Ray Dashboard#
Ray 提供了一个基于 Web 的仪表盘,用于监控和调试 Ray 应用。系统状态的可视化表示允许用户跟踪应用性能和解决问题。
设置 Dashboard#
要访问仪表盘,请使用 ray[default] 或包含 Ray Dashboard 组件的其他安装命令。例如
pip install -U "ray[default]"
在您的笔记本电脑上启动单节点 Ray 集群时,可以通过 Ray 初始化时打印的 URL(默认 URL 为 https://:8265)或通过 ray.init 返回的上下文对象访问仪表盘。
import ray
context = ray.init()
print(context.dashboard_url)
127.0.0.1:8265
INFO worker.py:1487 -- Connected to Ray cluster. View the dashboard at 127.0.0.1:8265.
注意
如果您在 Docker 容器中启动 Ray,--dashboard-host 是必需参数。例如,ray start --head --dashboard-host=0.0.0.0。
当您使用 VM 集群启动器、KubeRay operator 或手动配置启动远程 Ray 集群时,Ray Dashboard 会在头节点上启动,但仪表盘端口可能不会公开暴露。请参阅配置仪表盘以了解如何在头节点外部查看仪表盘。
注意
使用 Ray Dashboard 时,强烈建议同时设置 Prometheus 和 Grafana。它们对于诸如指标视图等关键功能是必需的。请参阅配置和管理 Dashboard,了解如何将 Prometheus 和 Grafana 与 Ray Dashboard 集成。
作业视图#
作业视图让您可以监控在 Ray 集群上运行的不同 Job。Ray Job 是使用 Ray API(例如,ray.init)的 Ray 工作负载。建议通过Ray Job API 将您的 Job 提交到集群。您也可以交互式地运行 Ray Job(例如,通过在头节点中执行 Python 脚本)。
作业视图显示活动、已完成和失败 Job 的列表,点击 ID 可以查看该 Job 的详细信息。有关 Ray Job 的更多信息,请参阅Ray Job 概述部分。
作业性能分析#
您可以通过点击“堆栈跟踪”或“CPU 火焰图”操作来分析 Ray Job。请参阅性能分析了解更多详情。
Task 和 Actor 明细#

作业视图按状态分解 Task 和 Actor。Task 和 Actor 默认分组和嵌套。您可以通过点击展开按钮查看嵌套条目。
Task 和 Actor 根据以下标准进行分组和嵌套
所有 Task 和 Actor 都被分组在一起。展开相应的行可以查看单个条目。
Task 按其
name属性分组(例如,task.options(name="<name_here>").remote())。子 Task(嵌套 Task)嵌套在其父 Task 的行下。
Actor 按其类名分组。
子 Actor(在 Actor 内部创建的 Actor)嵌套在其父 Actor 的行下。
