数据加载与预处理#
Ray Train 与 Ray Data 集成,提供高性能、可扩展的流式解决方案,用于加载和预处理大型数据集。主要优势包括:
流式数据加载和预处理,可扩展至拍字节级别的数据。
将繁重的数据预处理扩展到 CPU 节点,避免成为 GPU 训练的瓶颈。
自动快速的故障恢复。
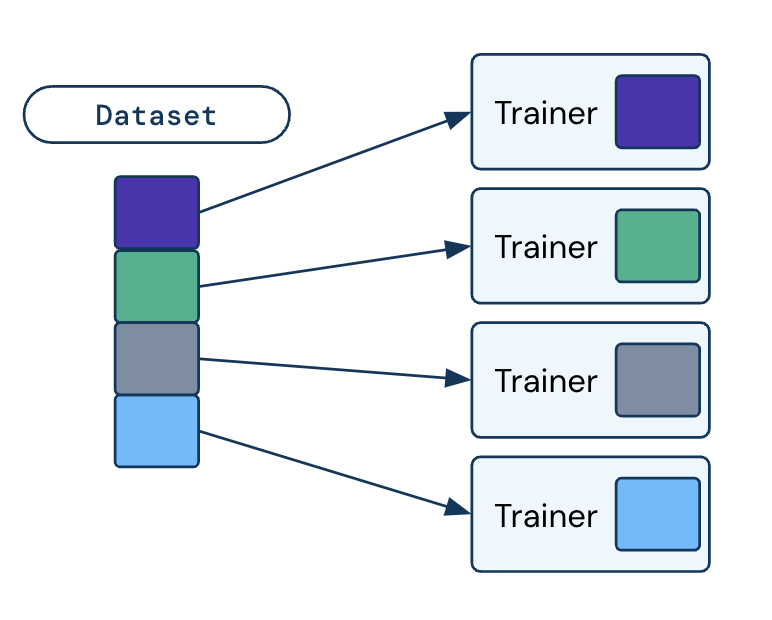
在分布式训练工作节点间自动动态地分割数据。
有关 Ray Data 的更多详细信息,请查阅Ray Data 文档。
注意
除了 Ray Data,您还可以继续在 Ray Train 中使用框架原生数据工具,例如 PyTorch Dataset, Hugging Face Dataset, 和 Lightning DataModule。
在本指南中,我们将介绍如何将 Ray Data 集成到您的 Ray Train 脚本中,以及自定义数据摄取流程的不同方法。
快速入门#
安装 Ray Data 和 Ray Train
pip install -U "ray[data,train]"
数据摄取可以通过四个基本步骤进行设置:
从输入数据创建 Ray Dataset。
对您的 Ray Dataset 应用预处理操作。
将预处理好的 Dataset 输入 Ray Train Trainer,Trainer 会在内部以流式方式将数据集均匀地分割给分布式训练工作节点。
在您的训练函数中使用 Ray Dataset。
import torch
import ray
from ray import train
from ray.train import Checkpoint, ScalingConfig
from ray.train.torch import TorchTrainer
# Set this to True to use GPU.
# If False, do CPU training instead of GPU training.
use_gpu = False
# Step 1: Create a Ray Dataset from in-memory Python lists.
# You can also create a Ray Dataset from many other sources and file
# formats.
train_dataset = ray.data.from_items([{"x": [x], "y": [2 * x]} for x in range(200)])
# Step 2: Preprocess your Ray Dataset.
def increment(batch):
batch["y"] = batch["y"] + 1
return batch
train_dataset = train_dataset.map_batches(increment)
def train_func():
batch_size = 16
# Step 4: Access the dataset shard for the training worker via
# ``get_dataset_shard``.
train_data_shard = train.get_dataset_shard("train")
# `iter_torch_batches` returns an iterable object that
# yield tensor batches. Ray Data automatically moves the Tensor batches
# to GPU if you enable GPU training.
train_dataloader = train_data_shard.iter_torch_batches(
batch_size=batch_size, dtypes=torch.float32
)
for epoch_idx in range(1):
for batch in train_dataloader:
inputs, labels = batch["x"], batch["y"]
