexed_model_load_latency_msray_serve_multiplexed_model_unload_latency_ms
RAY_SERVE_BATCH_UTILIZATION_BUCKETS_PERCENT:控制批处理利用率直方图的桶边界。默认:[5, 10, 20, 30, 40, 50, 60, 70, 80, 90, 95, 99, 100](百分比)。ray_serve_batch_utilization_percent
RAY_SERVE_BATCH_SIZE_BUCKETS:控制批处理大小直方图的桶边界。默认:[1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024]。ray_serve_actual_batch_size
注意:`ray_serve_batch_wait_time_ms` 和 `ray_serve_batch_execution_time_ms` 使用与 `RAY_SERVE_REQUEST_LATENCY_BUCKETS_MS` 相同的桶。
将这些设置为逗号分隔的值,例如:`RAY_SERVE_REQUEST_LATENCY_BUCKETS_MS="10,50,100,500,1000,5000"` 或 `RAY_SERVE_BATCH_SIZE_BUCKETS="1,4,8,16,32,64"`。
直方图精度注意事项
Prometheus 直方图将数据聚合到预定义的桶中,这可能会影响仪表板上显示的百分位数计算(例如 p50、p95、p99)的准确性。
超出桶范围的值:如果您的延迟超过最大的桶边界(默认值:600,000 毫秒 / 10 分钟),它们都将落入 `
+Inf` 桶中,百分位数估算将不准确。稀疏桶覆盖:如果您的实际延迟集中在两个间距较大的桶之间,计算出的百分位数会进行插值,可能无法反映真实值。
桶边界在启动时固定:更改桶环境变量(例如 `
RAY_SERVE_REQUEST_LATENCY_BUCKETS_MS`、`RAY_SERVE_BATCH_SIZE_BUCKETS` 等)需要重新启动 Serve actor 才能生效。
为了获得准确的百分位数计算,请配置与您预期的延迟分布密切匹配的桶边界。例如,如果大多数请求在 10-100 毫秒内完成,请在该范围内使用更精细的桶。
请求生命周期和指标#
下图显示了指标在请求路径上的捕获位置:
REQUEST FLOW
┌─────────────────────────────────────────────────────────────────────────────┐
│ │
│ ┌─────────────────────────────────────────────────────────────────────┐ │
│ │ HTTP/gRPC PROXY │ │
│ │ │ │
│ │ ○ ray_serve_num_ongoing_http_requests (while processing) │ │
│ │ ○ ray_serve_num_http_requests_total (on completion) │ │
│ │ ○ ray_serve_http_request_latency_ms (on completion) │ │
│ │ ○ ray_serve_num_http_error_requests_total (on error response) │ │
│ └──────────────────────────────┬──────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────────────────┐ │
│ │ DEPLOYMENT HANDLE │ │
│ │ │ │
│ │ ○ ray_serve_handle_request_counter_total (on completion) │ │
│ └──────────────────────────────┬──────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────────────────┐ │
│ │ ROUTER │ │
│ │ │ │
│ │ ○ ray_serve_num_router_requests_total (on request routed) │ │
│ │ ○ ray_serve_deployment_queued_queries (while in queue) │ │
│ │ ○ ray_serve_num_ongoing_requests_at_replicas (assigned to replica) │ │
│ └──────────────────────────────┬──────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────────────────┐ │
│ │ REPLICA │ │
│ │ │ │
│ │ ○ ray_serve_replica_processing_queries (while processing) │ │
│ │ ○ ray_serve_deployment_processing_latency_ms (on completion) │ │
│ │ ○ ray_serve_deployment_request_counter_total (on completion) │ │
│ │ ○ ray_serve_deployment_error_counter_total (on exception) │ │
│ └─────────────────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────────────┘