Actor Task(Actor 中的远程方法)嵌套在相应 Actor 方法的 Actor 下。
注意
作业详情页面每个 Job 最多只能显示或检索 1 万个 Task。对于超过 1 万个 Task 的 Job,超出 1 万限制的部分 Task 不会计数。未计数 Task 的数量可以在 Task 明细中找到。
Task 时间线#
首先,点击下载按钮下载 chrome tracing 文件。或者,您可以使用CLI 或 SDK 导出 tracing 文件。
其次,使用 chrome://tracing 或 Perfetto UI 等工具并拖入下载的 chrome tracing 文件。我们将使用 Perfetto,因为它是可视化 chrome tracing 文件的推荐方式。
在 Ray Task 和 Actor 的时间线可视化中,有 Node 行(硬件)和 Worker 行(进程)。每个 Worker 行显示该 Worker 在一段时间内发生的 Task 事件列表(例如,Task 已调度、Task 正在运行、输入/输出反序列化等)。
Ray 状态#
作业视图显示 Ray 集群的状态。此信息是 ray status CLI 命令的输出。
左侧面板显示自动扩缩容状态,包括待处理、活动和失败的节点。右侧面板显示资源需求,即当前无法调度到集群的资源。此页面对于调试资源死锁或慢调度很有用。
注意
输出显示集群的聚合信息(而非按 Job 分组)。如果运行多个 Job,部分需求可能来自其他 Job。
Task、Actor 和 Placement Group 表#