assert type(inputs) == torch.Tensor
assert type(labels) == torch.Tensor
assert inputs.shape[0] == batch_size
assert labels.shape[0] == batch_size
# Only check one batch for demo purposes.
# Replace the above with your actual model training code.
break
# Step 3: Create a TorchTrainer. Specify the number of training workers and
# pass in your Ray Dataset.
# The Ray Dataset is automatically split across all training workers.
trainer = TorchTrainer(
train_func,
datasets={"train": train_dataset},
scaling_config=ScalingConfig(num_workers=2, use_gpu=use_gpu)
)
result = trainer.fit()
from ray import train
# Create the train and validation datasets.
train_data = ray.data.read_csv("./train.csv")
val_data = ray.data.read_csv("./validation.csv")
def train_func_per_worker():
# Access Ray datsets in your train_func via ``get_dataset_shard``.
# Ray Data shards all datasets across workers by default.
train_ds = train.get_dataset_shard("train")
val_ds = train.get_dataset_shard("validation")
# Create Ray dataset iterables via ``iter_torch_batches``.
train_dataloader = train_ds.iter_torch_batches(batch_size=16)
val_dataloader = val_ds.iter_torch_batches(batch_size=16)
...
trainer = pl.Trainer(
# ...
)
# Feed the Ray dataset iterables to ``pl.Trainer.fit``.
trainer.fit(
model,
train_dataloaders=train_dataloader,
val_dataloaders=val_dataloader
)
trainer = TorchTrainer(
train_func,
# You can pass in multiple datasets to the Trainer.
datasets={"train": train_data, "validation": val_data},
scaling_config=ScalingConfig(num_workers=4),
)
trainer.fit()
import ray
import ray.train
...
# Create the train and evaluation datasets.
train_data = ray.data.from_huggingface(hf_train_ds)
eval_data = ray.data.from_huggingface(hf_eval_ds)
def train_func():
# Access Ray datsets in your train_func via ``get_dataset_shard``.
# Ray Data shards all datasets across workers by default.
train_ds = ray.train.get_dataset_shard("train")
eval_ds = ray.train.get_dataset_shard("evaluation")
# Create Ray dataset iterables via ``iter_torch_batches``.
train_iterable_ds = train_ds.iter_torch_batches(batch_size=16)
eval_iterable_ds = eval_ds.iter_torch_batches(batch_size=16)
...
args = transformers.TrainingArguments(
...,
max_steps=max_steps # Required for iterable datasets
)
trainer = transformers.Trainer(
...,
model=model,
train_dataset=train_iterable_ds,
eval_dataset=eval_iterable_ds,
)
# Prepare your Transformers Trainer
trainer = ray.train.huggingface.transformers.prepare_trainer(trainer)
trainer.train()
trainer = TorchTrainer(
train_func,
# You can pass in multiple datasets to the Trainer.
datasets={"train": train_data, "evaluation": val_data},
scaling_config=ScalingConfig(num_workers=4, use_gpu=True),
)
trainer.fit()
加载数据#
Ray Datasets 可以从许多不同的数据源和格式创建。更多详细信息,请参阅加载数据。
预处理数据#
Ray Data 支持广泛的预处理操作,您可以使用这些操作在训练前转换数据。
对于通用预处理,请参阅转换数据。
对于表格数据,请参阅预处理结构化数据。
对于 PyTorch 张量,请参阅使用 torch 张量进行转换。
对于优化昂贵的预处理操作,请参阅缓存预处理数据集。
输入和分割数据#
您预处理好的数据集可以通过 datasets 参数传递给 Ray Train Trainer (例如 TorchTrainer)。
传递给 Trainer 的 datasets 参数可以在每个分布式训练工作节点上运行的 train_loop_per_worker 函数中通过调用 ray.train.get_dataset_shard() 来访问。
Ray Data 默认将所有数据集分割给训练工作节点。 get_dataset_shard() 返回数据集的 1/n,其中 n 是训练工作节点的数量。
Ray Data 实时以流式方式进行数据分割。
注意
请注意,由于 Ray Data 分割评估数据集,您必须跨工作节点聚合评估结果。您可以考虑使用 TorchMetrics (示例) 或其他框架中可用的工具进行探索。
可以通过传入 dataset_config 参数来覆盖此行为。有关配置分割逻辑的更多信息,请参阅分割数据集。
使用数据#
在 train_loop_per_worker 中,每个工作节点可以通过 ray.train.get_dataset_shard() 访问其数据集分片。
此数据可以通过多种方式使用:
要创建一个通用的批量 Iterable,您可以调用
iter_batches()。要创建一个 PyTorch DataLoader 的替代品,您可以调用
iter_torch_batches()。
有关如何遍历数据的更多详细信息,请参阅遍历数据。
从 PyTorch 数据开始#
