Ray Serve 自动扩缩容#
每个 Ray Serve 部署 默认有一个 副本 (replica)。这意味着有一个工作进程运行模型并处理请求。当部署的流量增加时,单个副本可能会过载。为了保持服务的高性能,你需要扩展(scale out)你的部署。
手动扩缩容#
在深入更复杂的自动扩缩容之前,另一种选择是手动扩缩容。你可以通过 原地更新 (in place updates) 在部署选项中为 num_replicas 设置更高的值来增加副本数量。默认情况下,num_replicas 为 1。增加副本数量将水平扩展你的部署,并提高处理增加流量水平时的延迟和吞吐量。
# Deploy with a single replica
deployments:
- name: Model
num_replicas: 1
# Scale up to 10 replicas
deployments:
- name: Model
num_replicas: 10
自动扩缩容基本配置#
除了为部署设置固定的副本数量并手动更新外,你还可以配置部署根据入站流量自动扩缩容。Serve 自动扩缩器通过监控队列大小并做出添加或移除副本的扩缩容决策来应对流量高峰。通过设置 num_replicas="auto" 来为部署开启自动扩缩容。你可以通过在部署选项中调整 autoscaling_config 来进一步配置它。
以下配置将用于下一节的示例。
- name: Model
num_replicas: auto
设置 num_replicas="auto" 等同于以下部署配置。
- name: Model
max_ongoing_requests: 5
autoscaling_config:
target_ongoing_requests: 2
min_replicas: 1
max_replicas: 100
注意
你可以设置 num_replicas="auto" 并通过指定 autoscaling_config 来覆盖其默认值(如上所示),或者你可以省略 num_replicas="auto" 并完全自行配置自动扩缩容。
