贡献 Ray 文档#
贡献 Ray 文档的方式有很多,我们始终欢迎新的贡献者。即使你只是想修正一个错别字或补充某个章节,请随时这样做!
本文档将引导你完成入门所需的一切。
编辑风格#
我们遵循 Google 开发者文档风格指南。以下是一些要点:
编辑风格由 CI 中的 Vale 强制执行。更多信息请参见 如何使用 Vale。
构建 Ray 文档#
如果你想为 Ray 文档做出贡献,你需要一种构建它的方法。**不要**在你计划用来构建文档的环境中安装 Ray。文档构建系统的要求通常与运行 Ray 本身所需的要求不兼容。
遵循以下说明来构建文档:
Fork Ray#
将 fork 的仓库克隆到你的本地机器
接着,切换到 ray/doc 目录
cd ray/doc
安装依赖项#
如果你还没有这样做,请创建一个与构建和运行 Ray 所使用的环境分开的 Python 环境,最好使用最新版本的 Python。例如,如果你使用 conda:
conda create -n docs python=3.12
接着,激活你正在使用的 Python 环境(例如,venv、conda 等)。如果使用 conda,命令如下:
conda activate docs
使用以下命令安装文档依赖项:
pip install -r requirements-doc.txt
在此步骤中**不要**使用 -U。你不需要升级依赖项,因为 requirements-doc.txt 固定了构建文档所需的精确版本。
构建文档#
在构建之前,先运行以下命令清理你的环境:
make clean
选择以下 2 个选项之一在本地构建文档:
增量构建
完全构建
1. 使用全局缓存和实时渲染进行增量构建#
要使用此选项,你可以运行:
make local
如果你需要频繁进行不复杂的小改动,例如编辑文本、在现有文件中添加内容等,建议使用此选项。
在这种方法中,Sphinx 只构建与你从上游 master 最后一次拉取相比,你在你的分支中所做的更改。文档的其余部分使用你从上游最后一次提交中预构建的文档页面进行缓存(对于推送给 Ray 的每一个新提交,CI 会构建该提交的所有文档页面,并将其存储在 S3 上作为缓存)。
构建首先追溯你的提交树,找到 CI 已在 S3 上缓存的最新提交。一旦构建找到该提交,它会从 S3 拉取相应的缓存并将其解压到 doc/ 目录中。同时,CI 会跟踪从该提交到当前 HEAD 的所有更改文件,包括任何未暂存的更改。
Sphinx 然后只重新构建受你的更改影响的页面,其余部分保留缓存中的内容。
构建完成后,文档页面会自动在你的浏览器中弹出。如果在 doc/ 目录中进行任何更改,Sphinx 会自动重新构建并重新加载你的文档页面。你可以通过按下 Ctrl+C 来停止它。
