优化性能#
没有加速#
你刚刚使用 Ray 运行了一个应用,但速度不如预期。更糟的是,它甚至可能比串行版本的应用更慢!最常见的原因如下。
核心数: Ray 正在使用多少个核心?启动 Ray 时,它会使用
psutil.cpu_count()确定每台机器的 CPU 数量。Ray 通常不会调度的并行任务数超过 CPU 数量。因此,如果 CPU 数量是 4,最多可以期待 4 倍的加速。物理 CPU 与逻辑 CPU: 你运行的机器是否物理核心数少于逻辑核心数?你可以使用
psutil.cpu_count()检查逻辑核心数,使用psutil.cpu_count(logical=False)检查物理核心数。这在很多机器上很常见,尤其是在 EC2 上。对于许多工作负载(尤其是数值计算工作负载),通常不能期待比物理 CPU 数量更高的加速。小任务: 你的任务是否非常小?Ray 为每个任务引入了一些开销(开销的大小取决于传入的参数)。如果你的任务执行时间少于十毫秒,你将不太可能看到加速。对于许多工作负载,你可以通过将任务批量处理来轻松增加任务大小。
可变时长: 你的任务是否时长可变?如果你并行运行 10 个时长可变的任务,不应该期待 N 倍的加速(因为你最终会等待最慢的任务)。在这种情况下,考虑使用
ray.wait来优先处理先完成的任务。多线程库: 你的所有任务是否都试图使用机器上的所有核心?如果是这样,它们很可能会遇到资源争用,从而阻止你的应用实现加速。这在某些版本的
numpy中很常见。为避免争用,请设置一个环境变量,例如MKL_NUM_THREADS(或根据你的安装情况设置等效变量)为1。对于许多(但非全部)库,你可以在应用运行时打开
top来诊断此问题。如果一个进程使用了大部分 CPU,而其他进程只使用了少量 CPU,这可能是问题所在。最常见的例外是 PyTorch,它看起来会使用所有核心,尽管需要调用torch.set_num_threads(1)来避免争用。
如果你仍然遇到速度变慢的问题,但上述问题都不适用,请务必告知我们!创建一个 GitHub issue,并提交一个最小的代码示例来演示问题。
本文讨论了人们在使用 Ray 时遇到的一些常见问题以及一些已知问题。如果你遇到其他问题,请告诉我们。
使用 Ray Timeline 可视化任务#
查看 如何在 Dashboard 中使用 Ray Timeline 了解更多详情。
除了使用 Dashboard UI 下载追踪文件,你还可以通过在命令行运行 ray timeline 或通过 Python API 运行 ray.timeline 将追踪文件导出为 JSON 文件。
import ray
ray.init()
ray.timeline(filename="timeline.json")
Dashboard 中的 Python CPU 性能分析#
使用 Ray dashboard,你可以通过点击活动 worker、actor 和 job 的“堆栈跟踪”或“CPU 火焰图”操作来分析 Ray worker 进程。
点击“堆栈跟踪”会使用 py-spy 返回当前的堆栈跟踪样本。默认情况下,只显示 Python 堆栈跟踪。要显示原生代码帧,请设置 URL 参数 native=1(仅在 Linux 上支持)。
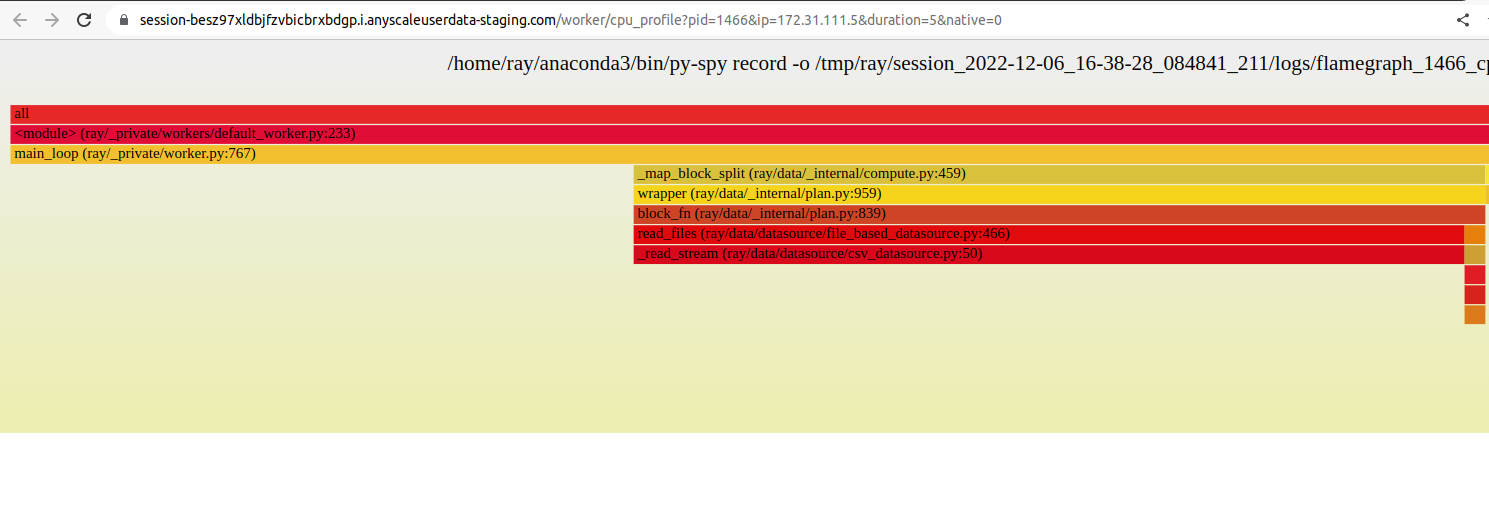
点击“CPU 火焰图”会获取多个堆栈跟踪样本,并将它们组合成火焰图可视化。此火焰图有助于理解特定进程的 CPU 活动。要调整火焰图的持续时间,可以更改 URL 中的 duration 参数。类似地,可以更改 native 参数以启用原生性能分析。
性能分析功能需要安装 py-spy。如果未安装,或者 py-spy 二进制文件没有 root 权限,Dashboard 会提示如何正确设置 py-spy 的说明
This command requires `py-spy` to be installed with root permissions. You
can install `py-spy` and give it root permissions as follows:
$ pip install py-spy
$ sudo chown root:root `which py-spy`
$ sudo chmod u+s `which py-spy`
Alternatively, you can start Ray with passwordless sudo / root permissions.
注意
在 docker 容器中使用 py-spy 时可能会遇到权限错误。要解决此问题
如果你在 Docker 容器中手动启动 Ray,请遵循 py-spy 文档 来解决它。
如果你是 KubeRay 用户,请遵循 配置 KubeRay 的指南 来解决它。
使用 Python 的 cProfile 进行性能分析#
你可以使用 Python 原生的 cProfile 性能分析模块 来分析 Ray 应用的性能。cProfile 不会逐行跟踪你的应用代码,而是可以给出每个循环函数的总运行时长,并列出被分析代码中所有函数调用的次数和执行时间。
与上面提到的 line_profiler 不同,这个详细的被分析函数调用列表包括 Ray 内部的函数调用。
