参数服务器#

提示
对于生产级的分布式训练实现,请使用 Ray Train。
参数服务器是用于分布式机器学习训练的框架。
在参数服务器框架中,一个中心化服务器(或一组服务器节点)维护机器学习模型(例如,神经网络)的全局共享参数,而计算更新(即梯度下降更新)的数据和计算则分布在工作节点上。
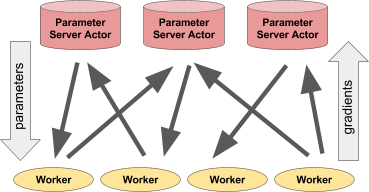
参数服务器是许多机器学习应用的核心部分。本文档将介绍如何使用 Ray actor 实现简单的同步和异步参数服务器。
要运行此应用程序,首先安装一些依赖项。
pip install torch torchvision filelock
首先定义一些辅助函数并导入一些依赖项。
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
from filelock import FileLock
import numpy as np
import ray
def get_data_loader():
"""Safely downloads data. Returns training/validation set dataloader."""
mnist_transforms = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
)
# We add FileLock here because multiple workers will want to
# download data, and this may cause overwrites since
# DataLoader is not threadsafe.
with FileLock(os.path.expanduser("~/data.lock")):
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(
"~/data", train=True, download=True, transform=mnist_transforms
),
batch_size=128,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST("~/data", train=False, transform=mnist_transforms),
batch_size=128,
shuffle=True,
)
return train_loader, test_loader
def evaluate(model, test_loader):
"""Evaluates the accuracy of the model on a validation dataset."""
model.eval()
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (data, target) in enumerate(test_loader):
# This is only set to finish evaluation faster.
if batch_idx * len(data) > 1024:
break
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
return 100.0 * correct / total
设置:定义神经网络#
我们定义一个小型神经网络用于训练。我们提供了一些用于获取数据的辅助函数,包括用于获取/设置梯度和权重的 getter/setter 方法。
class ConvNet(nn.Module):
"""Small ConvNet for MNIST."""
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(1, 3, kernel_size=3)
self.fc = nn.Linear(192, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 3))
x = x.view(-1, 192)
x = self.fc(x)
return F.log_softmax(x, dim=1)
def get_weights(self):
return {k: v.cpu() for k, v in self.state_dict().items()}
def set_weights(self, weights):
self.load_state_dict(weights)
def get_gradients(self):
grads = []
for p in self.parameters():
grad = None if p.grad is None else p.grad.data.cpu().numpy()
grads.append(grad)
return grads
def set_gradients(self, gradients):
for g, p in zip(gradients, self.parameters()):
if g is not None:
p.grad = torch.from_numpy(g)
定义参数服务器#
参数服务器将持有一个模型的副本。在训练期间,它将
接收梯度并将其应用到其模型。
将更新后的模型发送回工作节点。
@ray.remote 装饰器定义了一个远程进程。它封装了 ParameterServer 类,并允许用户将其实例化为一个远程 actor。
@ray.remote
class ParameterServer(object):
def __init__(self, lr):
self.model = ConvNet()
self.optimizer = torch.optim.SGD(self.model.parameters(), lr=lr)
def apply_gradients(self, *gradients):
summed_gradients = [
np.stack(gradient_zip).sum(axis=0) for gradient_zip in zip(*gradients)
]
self.optimizer.zero_grad()
self.model.set_gradients(summed_gradients)
self.optimizer.step()
return self.model.get_weights()
def get_weights(self):
return self.model.get_weights()
定义工作节点#
工作节点也将持有一个模型的副本。在训练期间,它将持续评估数据并将梯度发送到参数服务器。工作节点将与参数服务器模型权重同步其模型。
@ray.remote
class DataWorker(object):
def __init__(self):
self.model = ConvNet()
self.data_iterator = iter(get_data_loader()[0])
def compute_gradients(self, weights):
self.model.set_weights(weights)
try:
data, target = next(self.data_iterator)
except StopIteration: # When the epoch ends, start a new epoch.
self.data_iterator = iter(get_data_loader()[0])
data, target = next(self.data_iterator)
self.model.zero_grad()
output = self.model(data)
loss = F.nll_loss(output, target)
loss.backward()
return self.model.get_gradients()
同步参数服务器训练#
现在我们将创建一个同步参数服务器训练方案。首先,我们将实例化一个参数服务器进程,以及多个工作节点。
iterations = 200
num_workers = 2
ray.init(ignore_reinit_error=True)
ps = ParameterServer.remote(1e-2)
workers = [DataWorker.remote() for i in range(num_workers)]
我们还将在驱动进程上实例化一个模型,以便在训练期间评估测试准确率。
model = ConvNet()
test_loader = get_data_loader()[1]
训练交替进行
根据服务器的当前权重计算梯度
使用梯度更新参数服务器的权重。
print("Running synchronous parameter server training.")
current_weights = ps.get_weights.remote()
for i in range(iterations):
gradients = [worker.compute_gradients.remote(current_weights) for worker in workers]
# Calculate update after all gradients are available.
current_weights = ps.apply_gradients.remote(*gradients)
if i % 10 == 0:
# Evaluate the current model.
model.set_weights(ray.get(current_weights))
accuracy = evaluate(model, test_loader)
print("Iter {}: \taccuracy is {:.1f}".format(i, accuracy))
print("Final accuracy is {:.1f}.".format(accuracy))
# Clean up Ray resources and processes before the next example.
ray.shutdown()
异步参数服务器训练#
现在我们将创建一个异步参数服务器训练方案。首先,我们将实例化一个参数服务器进程,以及多个工作节点。
print("Running Asynchronous Parameter Server Training.")
ray.init(ignore_reinit_error=True)
ps = ParameterServer.remote(1e-2)
workers = [DataWorker.remote() for i in range(num_workers)]
在这里,工作节点将根据其当前权重异步计算梯度,并在梯度准备好后立即将其发送到参数服务器。当参数服务器完成应用新梯度时,服务器会将当前权重的副本发送回工作节点。然后工作节点将更新权重并重复该过程。
current_weights = ps.get_weights.remote()
gradients = {}
for worker in workers:
gradients[worker.compute_gradients.remote(current_weights)] = worker
for i in range(iterations * num_workers):
ready_gradient_list, _ = ray.wait(list(gradients))
ready_gradient_id = ready_gradient_list[0]
worker = gradients.pop(ready_gradient_id)
# Compute and apply gradients.
current_weights = ps.apply_gradients.remote(*[ready_gradient_id])
gradients[worker.compute_gradients.remote(current_weights)] = worker
if i % 10 == 0:
# Evaluate the current model after every 10 updates.
model.set_weights(ray.get(current_weights))
accuracy = evaluate(model, test_loader)
print("Iter {}: \taccuracy is {:.1f}".format(i, accuracy))
print("Final accuracy is {:.1f}.".format(accuracy))
总结#
这种方法非常强大,因为它使你能够用少量代码作为 Python 应用程序的一部分来实现参数服务器。因此,这简化了使用参数服务器的应用程序的部署,并且可以轻松修改参数服务器的行为。
例如,对参数服务器进行分片、更改更新规则、在异步和同步更新之间切换、忽略慢速工作节点或任何其他数量的自定义,都只需要额外几行代码。