Dashboard 显示 Job 的 Task、Actor 和 Placement Group 的状态表。此信息是Ray State API 的输出。
您可以展开表格查看每个 Task、Actor 和 Placement Group 的列表。
Serve 视图#
查看您的通用 Serve 配置、Serve 应用列表,以及如果您配置了Grafana 和 Prometheus,您 Serve 应用的高级指标。点击 Serve 应用名称可转到 Serve 应用详情页面。
Serve 应用详情页面#
查看 Serve 应用的配置和元数据以及Serve 部署和副本列表。点击部署的展开按钮可查看副本。
每个部署都有两个可用操作。您可以查看部署配置,如果您配置了Grafana 和 Prometheus,您可以打开一个 Grafana 仪表盘,查看该部署的详细指标。
对于每个副本,有两个可用操作。您可以查看该副本的日志,如果您配置了Grafana 和 Prometheus,您可以打开一个 Grafana 仪表盘,查看该副本的详细指标。点击副本名称可转到 Serve 副本详情页面。
Serve 副本详情页面#
此页面显示有关 Serve 副本的元数据、如果您配置了Grafana 和 Prometheus,则显示有关该副本的高级指标,以及该副本已完成Task的历史记录。
Serve 指标#
Ray Serve 导出各种时间序列指标,以帮助您了解 Serve 应用随时间变化的状态。您可以在此处找到有关这些指标的更多详细信息。要存储和可视化这些指标,请按照此处的说明设置 Prometheus 和 Grafana。
