在 GKE 上使用 TPU 部署 Stable Diffusion 模型#
注意:Ray Serve 应用及其客户端的 Python 文件位于 ray-project/serve_config_examples 中。本指南改编自 tensorflow/tpu 示例。
步骤 1:创建带有 TPU 的 Kubernetes 集群#
按照 为 KubeRay 创建带有 TPU 的 GKE 集群 的说明创建一个包含 1 个 CPU 节点和 1 个 TPU 节点的 GKE 集群。
步骤 2:安装 KubeRay Operator#
如果你的 GKE 集群启用了 Ray Operator Addon,请跳过此步骤。按照 部署 KubeRay Operator 的说明从 Helm 仓库安装最新的稳定版本 KubeRay Operator。KubeRay v1.1.0+ 支持多主机 TPU。请注意,此示例中的 YAML 文件使用了 serveConfigV2,KubeRay 从 v0.6.0 开始支持此配置。
步骤 3:安装 RayService CR#
# Creates a RayCluster with a single-host v4 TPU worker group of 2x2x1 topology.
kubectl apply -f https://raw.githubusercontent.com/ray-project/kuberay/master/ray-operator/config/samples/ray-service.tpu-single-host.yaml
KubeRay Operator v1.1.0 在 RayCluster CR 中添加了一个新的 NumOfHosts 字段,支持多主机工作组。此字段指定每个副本要创建的工作节点数量,其中每个副本代表一个多主机 Pod 切片。NumOfHosts 的值应与给定 cloud.google.com/gke-tpu-topology 节点选择器预期的 TPU VM 主机数量相匹配。对于本示例,Stable Diffusion 模型足够小,可以在单个 TPU 主机上运行,因此 RayService manifest 中的 numOfHosts 设置为 1。
步骤 4:在 Ray Dashboard 中查看 Serve 部署#
验证你已部署 RayService CR 并且其正在运行
kubectl get rayservice
# NAME SERVICE STATUS NUM SERVE ENDPOINTS
# stable-diffusion-tpu-serve-svc Running 2
从 Ray head 服务转发 Ray Dashboard 的端口。要在本地机器上查看 Dashboard,请打开 https://:8265/。
kubectl port-forward svc/stable-diffusion-tpu-head-svc 8265:8265 &
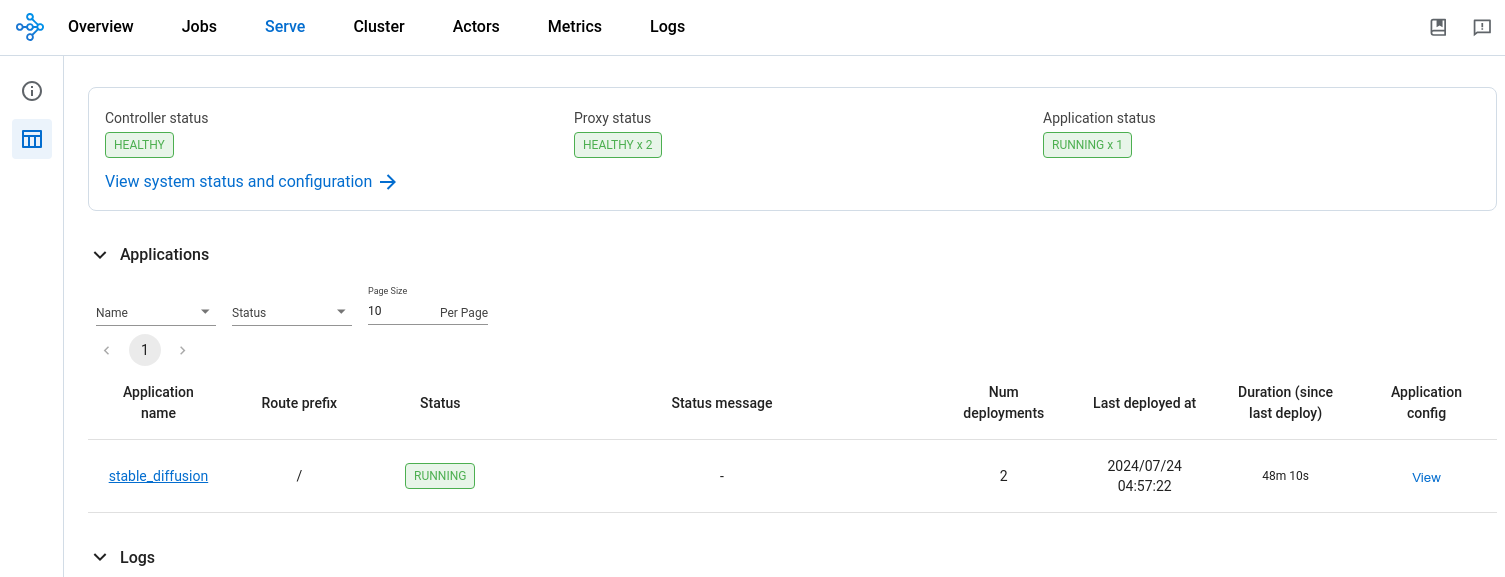
从 Ray Dashboard 的“Serve”选项卡监控 RayService CR 的状态。已安装的 RayService CR 应会创建一个名为“stable_diffusion”的运行中应用程序。该应用程序应包含两个部署:接收输入提示的 API 入口 (ingress) 和 Stable Diffusion 模型服务器。
步骤 5:向模型服务器发送文本到图像提示#
转发 Ray Serve 服务的端口
kubectl port-forward svc/stable-diffusion-tpu-serve-svc 8000
在另一个终端中,下载 Python 提示脚本
curl -LO https://raw.githubusercontent.com/ray-project/serve_config_examples/master/stable_diffusion/stable_diffusion_tpu_req.py
在本地安装运行 Python 脚本所需的依赖项
# Create a Python virtual environment.
python3 -m venv myenv
source myenv/bin/activate
pip install numpy pillow requests tqdm
向 Stable Diffusion 模型服务器提交文本到图像提示
python stable_diffusion_tpu_req.py --save_pictures
Python 提示脚本将 Stable Diffusion 推理结果保存到名为 diffusion_results.png 的文件中。