然而,与 line_profiler 类似,只需对应用代码进行少量修改(前提是你想要分析的每段代码都定义为单独的函数),即可启用 cProfile。要使用 cProfile,添加 import 语句,然后按如下方式替换对循环函数的调用
import cProfile # Added import statement
def ex1():
list1 = []
for i in range(5):
list1.append(ray.get(func.remote()))
def main():
ray.init()
cProfile.run('ex1()') # Modified call to ex1
cProfile.run('ex2()')
cProfile.run('ex3()')
if __name__ == "__main__":
main()
现在,当你执行 Python 脚本时,每次调用 cProfile.run() 时,终端上都会打印出 cProfile 的被分析函数调用列表。cProfile 输出的最顶部会给出 'ex1()' 的总执行时间
601 function calls (595 primitive calls) in 2.509 seconds
以下是 'ex1()' 的被分析函数调用片段。这些调用大多数都很快速,大约需要 0.000 秒,因此感兴趣的函数是那些执行时间非零的函数
ncalls tottime percall cumtime percall filename:lineno(function)
...
1 0.000 0.000 2.509 2.509 your_script_here.py:31(ex1)
5 0.000 0.000 0.001 0.000 remote_function.py:103(remote)
5 0.000 0.000 0.001 0.000 remote_function.py:107(_remote)
...
10 0.000 0.000 0.000 0.000 worker.py:2459(__init__)
5 0.000 0.000 2.508 0.502 worker.py:2535(get)
5 0.000 0.000 0.000 0.000 worker.py:2695(get_global_worker)
10 0.000 0.000 2.507 0.251 worker.py:374(retrieve_and_deserialize)
5 0.000 0.000 2.508 0.502 worker.py:424(get_object)
5 0.000 0.000 0.000 0.000 worker.py:514(submit_task)
...
Ray 的 get 的 5 次独立调用,每次调用耗时 0.502 秒,可以在 worker.py:2535(get) 处注意到。同时,在 remote_function.py:103(remote) 处调用远程函数本身,在 5 次调用中总共只耗时 0.001 秒,因此这并不是 ex1() 性能缓慢的原因。
使用 cProfile 分析 Ray Actor#
考虑到 cProfile 的详细输出会因我们使用的 Ray 功能而有很大差异,让我们看看如果我们的示例涉及 Actor(Ray actor 的介绍请参见我们的 Actor 文档),cProfile 的输出会是什么样子。
现在,不像 ex1 中那样循环调用远程函数五次,让我们创建一个新示例,循环调用在一个 actor 内部的远程函数五次。我们的 actor 的远程函数同样只是休眠 0.5 秒
# Our actor
@ray.remote
class Sleeper:
def __init__(self):
self.sleepValue = 0.5
# Equivalent to func(), but defined within an actor
def actor_func(self):
time.sleep(self.sleepValue)
回顾 ex1 的次优表现,让我们首先看看如果我们在单个 actor 中尝试执行所有五次 actor_func() 调用会发生什么
def ex4():
# This is suboptimal in Ray, and should only be used for the sake of this example
actor_example = Sleeper.remote()
five_results = []
for i in range(5):
five_results.append(actor_example.actor_func.remote())
# Wait until the end to call ray.get()
ray.get(five_results)
我们按如下方式对此示例启用 cProfile
def main():
ray.init()
cProfile.run('ex4()')
if __name__ == "__main__":
main()
运行我们的新 Actor 示例,cProfile 的简略输出如下
12519 function calls (11956 primitive calls) in 2.525 seconds
ncalls tottime percall cumtime percall filename:lineno(function)
...