Legend:
─────────────────────────────────────────────────────────────────────────────
• Counters (_total): Incremented once per event
• Gauges (ongoing/queued): Show current count, increase on start, decrease on end
• Histograms (latency_ms): Record duration when request completes
HTTP/gRPC 代理指标#
这些指标跟踪代理级别的请求吞吐量和延迟(请求入口点)。
指标 |
类型 |
标签 |
描述 |
|---|---|---|---|
|
Gauge |
|
代理正在处理的当前 HTTP 请求数量。 |
|
Gauge |
|
代理正在处理的当前 gRPC 请求数量。 |
|
Counter |
|
代理处理的总 HTTP 请求数量。 |
|
Counter |
|
代理处理的总 gRPC 请求数量。 |
|
Histogram |
|
请求延迟(从代理收到请求到发送响应)的直方图(毫秒)。 |
|
Histogram |
|
gRPC 请求延迟(从代理收到请求到发送响应)的直方图(毫秒)。 |
|
Counter |
|
返回非 2xx/3xx 状态码的总 HTTP 请求数量。 |
|
Counter |
|
返回非 OK 状态码的总 gRPC 请求数量。 |
|
Counter |
|
每个部署的总 HTTP 错误数。有助于识别导致错误的部署。 |
|
Counter |
|
每个部署的总 gRPC 错误数。有助于识别导致错误的部署。 |
请求路由指标#
这些指标跟踪请求路由和排队行为。
指标 |
类型 |
标签 |
描述 |
|---|---|---|---|
|
Counter |
|
此 |
|
Counter |
|
路由到部署的总请求数。 |
|
Gauge |
|
当前等待分配给副本的请求数。高值表示存在反压。 |
|
Gauge |
|
当前已分配并发送到副本但尚未完成的请求数。 |
|
Histogram |
|
请求在路由器队列中等待分配给副本的毫秒数直方图。这包括解析待定请求参数的时间。 |
|
Gauge |
|
通过路由器队列长度缓存跟踪的、当前正在副本上运行的请求数。 |
|
Gauge |
|
路由器中当前正在进行的请求调度任务数。 |
|
Gauge |
|
当前处于指数退避(重试前等待)的调度任务数。 |
请求处理指标#
这些指标跟踪副本级别的请求吞吐量、错误和延迟。
指标 |
类型 |
标签 |
描述 |
|---|---|---|---|
|
Gauge |
|
副本当前正在处理的请求数。 |
|
Counter |
|
副本处理的总请求数。 |
|
Histogram |
|
请求处理时间的毫秒数直方图(不包括队列等待时间)。 |
|
Counter |
|
处理请求时引发的总异常数。 |
批处理指标#
这些指标跟踪使用 @serve.batch 的部署的请求批处理行为。使用它们来调整批处理参数和调试延迟问题。
指标 |
类型 |
标签 |
描述 |
|---|---|---|---|
|
Histogram |
|
请求等待批次填充的毫秒数。高值表明批处理超时可能过长。 |
|
Histogram |
|
执行批处理函数的毫秒数。 |
|
Gauge |
|
当前等待批处理队列中的请求数。高值表明存在批处理瓶颈。 |
|
Histogram |
|
批处理利用率(百分比)( |
|
Histogram |
|
每个批次的计算大小。当配置了 |
|
Counter |
|
已执行的总批次数。与请求计数器进行比较以衡量批处理效率。 |
副本生命周期指标#
这些指标跟踪副本的运行状况和重启。
指标 |
类型 |
标签 |
描述 |
|---|---|---|---|
|
Gauge |
|
副本的健康状态: |
|
Counter |
|
副本启动的总次数(包括因故障重启)。 |
自动伸缩指标#
这些指标提供对自动伸缩行为的可见性,并有助于调试伸缩问题。
指标 |
类型 |
标签 |
描述 |
|---|---|---|---|
|
Gauge |
|
自动伸缩器尝试达到的目标副本数。与实际副本数进行比较以识别伸缩延迟。 |
|
Gauge |
|
策略的原始自动伸缩决策(副本数量),*在*应用 |
|
Gauge |
|
自动伸缩器看到的总请求数(排队 + 进行中)。这是伸缩决策的输入。 |
|
Histogram |
|
执行自动伸缩策略所花费的毫秒数。 |
|
Histogram |
|
副本指标到达控制器所花费的毫秒数。高值可能表明控制器过载。 |
|
Histogram |
|
句柄指标到达控制器所花费的毫秒数。高值可能表明控制器过载。 |
|
Counter |
|
从用户定义的函数收集自动伸缩指标的失败尝试总数。非零值表示用户代码中存在错误。 |
|
Histogram |
|
执行用户定义的自动伸缩统计函数所花费的毫秒数直方图。 |
模型多路复用指标#
这些指标跟踪使用 @serve.multiplexed 的部署的模型加载和缓存行为。
指标 |
类型 |
标签 |
描述 |
|---|---|---|---|
|
Histogram |
|
加载模型的毫秒数直方图。 |
|
Histogram |
|
卸载模型的毫秒数直方图。 |
|
Gauge |
|
副本上当前加载的模型数。 |
|
Counter |
|
模型加载操作的总数。 |
|
Counter |
|
模型卸载操作的总数(驱逐)。 |
|
Gauge |
|
指示当前加载了哪些模型 ID。当模型加载时,值为 |