让我们深入了解这些参数的作用。
target_ongoing_requests 是 Serve 自动扩缩器试图确保的每个副本的平均正在进行的请求数。你可以根据请求处理时长(请求越长,这个数字应越小)以及你的延迟目标(你希望延迟越短,这个数字应越小)来调整它。
max_ongoing_requests 是一个副本允许的最大正在进行的请求数。请注意,此参数不属于自动扩缩容配置,因为它与所有部署相关,但如果你为部署开启自动扩缩容,则将此参数相对于目标值进行设置非常重要。
min_replicas 是部署的最小副本数。如果在很长一段时间内没有流量并且可以接受扩缩容期间的一些额外尾部延迟,则将其设置为 0。否则,将其设置为你认为低流量时所需的数量。
max_replicas 是部署的最大副本数。将其设置为比你认为峰值流量所需的数量高约 20%。
这些指南是一个很好的起点。如果你决定进一步调整应用程序的自动扩缩容配置,请参阅 高级 Ray Serve 自动扩缩容。
基本示例#
此示例是运行 ResNet50 的同步工作负载。下面是应用程序代码及其自动扩缩容配置。或者,可以查看第二个标签页,了解如何通过 YAML 文件指定自动扩缩容配置。
import requests
from io import BytesIO
from PIL import Image
import starlette.requests
import torch
from torchvision import transforms
import torchvision.models as models
from torchvision.models import ResNet50_Weights
from ray import serve
@serve.deployment(
ray_actor_options={"num_cpus": 1},
num_replicas="auto",
)