这些指标可在 Ray Dashboard 的 Serve 页面和 Serve 副本详情页面中找到。它们也可以作为 Grafana 仪表盘访问。在 Grafana 仪表盘中,使用顶部的下拉过滤器按路由、部署或副本筛选指标。通过将鼠标悬停在每个图表左上角的“信息”图标上,可以找到每个图表的精确描述。
集群视图#
集群视图是机器(节点)和 Worker(进程)层级关系的可视化。每个主机由多个 Worker 组成,您可以通过点击 + 按钮查看。另请参阅 GPU 资源如何分配给特定的 Actor 或 Task。
点击节点 ID 可以查看节点详情页面。
此外,机器视图允许您查看节点或 Worker 的日志。
Actors 视图#
使用 Actors 视图可以查看 Actor 的日志以及创建该 Actor 的 Job。
最多存储 10 万个已终止 Actor 的信息。在启动 Ray 时,可以使用 RAY_maximum_gcs_destroyed_actor_cached_count 环境变量覆盖此值。
Actor 性能分析#
在运行中的 Actor 上运行性能分析器。请参阅Dashboard 性能分析了解更多详情。
Actor 详情页面#
点击 ID,查看 Actor 的详细视图。
在 Actor 详情页面,可以查看 Actor 的元数据、状态以及所有已运行的 Actor Task。
指标视图#
Ray 导出默认指标,这些指标可以在指标视图中查看。以下是一些可用的示例指标。
按状态分解的 Task、Actor 和 Placement Group
跨节点的逻辑资源使用情况
跨节点的硬件资源使用情况
自动扩缩容状态
请参阅系统指标页面了解可用指标。