一些框架提供了自己的数据集和数据加载工具。例如:
PyTorch: Dataset 与 DataLoader
Hugging Face: Dataset
PyTorch Lightning: LightningDataModule
您仍然可以直接在 Ray Train 中使用这些框架数据工具。
从宏观上看,您可以按如下方式比较这些概念:
PyTorch API |
HuggingFace API |
Ray Data API |
|---|---|---|
不适用 |
有关更多详细信息,请参阅以下各框架的部分:
选项 1 (使用 Ray Data)
将您的 PyTorch Dataset 转换为 Ray Dataset。
通过
datasets参数将 Ray Dataset 传递给 TorchTrainer。在您的
train_loop_per_worker中,您可以通过ray.train.get_dataset_shard()访问数据集。通过
ray.data.DataIterator.iter_torch_batches()创建数据集可迭代对象。
有关更多详细信息,请参阅从 PyTorch Datasets 和 DataLoaders 迁移。
选项 2 (不使用 Ray Data)
直接在
train_loop_per_worker中实例化 Torch Dataset 和 DataLoader。使用
ray.train.torch.prepare_data_loader()工具设置用于分布式训练的 DataLoader。
LightningDataModule 是使用 PyTorch Dataset 和 DataLoader 创建的。您可以在此处应用相同的逻辑。
选项 1 (使用 Ray Data)
将您的 Hugging Face Dataset 转换为 Ray Dataset。有关说明,请参阅面向 Hugging Face 的 Ray Data。
通过
datasets参数将 Ray Dataset 传递给 TorchTrainer。在您的
train_loop_per_worker中,通过ray.train.get_dataset_shard()访问分片数据集。通过
ray.data.DataIterator.iter_torch_batches()创建可迭代数据集。在初始化
transformers.Trainer时传递可迭代数据集。使用
ray.train.huggingface.transformers.prepare_trainer()工具包装您的 transformers trainer。
选项 2 (不使用 Ray Data)
直接在
train_loop_per_worker中实例化 Hugging Face Dataset。在初始化期间将 Hugging Face Dataset 传递给
transformers.Trainer。
提示
当直接使用 Torch 或 Hugging Face Datasets 而不使用 Ray Data 时,请确保在 train_loop_per_worker 内部实例化您的 Dataset。在 train_loop_per_worker 外部实例化 Dataset 并通过全局作用域传递它可能会导致错误,因为 Dataset 不可序列化。
分割数据集#
Ray Train 默认使用 Dataset.streaming_split 在工作节点之间分割所有数据集。每个工作节点看到的是数据的一个不相交的子集,而不是遍历整个数据集。
如果想自定义分割哪些数据集,请在 Trainer 构造函数中传入一个 DataConfig。
例如,要仅分割训练数据集,请执行以下操作:
import ray
from ray import train
from ray.train import ScalingConfig
from ray.train.torch import TorchTrainer
ds = ray.data.read_text(
"s3://anonymous@ray-example-data/sms_spam_collection_subset.txt"
)
train_ds, val_ds = ds.train_test_split(0.3)
def train_loop_per_worker():
# Get the sharded training dataset
train_ds = train.get_dataset_shard("train")
for _ in range(2):
for batch in train_ds.iter_batches(batch_size=128):
print("Do some training on batch", batch)
# Get the unsharded full validation dataset
val_ds = train.get_dataset_shard("val")
for _ in range(2):
for batch in val_ds.iter_batches(batch_size=128):
print("Do some evaluation on batch", batch)
my_trainer = TorchTrainer(
train_loop_per_worker,
scaling_config=ScalingConfig(num_workers=2),
datasets={"train": train_ds, "val": val_ds},
dataset_config=ray.train.DataConfig(
datasets_to_split=["train"],
),
)
my_trainer.fit()
完全自定义 (高级)#
对于默认配置类未涵盖的使用案例,您还可以完全自定义输入数据集的分割方式。定义一个自定义的 DataConfig 类 (DeveloperAPI)。DataConfig 类负责跨节点的共享设置和数据分割。
# Note that this example class is doing the same thing as the basic DataConfig
# implementation included with Ray Train.
from typing import Optional, Dict, List
import ray
from ray import train
from ray.train.torch import TorchTrainer
from ray.train import DataConfig, ScalingConfig
from ray.data import Dataset, DataIterator, NodeIdStr
from ray.actor import ActorHandle
ds = ray.data.read_text(
"s3://anonymous@ray-example-data/sms_spam_collection_subset.txt"
)
def train_loop_per_worker():
# Get an iterator to the dataset we passed in below.
it = train.get_dataset_shard("train")
for _ in range(2):
for batch in it.iter_batches(batch_size=128):
print("Do some training on batch", batch)
class MyCustomDataConfig(DataConfig):
def configure(
self,
datasets: Dict[str, Dataset],
world_size: int,
worker_handles: Optional[List[ActorHandle]],
worker_node_ids: Optional[List[NodeIdStr]],
**kwargs,
) -> List[Dict[str, DataIterator]]:
assert len(datasets) == 1, "This example only handles the simple case"