对于涉及添加或删除文件的更复杂的更改,请始终先使用 make develop,然后你可以开始使用 make local 来迭代 make develop 生成的缓存。
2. 从头开始完全构建#
在完全构建选项中,Sphinx 会重新构建 doc/ 目录中的所有文件,忽略所有缓存和保存的环境。由于这种行为,你可以获得一个非常干净的构建,但速度要慢得多。
make develop
在 _build 目录中找到文档构建结果。构建完成后,你可以简单地在浏览器中打开 _build/html/index.html 文件。检查构建的输出以确保一切正常工作被认为是良好的实践。
在提交任何更改之前,请确保从 doc 文件夹运行 ../scripts/format.sh 来执行 linter,以确保你的更改格式正确。
代码补全及其他开发者工具#
如果你经常处理文档,可能会发现 esbonio 语言服务器很有用。Esbonio 为 RST 文档提供上下文感知的语法补全、定义、诊断、文档链接以及其他信息。如果你不熟悉语言服务器,它们是现代开发者工具箱的重要组成部分;如果你之前使用过 pylance 或 python-lsp-server,你就会知道这些工具多么有用。
Esbonio 还提供一个 VSCode 扩展,其中包括实时预览功能。只需安装 esbonio VSCode 扩展即可开始使用该工具:
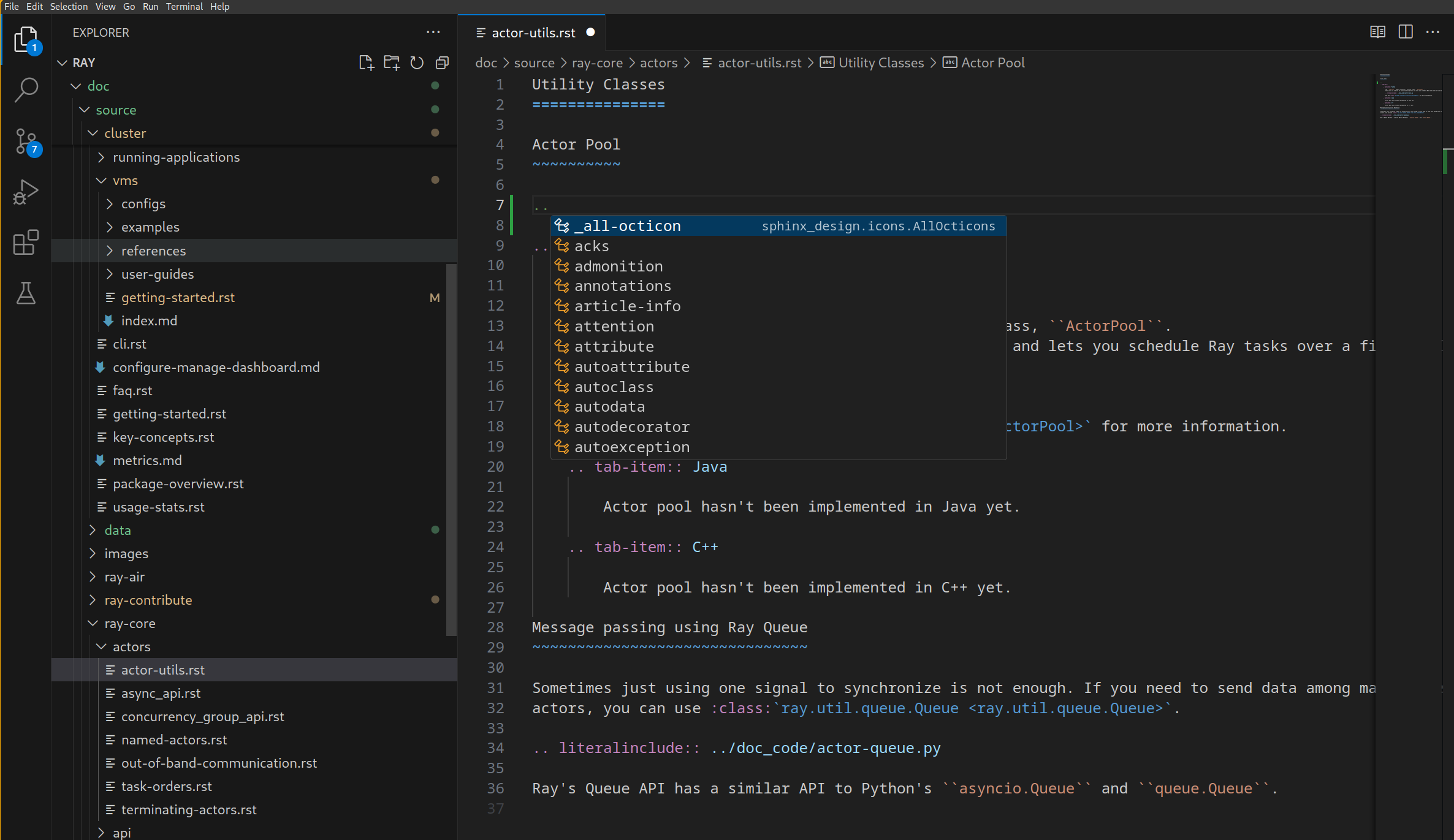
作为 Esbonio 自动补全功能的一个示例,你可以输入 .. 来调出所有 RST 指令的自动补全菜单:
Esbonio 也可以与 Neovim 一起使用 - 请参阅 lspconfig 仓库获取安装说明。
构建系统的基础知识#
Ray 文档使用 sphinx 构建系统构建。我们使用 PyData Sphinx Theme 作为文档的主题。
我们使用 myst-parser 允许你使用 Sphinx 原生的 reStructuredText (rST) 或 Markedly Structured Text (MyST) 来编写 Ray 文档。这两种格式可以相互转换,所以选择权在你。不过,重要的是要知道 MyST 兼容 CommonMark。过去的经验表明,大多数开发者熟悉 md 语法,所以如果你打算添加新文档,我们建议从 .md 文件开始。
Ray 文档也完全支持可执行格式,例如 Jupyter Notebooks。我们的许多示例都是带有 MyST Markdown 单元格的 Notebook。
贡献什么?#
以 Ray Tune 为例,你会看到我们的文档由几种类型的文档组成,所有这些你都可以贡献:
这种结构也反映在 Ray 文档源代码中,因此你应该很容易找到你想要的内容。所有其他 Ray 项目也都有类似的结构,但根据项目不同可能存在细微差异。