注意
指标视图需要设置 Prometheus 和 Grafana。请参阅配置和管理 Dashboard,了解如何设置 Prometheus 和 Grafana。
指标视图提供 Ray 发出的时间序列指标的可视化。
您可以在右上角选择指标的时间范围。图表每隔 15 秒自动刷新。
Dashboard 中还有一个方便的按钮可以直接打开 Grafana UI。Grafana UI 提供了更多的图表自定义功能。
分析 Task 和 Actor 的 CPU 和内存使用情况#
Dashboard 中的指标视图提供了一个“按组件划分的 CPU/内存使用图”,它显示应用中每个 Task 和 Actor(以及系统组件)随时间变化的 CPU 和内存使用情况。您可以识别可能消耗超出预期的资源的 Task 和 Actor,并优化应用的性能。
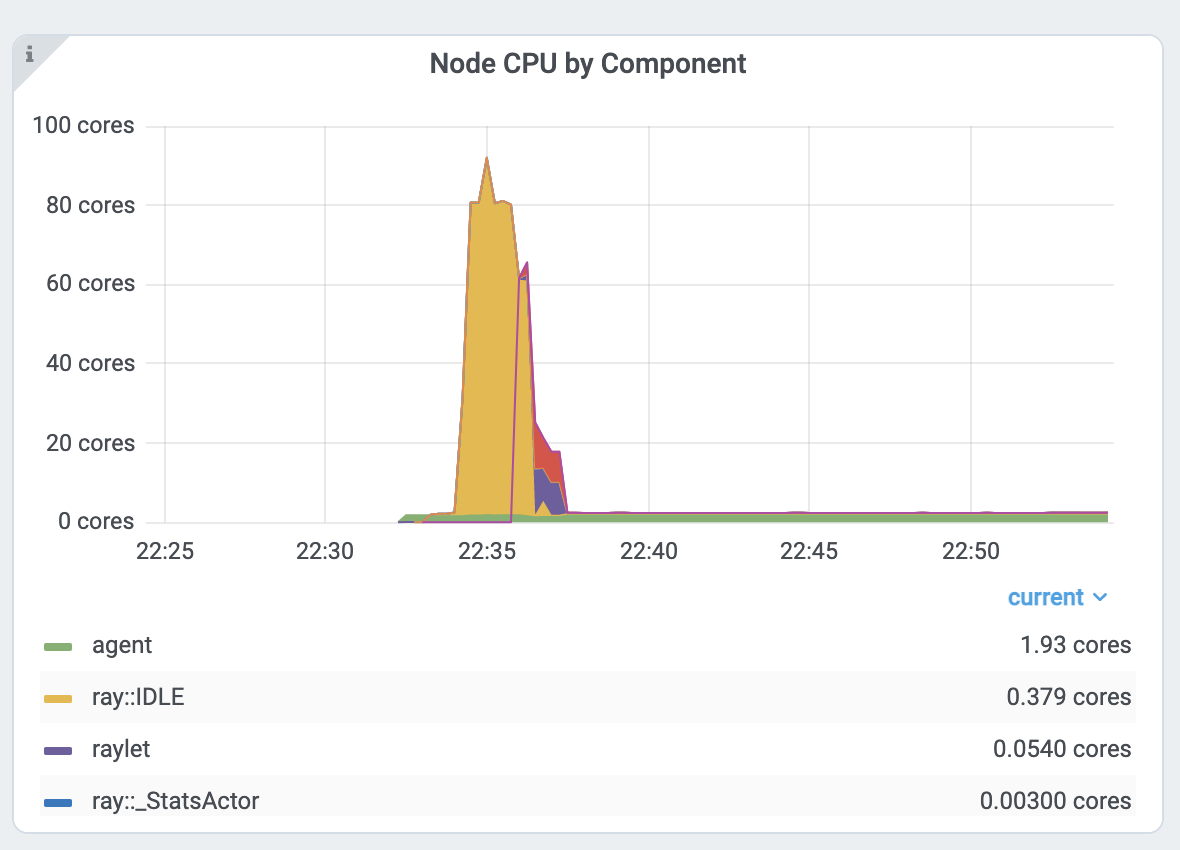
按组件划分的 CPU 图。0.379 个核心表示它使用了单个 CPU 核心的 40%。Ray 进程名称以 ray:: 开头。raylet、agent、dashboard 或 gcs 是系统组件。
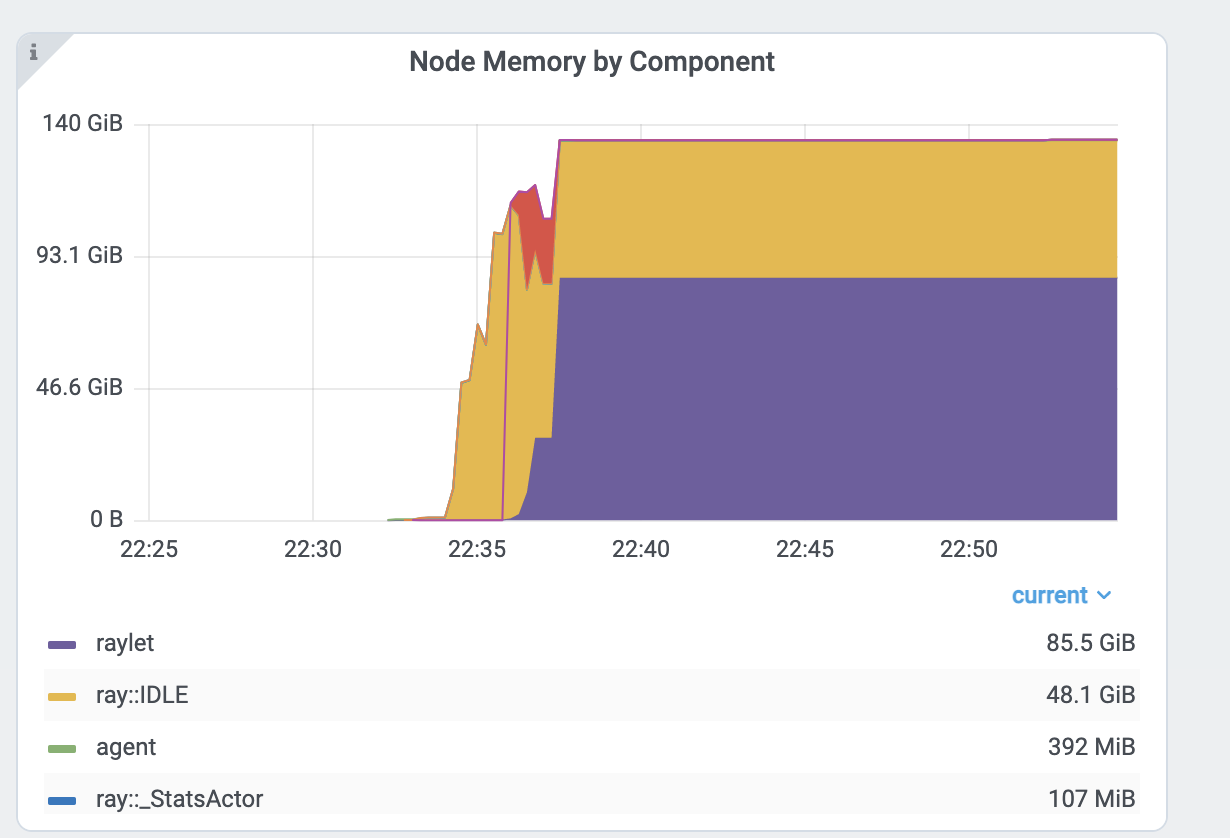
按组件划分的内存图。Ray 进程名称以 ray:: 开头。raylet、agent、dashboard 或 gcs 是系统组件。
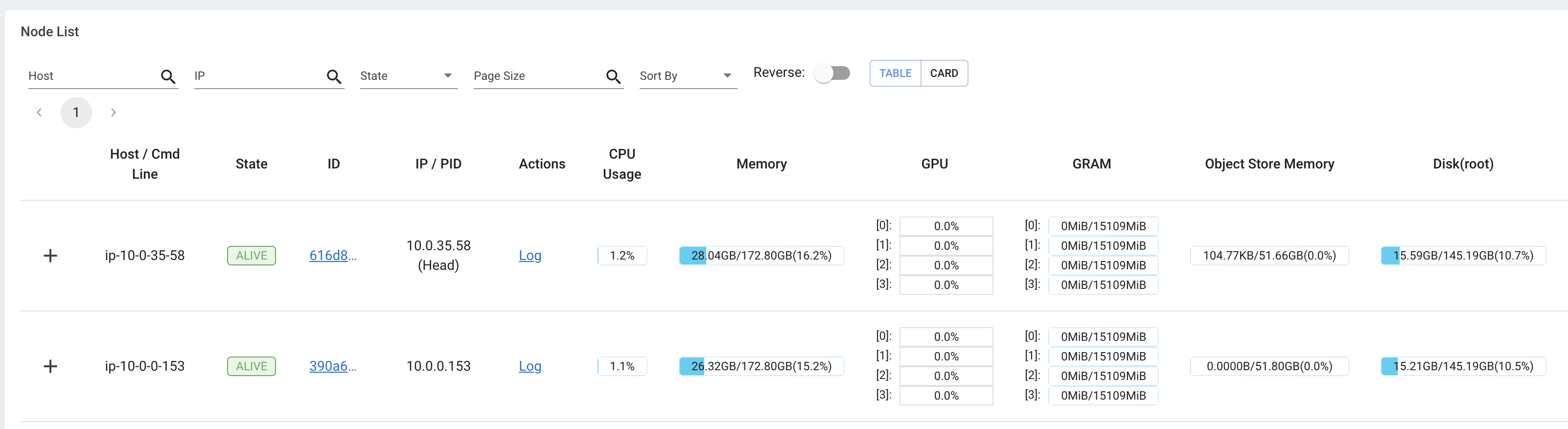
此外,用户可以从集群视图查看硬件利用率快照,这提供了整个 Ray 集群的资源使用概览。