# Configure Ray Data for ingest.
ctx = ray.data.DataContext.get_current()
ctx.execution_options = DataConfig.default_ingest_options()
# Split the stream into shards.
iterator_shards = datasets["train"].streaming_split(
world_size, equal=True, locality_hints=worker_node_ids
)
# Return the assigned iterators for each worker.
return [{"train": it} for it in iterator_shards]
my_trainer = TorchTrainer(
train_loop_per_worker,
scaling_config=ScalingConfig(num_workers=2),
datasets={"train": ds},
dataset_config=MyCustomDataConfig(),
)
my_trainer.fit()
子类必须是可序列化的,因为 Ray Train 会将其从驱动脚本复制到 Trainer 的驱动 actor。Ray Train 会在 Trainer 组的主 actor 上调用其 configure 方法,为每个工作节点创建数据迭代器。
总的来说,您可以将 DataConfig 用于任何需要在工作节点开始遍历数据之前进行的共享设置。设置会在每次 Trainer 运行时开始时执行。
随机混洗#
对于每个 epoch 随机混洗数据对于模型质量可能很重要,具体取决于您训练的模型。
Ray Data 提供了多种随机混洗选项,更多详细信息请参阅混洗数据。
启用可复现性#
在开发或调优超参数模型时,数据摄取的可复现性非常重要,以确保数据摄取不会影响模型质量。按照以下三个步骤启用可复现性:
步骤 1: 通过在 DataContext 中设置 preserve_order 标志来启用 Ray Datasets 的确定性执行。
import ray
# Preserve ordering in Ray Datasets for reproducibility.
ctx = ray.data.DataContext.get_current()
ctx.execution_options.preserve_order = True
ds = ray.data.read_text(
"s3://anonymous@ray-example-data/sms_spam_collection_subset.txt"
)
步骤 2: 为任何混洗操作设置随机种子:
seed参数用于random_shuffleseed参数用于randomize_block_orderlocal_shuffle_seed参数用于iter_batches
步骤 3: 遵循所选训练框架启用可复现性的最佳实践。例如,请参阅Pytorch 可复现性指南。
预处理结构化数据#
注意
本节适用于表格/结构化数据。预处理非结构化数据的推荐方法是使用 Ray Data 操作,例如 map_batches。更多详细信息请参阅Ray Data PyTorch 集成指南。
对于表格数据,请使用 Ray Data 预处理器,它们实现了常见的数据预处理操作。您可以在将数据集传递给 Trainer 之前将其应用于数据集,从而与 Ray Train Trainers 一起使用。例如:
import numpy as np
from tempfile import TemporaryDirectory
import ray
from ray import train
from ray.train import Checkpoint, ScalingConfig
from ray.train.torch import TorchTrainer
from ray.data.preprocessors import Concatenator, StandardScaler
dataset = ray.data.read_csv("s3://anonymous@air-example-data/breast_cancer.csv")
# Create preprocessors to scale some columns and concatenate the results.
scaler = StandardScaler(columns=["mean radius", "mean texture"])
columns_to_concatenate = dataset.columns()
columns_to_concatenate.remove("target")
concatenator = Concatenator(columns=columns_to_concatenate, dtype=np.float32)
# Compute dataset statistics and get transformed datasets. Note that the
# fit call is executed immediately, but the transformation is lazy.
dataset = scaler.fit_transform(dataset)
dataset = concatenator.fit_transform(dataset)
def train_loop_per_worker():
context = train.get_context()
print(context.get_metadata()) # prints {"preprocessor_pkl": ...}
# Get an iterator to the dataset we passed in below.
it = train.get_dataset_shard("train")
for _ in range(2):
# Prefetch 10 batches at a time.
for batch in it.iter_batches(batch_size=128, prefetch_batches=10):
print("Do some training on batch", batch)
# Save a checkpoint.
with TemporaryDirectory() as temp_dir:
train.report(
{"score": 2.0},
checkpoint=Checkpoint.from_directory(temp_dir),
)
my_trainer = TorchTrainer(
train_loop_per_worker,
scaling_config=ScalingConfig(num_workers=2),
datasets={"train": dataset},
metadata={"preprocessor_pkl": scaler.serialize()},
)