上述每种类型的文档都有其自身的用途,但最终我们的文档归结为*两种类型*:
修正错别字和改进解释#
如果你在任何文档中发现错别字,或者认为某个解释不够清晰,请考虑发起一个 pull request。在这种情况下,只需按上述说明运行 linter 并提交你的 pull request 即可。
添加 API 参考#
我们使用 Sphinx 的 autodoc 扩展 从我们的源代码生成 API 文档。如果遗漏了某个函数或类的引用,请考虑将其添加到相关的文档中。
例如,以下是如何使用 autofunction 和 autoclass 添加函数或类的引用:
.. autofunction:: ray.tune.integration.docker.DockerSyncer
.. autoclass:: ray.tune.integration.keras.TuneReportCallback
上述片段摘自 Tune API 文档,你可以参考该文档。
如果要更改 API 文档的内容,你必须直接在源代码中编辑相应的函数或类签名。例如,在上面的 autofunction 调用中,要更改 ray.tune.integration.docker.DockerSyncer 的 API 参考,你必须更改以下源文件。
为了展示 API 的用法,在 API 文档中嵌入小型的用法示例非常重要。这些示例应该是独立的,可以直接运行,以便用户可以将其复制粘贴到 Python 解释器中并进行试验(例如,如果适用,它们应该指向示例数据)。用户经常依赖这些示例来构建他们的应用程序。要了解有关编写示例的更多信息,请阅读 如何编写代码片段。
向 .rST 或 .md 文件添加代码#
修改现有文档文件中的文本很容易,但在添加代码时需要小心。原因是我们希望确保文档中的每一个代码片段都经过测试。这要求我们有一个在文档中包含和测试代码片段的流程。要学习如何编写可测试的代码片段,请阅读 如何编写代码片段。
from ray import train
def objective(x, a, b): # Define an objective function.
return a * (x ** 0.5) + b
def trainable(config): # Pass a "config" dictionary into your trainable.
for x in range(20): # "Train" for 20 iterations and compute intermediate scores.
score = objective(x, config["a"], config["b"])
train.report({"score": score}) # Send the score to Tune.