1 0.000 0.000 0.015 0.015 actor.py:546(remote)
1 0.000 0.000 0.015 0.015 actor.py:560(_remote)
1 0.000 0.000 0.000 0.000 actor.py:697(__init__)
...
1 0.000 0.000 2.525 2.525 your_script_here.py:63(ex4)
...
9 0.000 0.000 0.000 0.000 worker.py:2459(__init__)
1 0.000 0.000 2.509 2.509 worker.py:2535(get)
9 0.000 0.000 0.000 0.000 worker.py:2695(get_global_worker)
4 0.000 0.000 2.508 0.627 worker.py:374(retrieve_and_deserialize)
1 0.000 0.000 2.509 2.509 worker.py:424(get_object)
8 0.000 0.000 0.001 0.000 worker.py:514(submit_task)
...
结果显示,整个示例仍然花费了 2.5 秒执行,这相当于五次 actor_func() 调用串行运行的时间。如果你回想 ex1,这种行为是因为我们在提交所有五个远程函数任务后并没有等待再调用 ray.get(),但我们可以在 cProfile 的输出行 worker.py:2535(get) 验证,ray.get() 仅在最后调用了一次,耗时 2.509 秒。发生了什么?
结果显示 Ray 无法并行化此示例,因为我们只初始化了一个 Sleeper actor。由于每个 actor 都是一个单一的有状态 worker,我们的整个代码都是提交并在同一个 worker 上运行的。
为了更好地并行化 ex4 中的 actor,我们可以利用 actor_func() 的每次调用都是独立的特点,而是创建五个 Sleeper actor。这样,我们创建了五个可以并行运行的 worker,而不是创建一个一次只能处理一个 actor_func() 调用的 worker。
def ex4():
# Modified to create five separate Sleepers
five_actors = [Sleeper.remote() for i in range(5)]
# Each call to actor_func now goes to a different Sleeper
five_results = []
for actor_example in five_actors:
five_results.append(actor_example.actor_func.remote())
ray.get(five_results)
现在我们的示例总共只需 1.5 秒即可运行
1378 function calls (1363 primitive calls) in 1.567 seconds
ncalls tottime percall cumtime percall filename:lineno(function)
...
5 0.000 0.000 0.002 0.000 actor.py:546(remote)
5 0.000 0.000 0.002 0.000 actor.py:560(_remote)
5 0.000 0.000 0.000 0.000 actor.py:697(__init__)
...
1 0.000 0.000 1.566 1.566 your_script_here.py:71(ex4)
...
21 0.000 0.000 0.000 0.000 worker.py:2459(__init__)
1 0.000 0.000 1.564 1.564 worker.py:2535(get)
25 0.000 0.000 0.000 0.000 worker.py:2695(get_global_worker)
3 0.000 0.000 1.564 0.521 worker.py:374(retrieve_and_deserialize)
1 0.000 0.000 1.564 1.564 worker.py:424(get_object)
20 0.001 0.000 0.001 0.000 worker.py:514(submit_task)
...
使用 PyTorch Profiler 进行 GPU 性能分析#
以下是在使用 Ray Train 进行训练或使用 Ray Data 进行批量推理时使用 PyTorch Profiler 的步骤
遵循 PyTorch Profiler 文档 在你的 PyTorch 代码中记录事件。
将你的 PyTorch 脚本转换为 Ray Train 训练脚本 或 Ray Data 批量推理脚本。(与 profiler 相关的代码无需更改)
运行你的训练或批量推理脚本。
从所有节点收集性能分析结果(相对于非分布式设置中的 1 个节点)。
你可能需要将每个节点上的结果上传到 NFS 或对象存储(如 S3),这样就不必分别从每个节点获取结果了。
使用 Tensorboard 等工具可视化结果。
使用 Nsight System Profiler 进行 GPU 性能分析#
GPU 性能分析对于 ML 训练和推理至关重要。Ray 允许用户将 Nsight System Profiler 与 Ray actor 和任务一起运行。参阅详情。
面向开发者的性能分析#
如果你正在开发 Ray Core 或调试某些系统级故障,对 Ray Core 进行性能分析可能会有所帮助。在这种情况下,请参阅 面向 Ray 开发者的性能分析。