# Get the fitted preprocessor back from the result metadata.
metadata = my_trainer.fit().checkpoint.get_metadata()
print(StandardScaler.deserialize(metadata["preprocessor_pkl"]))
此示例使用 Trainer(metadata={...}) 构造函数参数持久化拟合的预处理器。此参数指定一个字典,该字典可从 TrainContext.get_metadata() 和 Trainer 保存的检查点的 checkpoint.get_metadata() 中获取。此设计使得能够为推理重新创建拟合的预处理器。
性能提示#
预取批量数据#
在遍历数据集进行训练时,您可以增加 iter_batches 或 iter_torch_batches 中的 prefetch_batches 参数来进一步提高性能。在训练当前批量数据时,此方法会启动后台线程来获取并处理接下来的 N 个批量数据。
如果训练因跨节点数据传输或最后一英里预处理(例如将批量数据转换为张量或执行 collate_fn)而成为瓶颈,此方法会有所帮助。但是,增加 prefetch_batches 会导致需要更多数据存储在堆内存中。默认情况下,prefetch_batches 设置为 1。
例如,以下代码为每个训练工作节点一次预取 10 个批量数据:
import ray
from ray import train
from ray.train import ScalingConfig
from ray.train.torch import TorchTrainer
ds = ray.data.read_text(
"s3://anonymous@ray-example-data/sms_spam_collection_subset.txt"
)
def train_loop_per_worker():
# Get an iterator to the dataset we passed in below.
it = train.get_dataset_shard("train")
for _ in range(2):
# Prefetch 10 batches at a time.
for batch in it.iter_batches(batch_size=128, prefetch_batches=10):
print("Do some training on batch", batch)
my_trainer = TorchTrainer(
train_loop_per_worker,
scaling_config=ScalingConfig(num_workers=2),
datasets={"train": ds},
)
my_trainer.fit()
避免在 collate_fn 中进行繁重转换#
iter_batches 或 iter_torch_batches 中的 collate_fn 参数允许您在将数据馈送到模型之前进行转换。此操作在训练工作节点本地发生。避免在此函数中添加繁重的转换,因为它可能成为瓶颈。相反,在将数据集传递给 Trainer 之前,使用 map 或 map_batches 应用转换。
缓存预处理数据集#
如果您的预处理 Dataset 小到足以放入 Ray 对象存储内存中(默认情况下为集群总 RAM 的 30%),则通过在预处理数据集上调用 materialize(),将其在 Ray 内置对象存储中进行*具体化 (materialize)*。此方法告诉 Ray Data 计算整个预处理数据集并将其固定在 Ray 对象存储内存中。因此,当重复遍历数据集时,无需重新运行预处理操作。但是,如果预处理数据太大无法放入 Ray 对象存储内存中,此方法将大大降低性能,因为数据需要溢出到磁盘并从中读取回来。
您希望每个 epoch 运行的转换(例如随机化)应放在具体化 (materialize) 调用之后。
from typing import Dict
import numpy as np
import ray
# Load the data.
train_ds = ray.data.read_parquet("s3://anonymous@ray-example-data/iris.parquet")
# Define a preprocessing function.
def normalize_length(batch: Dict[str, np.ndarray]) -> Dict[str, np.ndarray]:
new_col = batch["sepal.length"] / np.max(batch["sepal.length"])
batch["normalized.sepal.length"] = new_col
del batch["sepal.length"]
return batch
# Preprocess the data. Transformations that are made before the materialize call
# below are only run once.
train_ds = train_ds.map_batches(normalize_length)
# Materialize the dataset in object store memory.
# Only do this if train_ds is small enough to fit in object store memory.
train_ds = train_ds.materialize()
# Dummy augmentation transform.
def augment_data(batch):
return batch
# Add per-epoch preprocessing. Transformations that you want to run per-epoch, such
# as data augmentation or randomization, should go after the materialize call.
train_ds = train_ds.map_batches(augment_data)
# Pass train_ds to the Trainer
向集群添加仅限 CPU 的节点#
如果 GPU 训练因昂贵的 CPU 预处理而成为瓶颈,并且预处理数据集太大无法放入对象存储内存中,则具体化数据集的方法不起作用。在这种情况下,Ray 对异构资源的原生支持使您只需向集群添加更多仅限 CPU 的节点,Ray Data 就会自动将仅限 CPU 的预处理任务扩展到仅限 CPU 的节点,从而使 GPU 更饱和。
总的来说,添加仅限 CPU 的节点可以在两个方面提供帮助:* 添加更多 CPU 核有助于进一步并行化预处理。当 CPU 计算时间是瓶颈时,此方法很有用。* 增加对象存储内存,这 1) 允许 Ray Data 在预处理和训练阶段之间缓冲更多数据,以及 2) 提供更多内存以实现缓存预处理数据集。当内存是瓶颈时,此方法很有用。