此代码通过 literalinclude 从名为 doc_code/key_concepts.py 的文件中导入。 doc_code 目录中的每个 Python 文件都将由我们的 CI 系统自动测试,但请确保先在本地运行你更改的脚本(或新脚本)。你无需在本地运行测试框架。
在少数情况下,当你添加*明显*的伪代码来演示概念时,可以直接将其字面量添加到你的 .rST 或 .md 文件中,例如使用 .. code-cell:: python 指令。但如果你的代码需要运行,则必须进行测试。
从头创建新文档#
有时你可能想向 Ray 文档添加一个全新的文档,例如添加一个新的用户指南或一个新的示例。
为了使其正常工作,你需要确保将新文档明确添加到父文档的 toctree 中,这决定了 Ray 文档的结构。有关更多信息,请参阅 sphinx 文档。
根据你添加的文档类型,你可能还需要修改现有的概览页面,该页面管理相关文档列表。例如,对于 Ray Tune,每个用户指南都作为一个面板添加到用户指南概览页面,所有 Tune 示例也是如此。请务必查看你正在处理的 Ray 子项目的文档结构,了解如何将其集成到现有结构中。在某些情况下,你可能需要为面板选择一张图片。图片位于 doc/source/images 中。
创建 Notebook 示例#
要向 Ray 文档添加新的可执行示例,你可以从我们的 MyST Notebook 模板或 Jupyter Notebook 模板开始。你也可以简单地下载你正在阅读的文档(单击页面顶部的相应下载按钮即可获取 .ipynb 文件)并开始修改。Ray Tune 中所有的示例 Notebook 都会由我们的 CI 系统自动测试,前提是你将它们放在 examples 文件夹中。如果你在为其他 Ray 子项目贡献 Notebook 时对如何测试有疑问,请务必在发起 pull request 时在 Ray 社区 Slack 或直接在 GitHub 上提问。
我们建议你从 .md 文件开始,并在流程结束时将文件转换为 .ipynb Notebook。我们将在下面逐步介绍此过程。
这些 Notebook 与其他文档的不同之处在于,它们将代码和文本结合在一个文档中,并且可以在浏览器中启动。在我们将其添加到文档之前,我们还会确保它们由我们的 CI 系统进行测试。为了实现这一点,Notebook 需要定义一个*内核规范*来告诉 Notebook 服务器如何解释和运行代码。例如,以下是 Python Notebook 的内核规范:
---
jupytext:
text_representation:
extension: .md
format_name: myst
kernelspec:
display_name: Python 3
language: python
name: python3
---
如果你以 .md 格式编写 Notebook,则需要在文件顶部添加此 YAML front matter。要将代码添加到你的 Notebook 中,可以使用 code-cell 指令。示例如下:
```python
import ray
import ray.rllib.agents.ppo as ppo
from ray import serve
def train_ppo_model():
trainer = ppo.PPOTrainer(
config={"framework": "torch", "num_workers": 0},
env="CartPole-v0",
)
# Train for one iteration
trainer.train()
trainer.save("/tmp/rllib_checkpoint")
return "/tmp/rllib_checkpoint/checkpoint_000001/checkpoint-1"
checkpoint_path = train_ppo_model()
```
将此 Markdown 块放入文档中,在浏览器中将渲染如下:
import ray
import ray.rllib.agents.ppo as ppo
from ray import serve
def train_ppo_model():
trainer = ppo.PPOTrainer(
config={"framework": "torch", "num_workers": 0},
env="CartPole-v0",
)
# Train for one iteration
trainer.train()
trainer.save("/tmp/rllib_checkpoint")
return "/tmp/rllib_checkpoint/checkpoint_000001/checkpoint-1"
checkpoint_path = train_ppo_model()
参考节标签#
参考节标签是一种从 Notebook 内部链接到文档特定部分的方式。在 Markdown 单元格中创建它们很简单:
(my-label)=
# The thing to label
然后,你可以使用以下语法在 .rst 文件中链接它:
See {ref}`the thing that I labeled <my-label>` for more information.