查看资源利用率#
Ray 要求用户通过 num_cpus、num_gpus、memory 和 resource 等参数指定其 Task 和 Actor 要使用的资源数量。这些值用于调度,但可能并不总是与实际资源利用率(物理资源利用率)匹配。
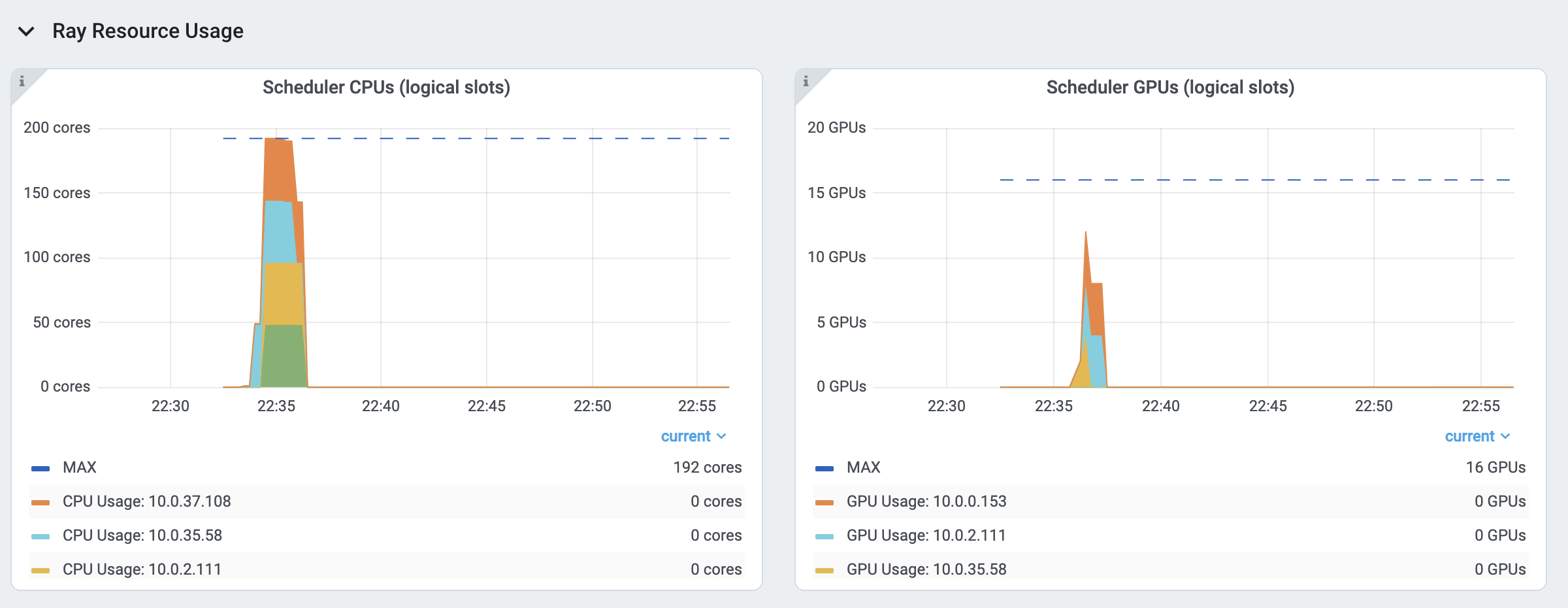
逻辑资源使用情况。
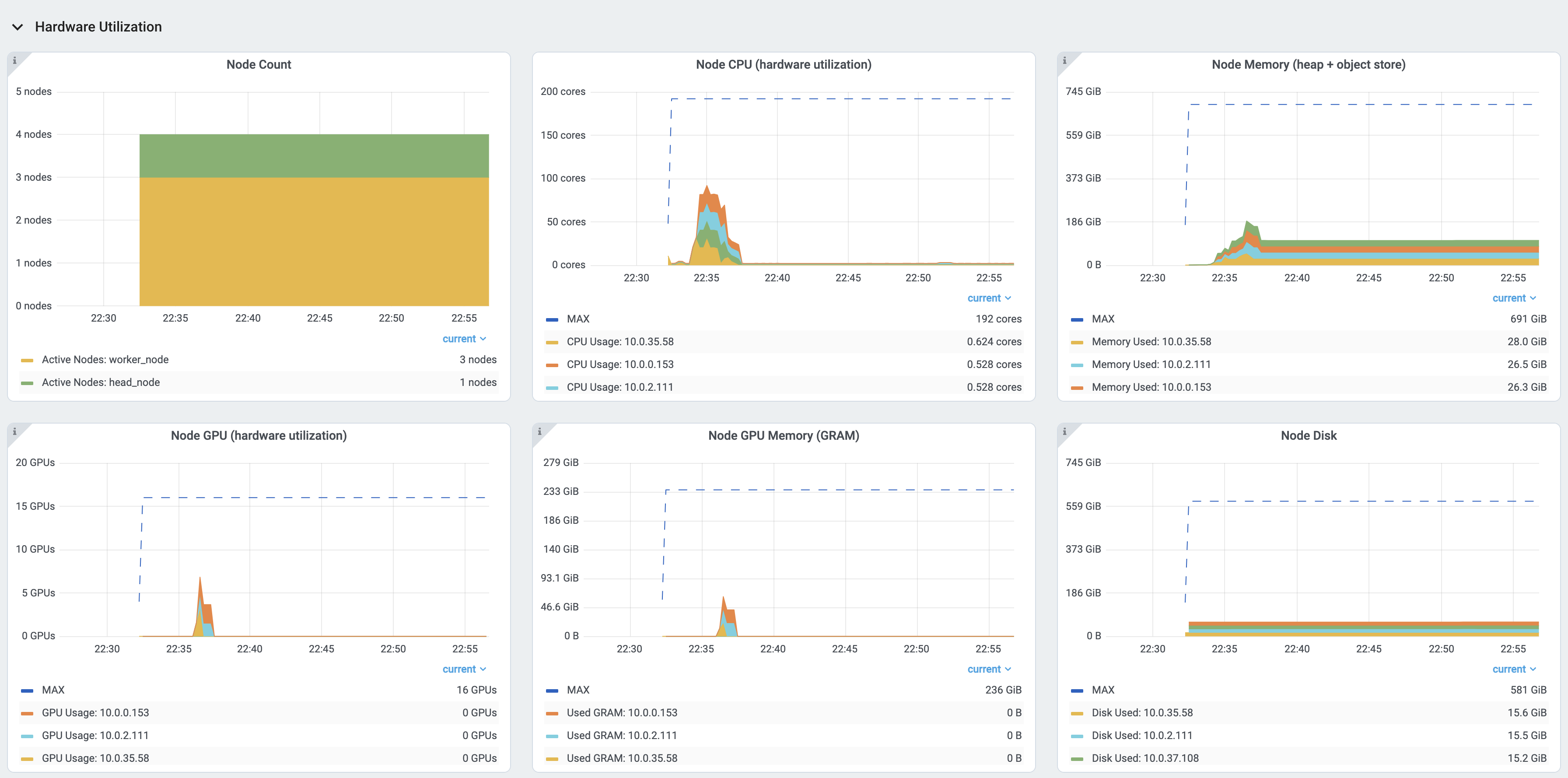
物理资源(硬件)使用情况。Ray 提供集群中每台机器的 CPU、GPU、内存、GRAM、磁盘和网络使用情况。
日志视图#
日志视图列出了集群中的 Ray 日志。它按节点和日志文件名组织。其他页面的许多日志链接会链接到此视图并过滤列表,以便显示相关日志。
要理解 Ray 的日志结构,请参阅日志目录和文件结构。
日志视图提供了搜索功能,帮助您查找特定的日志消息。
Driver 日志
如果 Ray Job 是通过Job API 提交的,则可以在 Dashboard 中获取 Job 日志。日志文件遵循以下格式:job-driver-<job_submission_id>.log。
注意
如果您直接在 Ray 集群的头节点上执行 Driver(不使用 Job API)或使用Ray Client 运行,则无法从 Dashboard 访问 Driver 日志。在这种情况下,请查看终端或 Jupyter Notebook 输出以查看 Driver 日志。
Task 和 Actor 日志 (Worker 日志)