|
Counter |
|
|
控制器指标#
这些指标跟踪 Serve 控制器的性能。有助于调试控制平面问题。
指标 |
类型 |
标签 |
描述 |
|---|---|---|---|
|
Gauge |
— |
上次控制循环迭代的持续时间(秒)。 |
|
Gauge |
|
控制循环迭代的总次数。单调递增。 |
|
Counter |
|
传输到客户端的长轮询更新总数。 |
要亲眼看看,请先运行以下命令来启动 Ray 并设置指标导出端口
ray start --head --metrics-export-port=8080
然后运行以下脚本
from ray import serve
import time
import requests
@serve.deployment
def sleeper():
time.sleep(1)
s = sleeper.bind()
serve.run(s)
while True:
requests.get("https://:8000/")
请求将一直循环,直到通过 Control-C 取消。
当此脚本运行时,请在浏览器中访问 localhost:8080。在输出中,您可以搜索 serve_ 来查找上述指标。指标默认每十秒更新一次,因此您需要刷新页面才能看到新值。指标报告间隔可以通过以下配置选项修改(请注意,这不是稳定的公共 API,可能会在不警告的情况下发生更改)
ray start --head --system-config='{"metrics_report_interval_ms": 1000}'
例如,在运行脚本一段时间并刷新 localhost:8080 后,您应该会找到类似以下的指标
ray_serve_deployment_processing_latency_ms_count{..., replica="sleeper#jtzqhX"} 48.0
ray_serve_deployment_processing_latency_ms_sum{..., replica="sleeper#jtzqhX"} 48160.6719493866
这表明平均处理延迟略高于一秒,正如预期的那样。
您甚至可以为部署定义一个 自定义指标,并用部署或副本元数据对其进行标记。这是一个示例
from ray import serve
from ray.serve import metrics
import time
import requests
@serve.deployment
class MyDeployment:
def __init__(self):
self.num_requests = 0
self.my_counter = metrics.Counter(
"my_counter",
description=("The number of odd-numbered requests to this deployment."),
tag_keys=("model",),
)
self.my_counter.set_default_tags({"model": "123"})
def __call__(self):
self.num_requests += 1
if self.num_requests % 2 == 1:
self.my_counter.inc()
my_deployment = MyDeployment.bind()
serve.run(my_deployment)
while True:
requests.get("https://:8000/")
time.sleep(1)
发出的日志包括
# HELP ray_my_counter_total The number of odd-numbered requests to this deployment.
# TYPE ray_my_counter_total counter
ray_my_counter_total{..., deployment="MyDeployment",model="123",replica="MyDeployment#rUVqKh"} 5.0
有关更多详细信息,包括使用 Prometheus 抓取这些指标的说明,请参阅 Ray 指标文档。
内存剖析#
Ray 提供了两个有用的指标来跟踪内存使用情况:ray_component_rss_mb(常驻集大小)和 ray_component_mem_shared_bytes(共享内存)。通过从常驻集大小中减去共享内存来近似 Serve actor 的内存使用情况(即 ray_component_rss_mb - ray_component_mem_shared_bytes)。
如果您注意到 Serve actor 存在内存泄漏,请使用 memray 进行调试(pip install memray)。设置环境变量 RAY_SERVE_ENABLE_MEMORY_PROFILING=1,然后运行您的 Serve 应用程序。所有 Serve actor 都将运行一个 memray 跟踪器,该跟踪器将它们的内存使用情况记录到 /tmp/ray/session_latest/logs/serve/ 目录中的 bin 文件中。运行 memray flamegraph [bin file] 命令来生成内存使用情况的火焰图。有关更多信息,请参阅 memray 文档。
将指标导出到 Arize#
除了使用 Prometheus 来查看 Ray 指标之外,Ray Serve 还可以灵活地将指标导出到其他可观测性平台。
Arize 是一个机器学习可观测性平台,它可以帮助您监控实时模型性能,通过可解释性与切片分析来追溯模型故障/性能下降,并发现漂移、数据质量、数据一致性问题等。
要与 Arize 集成,请将 Arize 客户端代码直接添加到您的 Serve 部署代码中。(示例代码)