测试 Notebook#
移除单元格对于计算密集型 Notebook 尤其有用。我们希望你贡献使用*实际*值而非玩具示例的 Notebook。同时,我们希望我们的 Notebook 能够通过 CI 系统进行测试,并且运行时间不应过长。为了解决这个问题,你可以在 Notebook 中首先放置用户希望看到的参数的单元格:
```{code-cell} python3
num_workers = 8
num_gpus = 2
```
在浏览器中将渲染如下:
num_workers = 8
num_gpus = 2
但接着在你的 Notebook 中紧随其后的是一个*已移除*的单元格,它不会被渲染,但使用更小的值,使 Notebook 运行更快:
```{code-cell} python3
:tags: [remove-cell]
num_workers = 0
num_gpus = 0
```
将 Markdown Notebook 转换为 ipynb#
完成示例编写后,你可以使用 jupytext 将其转换为 .ipynb Notebook:
jupytext your-example.md --to ipynb
同样,你可以使用 --to myst 将 .ipynb Notebook 转换为 .md Notebook。如果你想将 Notebook 转换为 Python 文件,例如测试整个脚本是否无误运行,则可以使用 --to py。
如何使用 Vale#
什么是 Vale?#
Vale 检查你的写作是否符合 Google 开发者文档风格指南。目前仅在 Ray Data 文档中强制执行。
Vale 可以发现错别字和语法错误。它还会强制执行风格规则,例如“使用缩写”和“使用第二人称”。有关规则的完整列表,请参阅 Ray 仓库中的配置。
如何运行 Vale?#
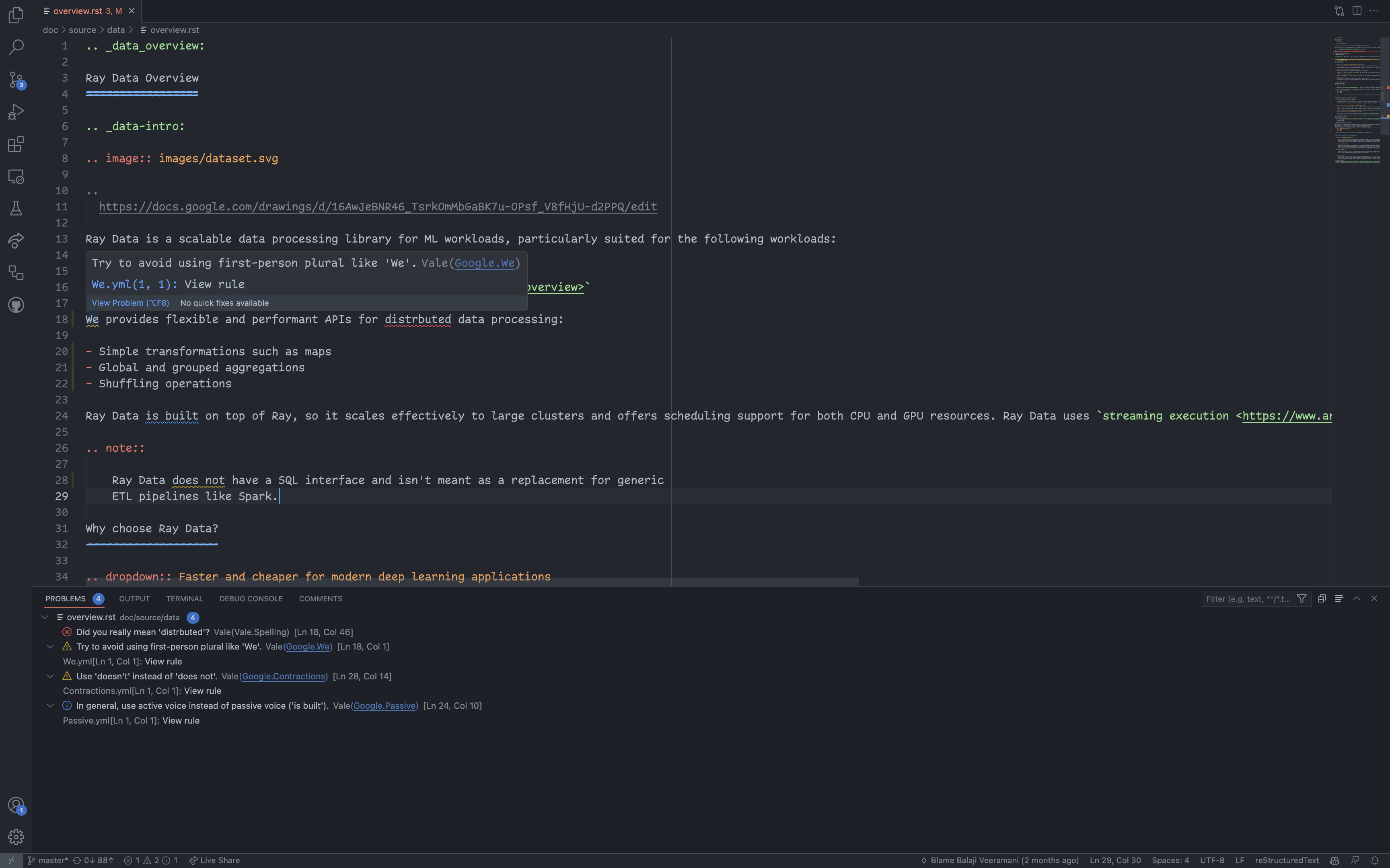
如何使用 VSCode 扩展#
如何在命令行上运行 Vale#
安装 Vale。如果你使用 macOS,请使用 Homebrew。
brew install vale
否则,使用 PyPI。
pip install vale
有关安装的更多信息,请参阅 Vale 文档。
在终端中运行 Vale:
vale doc/source/data/overview.rstVale 应该在你的终端中显示警告。
❯ vale doc/source/data/overview.rst doc/source/data/overview.rst 18:1 warning Try to avoid using Google.We first-person plural like 'We'. 18:46 error Did you really mean Vale.Spelling 'distrbuted'? 24:10 suggestion In general, use active voice Google.Passive instead of passive voice ('is built'). 28:14 warning Use 'doesn't' instead of 'does Google.Contractions not'. ✖ 1 error, 2 warnings and 1 suggestion in 1 file.