Task 和 Actor 日志可以从Task 和 Actor 表视图访问。点击“日志”按钮。您可以查看包含 Task 和 Actor 输出的 stdout 和 stderr 日志。对于 Actor,您还可以查看相应 Worker 进程的系统日志。
注意
异步 Actor Task 或线程化 Actor Task(并发 > 1)的日志仅作为 Actor 日志的一部分可用。请按照 Dashboard 中的说明查看 Actor 日志。
Task 和 Actor 错误
通过查看 Job 进度条,您可以轻松识别失败的 Task 或 Actor。
Task 和 Actor 表格分别显示失败 Task 或 Actor 的名称。它们还提供对其相应日志或错误消息的访问。
概述视图#
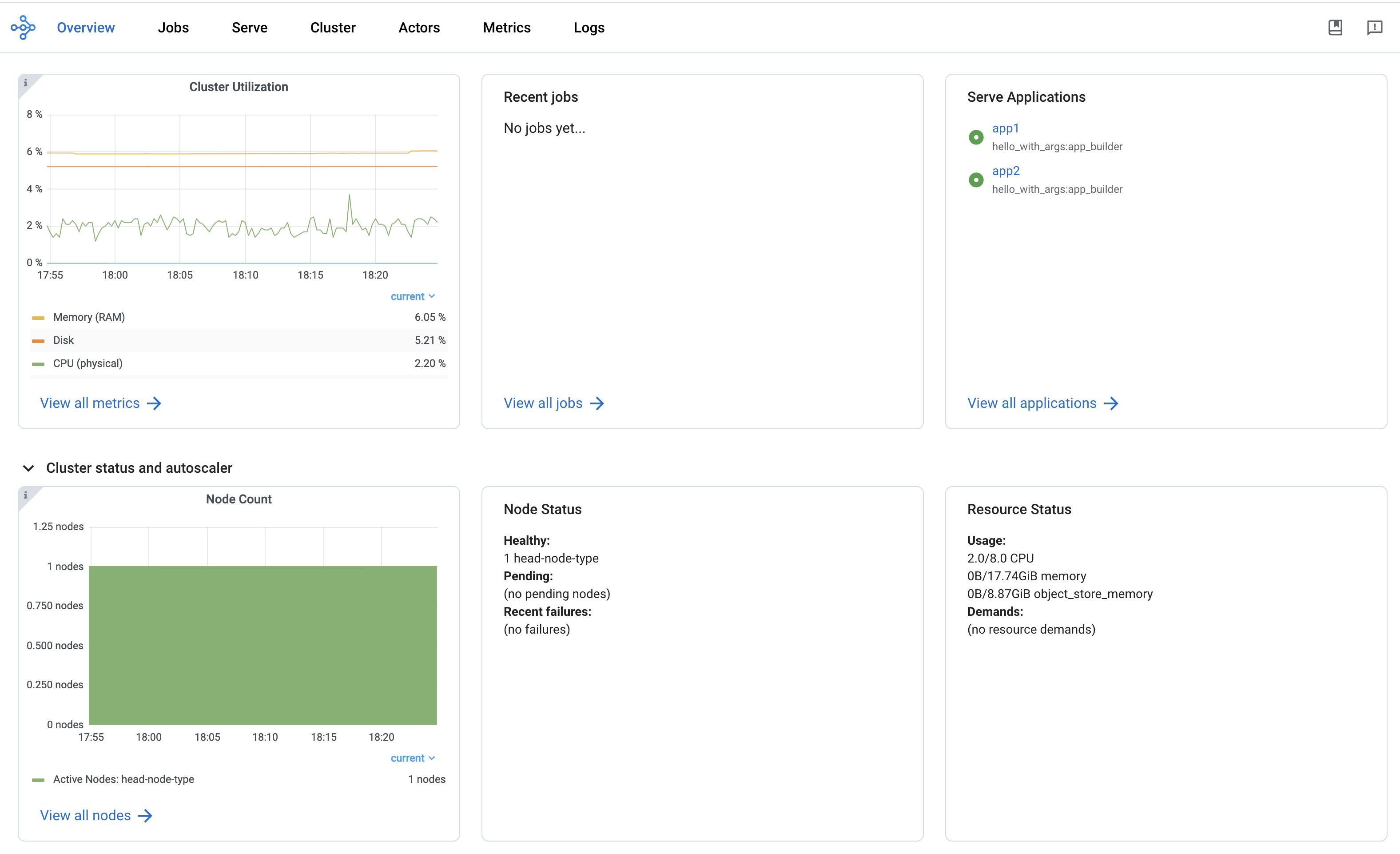
概述视图提供 Ray 集群的高级状态。
概述指标
概述指标页面提供集群级别的硬件利用率和自动扩缩容状态(待处理、活动和失败的节点数量)。
最近 Job
最近 Job 面板提供最近提交的 Ray Job 列表。
Serve 应用
Serve 应用面板提供最近部署的 Serve 应用列表
事件视图
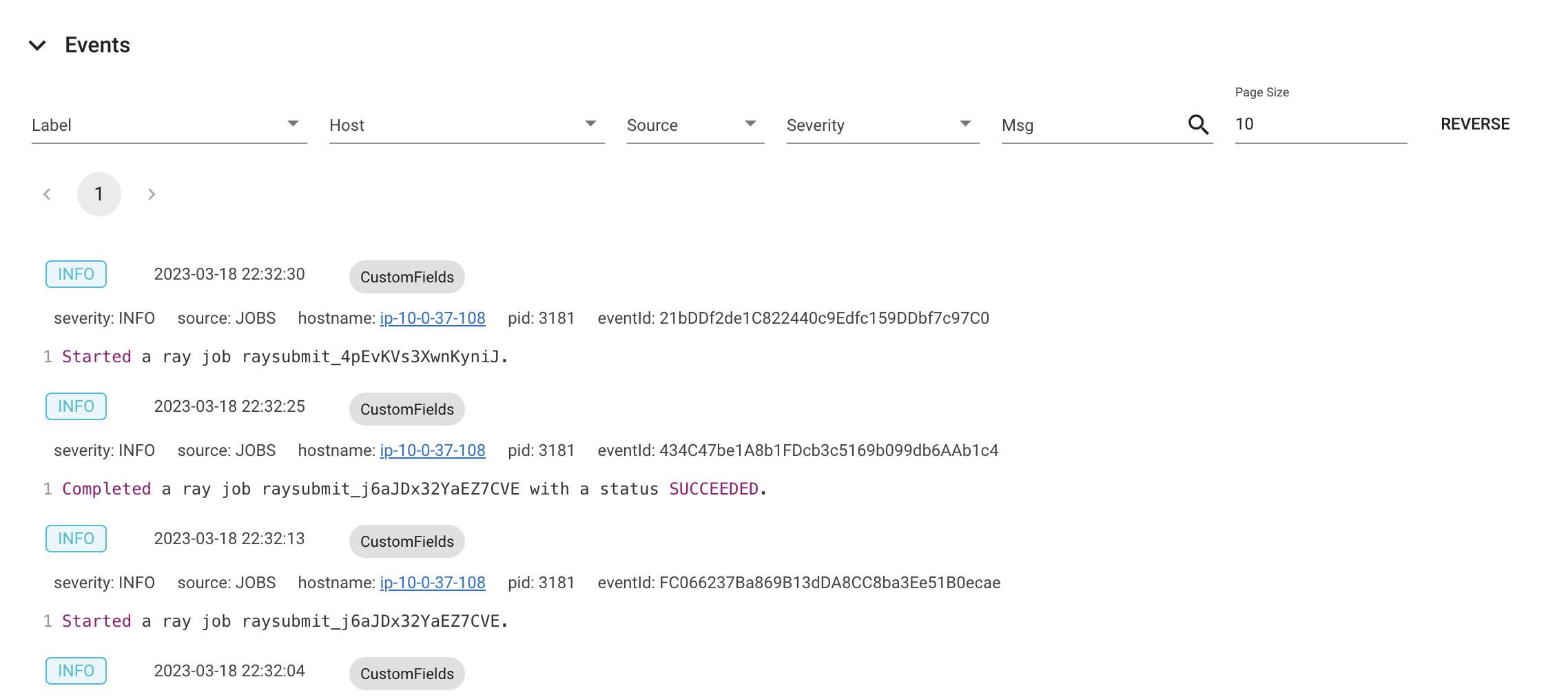
事件视图按时间顺序列出与特定类型(例如,自动扩缩容器或 Job)相关的事件。使用 ray list cluster-events(Ray State API)CLI 命令也可以访问相同的信息。
两种类型的事件可用
Job:与Ray Jobs API 相关的事件。
自动扩缩容器:与Ray 自动扩缩容器 相关的事件。