class Model:
def __init__(self):
self.resnet50 = (
models.resnet50(weights=ResNet50_Weights.DEFAULT).eval().to("cpu")
)
self.preprocess = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
),
]
)
resp = requests.get(
"https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
)
self.categories = resp.content.decode("utf-8").split("\n")
async def __call__(self, request: starlette.requests.Request) -> str:
uri = (await request.json())["uri"]
image_bytes = requests.get(uri).content
image = Image.open(BytesIO(image_bytes)).convert("RGB")
# Batch size is 1
input_tensor = torch.cat([self.preprocess(image).unsqueeze(0)]).to("cpu")
with torch.no_grad():
output = self.resnet50(input_tensor)
sm_output = torch.nn.functional.softmax(output[0], dim=0)
ind = torch.argmax(sm_output)
return self.categories[ind]
app = Model.bind()
applications:
- name: default
import_path: resnet:app
deployments:
- name: Model
num_replicas: auto
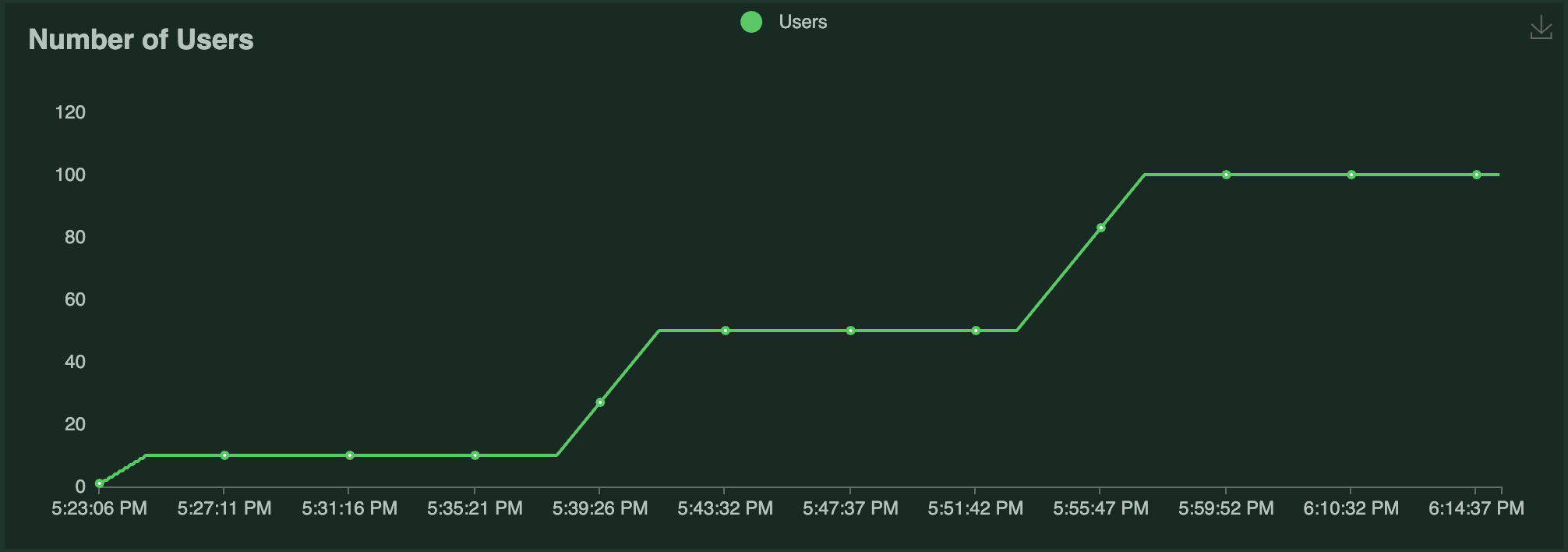
此示例使用 Locust 对此应用程序运行负载测试。Locust 负载测试运行一定数量的“用户”来 ping ResNet50 服务,每个用户的 恒定等待时间 为 0。每个用户(重复地)发送一个请求,等待响应,然后立即发送下一个请求。随着时间推移运行的用户数量如下图所示
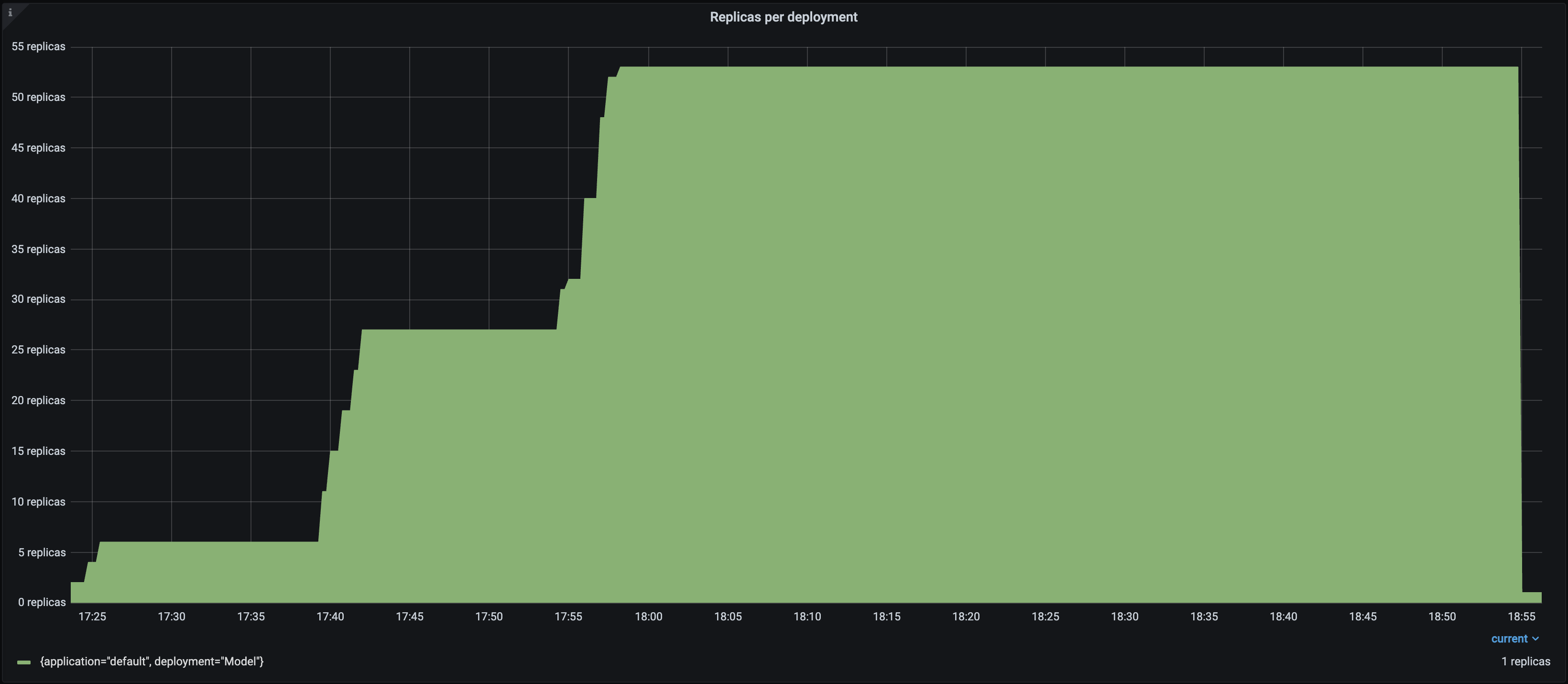
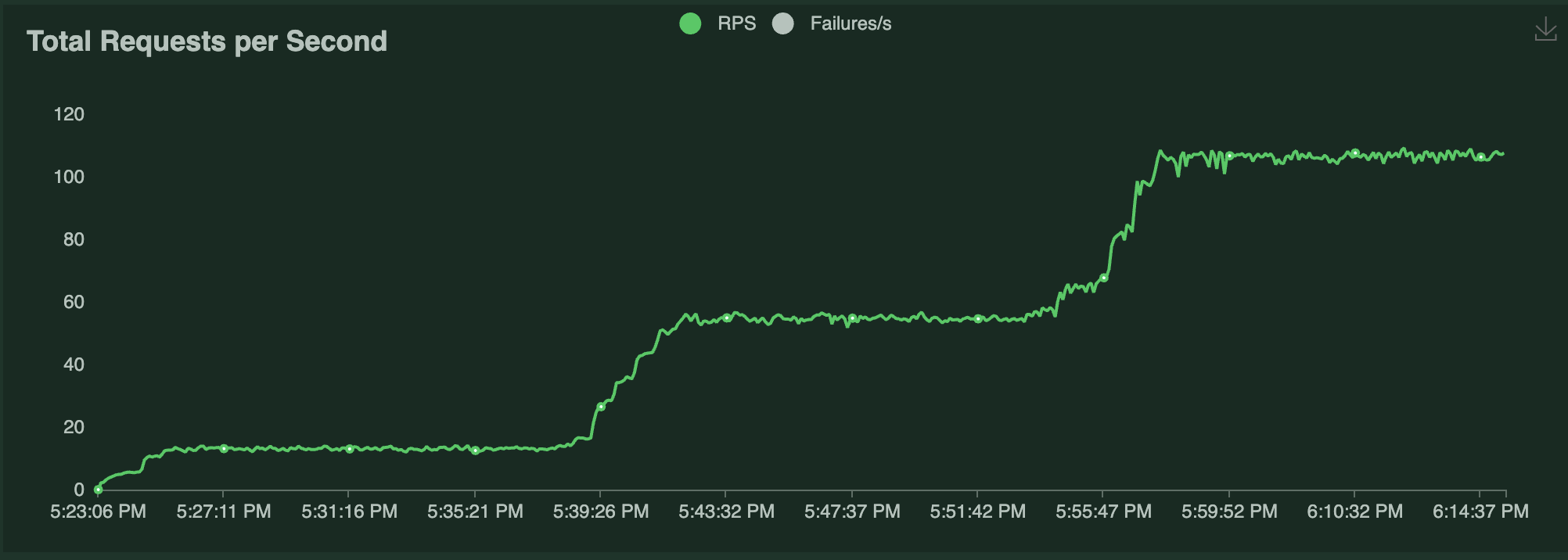
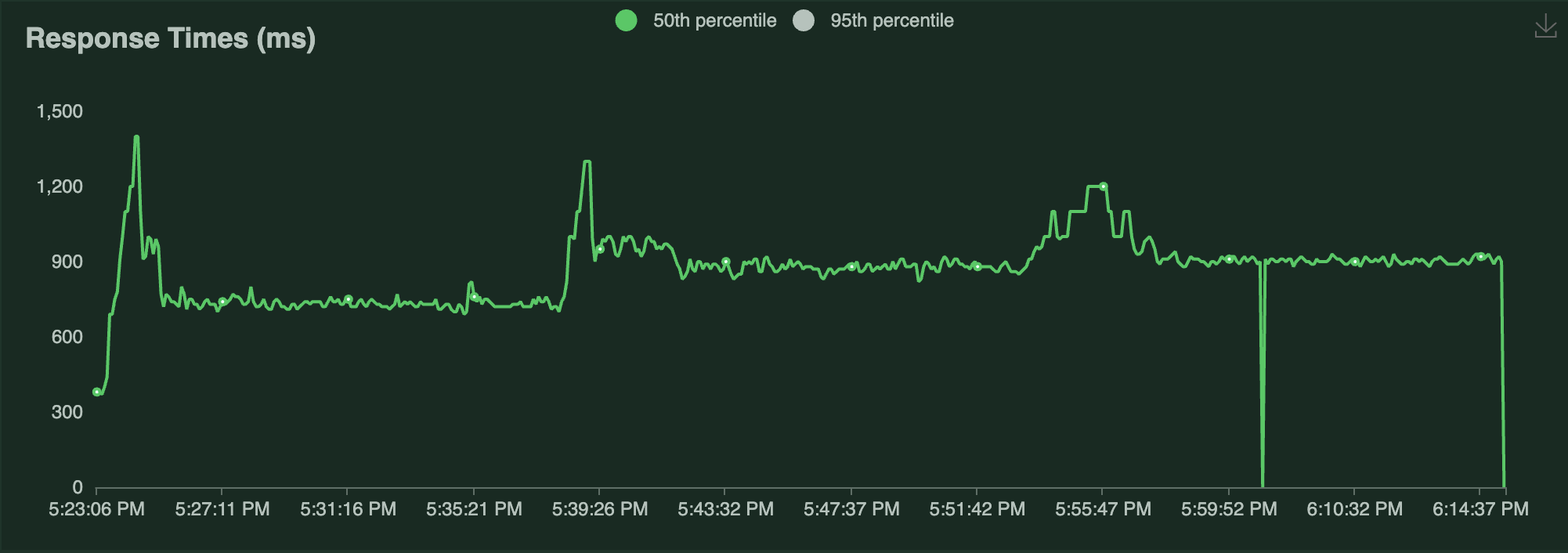
负载测试结果如下
副本数 |
|
|
QPS |
|
|
P50 延迟 |
|
请注意以下几点
每个 Locust 用户持续发送单个请求并等待响应。因此,自动扩缩的副本数量大致是 Locust 用户数量的一半,因为 Serve 试图满足
target_ongoing_requests=2的设置。系统的吞吐量随着用户数量和副本数量的增加而增加。
当流量增加时,延迟会短暂飙升,但除此之外相对稳定。
Ray Serve 自动扩缩器 vs Ray 自动扩缩器#
Ray Serve 自动扩缩器是一个应用层面的自动扩缩器,它位于 Ray 自动扩缩器 之上。具体来说,这意味着 Ray Serve 自动扩缩器会根据请求需求要求 Ray 启动一定数量的副本 Actor。如果 Ray 自动扩缩器确定没有足够的可用资源(例如 CPU、GPU 等)来放置这些 Actor,它会通过请求更多 Ray 节点来响应。底层的云提供商随后通过添加更多节点来响应。同样,当 Ray Serve 缩减并终止副本 Actor 时,它会尝试尽可能多地使节点空闲,以便 Ray 自动扩缩器可以移除它们。要了解更多关于 Ray Serve 自动扩缩容底层架构的信息,请参阅 Ray Serve 自动扩缩容架构。