如何处理误报的 Vale.Spelling 错误#
要添加自定义术语,请完成以下步骤:
如果尚不存在,请在
.vale/styles/Vocab中为你团队创建一个目录。例如,.vale/styles/Vocab/Data。如果尚不存在,请创建一个名为
accept.txt的文本文件。例如,.vale/styles/Vocab/Data/accept.txt。将你的术语添加到
accept.txt中。Vale 支持正则表达式。
有关更多信息,请参阅 Vale 文档中的 词汇表 (Vocabularies)。
如何处理误报的 Google.WordList 错误#
如果你使用了 Google 词汇表中没有的词,Vale 会报错。
304:52 error Use 'select' instead of Google.WordList
'check'.
如果你仍然想使用这个词,请修改 WordList 配置中的相应字段。
故障排除#
如果你在构建文档时遇到问题,遵循以下步骤可以帮助隔离或消除大多数问题:
清除构建产物。 使用
make clean清除工作目录中的文档构建产物。Sphinx 使用缓存来避免重复工作,这有时会导致问题。如果你构建了文档,然后执行git pull origin master拉取最新更改,然后尝试再次构建文档,这种情况尤为常见。检查你的环境。 使用
pip list检查已安装的依赖项。将其与doc/requirements-doc.txt进行比较。文档构建系统与 Ray 的依赖项要求不同。构建文档不需要运行 ML 模型或在分布式系统上执行代码。实际上,最好使用一个与运行 Ray 的环境完全分开的文档构建环境,以避免依赖冲突。安装依赖项时,执行pip install -r doc/requirements-doc.txt。不要使用-U,因为你不想在安装过程中升级任何依赖项。确保使用现代版本的 Python。 文档构建系统与 Ray 的依赖项和 Python 版本要求不同。构建文档时请使用现代版本的 Python。较新版本的 Python 可能比先前版本快得多。请查阅 https://endoflife.date/python 以获取最新的版本支持信息。
在 Sphinx 中启用断点。 在
doc/Makefile中的SPHINXOPTS中添加 -P,以告诉sphinx在遇到断点时停止;并移除-j auto以禁用并行构建。现在你可以在你尝试导入的模块中或sphinx代码本身中设置断点,这有助于隔离顽固的构建问题。[增量构建] 侧边导航栏不反映新页面 如果你添加新页面,它们应该总是显示在索引页面的侧边导航栏中。然而,使用
make local进行增量构建会跳过重新构建许多其他页面,因此 Sphinx 不会更新这些页面的侧边导航栏。要在所有页面上构建具有正确侧边导航栏的文档,请考虑使用make develop。
接下来可以做什么?#
除了文档之外,还有许多其他方法可以为 Ray 做出贡献。有关更多信息,请参阅 我们的贡献者指南。