Ray Serve 高级自动扩缩容#
本指南详细介绍了 autoscaling_config 中更高级的自动扩缩容参数以及一个高级模型组合示例。
自动扩缩容配置参数#
在本节中,我们将更详细地介绍 Serve 自动扩缩容的概念以及如何设置您的自动扩缩容配置。
[必需] 定义系统的稳态#
要定义部署的稳态,请为 target_ongoing_requests 和 max_ongoing_requests 设置值。
target_ongoing_requests [默认值=2]#
注意
target_ongoing_requests 的默认值在 Ray 2.32.0 中从 1.0 更改为 2.0。您可以继续手动设置以覆盖默认值。
Serve 根据每个副本的平均正在处理请求数量来扩缩部署的副本数量。具体来说,Serve 将每个副本的*实际*正在处理请求数量与您在自动扩缩容配置中设置的目标值进行比较,并据此做出扩容或缩容决策。使用 target_ongoing_requests 设置目标值,Serve 会尝试确保每个副本大约有这么多正在处理和在队列中等待的请求。
始终对您的工作负载进行负载测试。例如,如果用例对延迟敏感,您可以降低 target_ongoing_requests 的数量以保持高性能。对您的应用代码进行基准测试,并根据端到端延迟目标设置此数字。
注意
举个例子,假设您有两个副本的同步部署,其延迟为 100 毫秒,服务负载为 30 QPS。Serve 分配请求给副本的速度快于副本处理请求的速度;随着时间推移,越来越多的请求在副本处排队(这些请求是“正在处理的请求”),然后每个副本的平均正在处理请求数量稳步增加。延迟也会增加,因为新请求必须等待旧请求处理完成。如果您将 target_ongoing_requests = 1,Serve 会检测到每个副本的正在处理请求数量高于预期,并添加更多副本。在 3 个副本的情况下,您的系统平均每个副本处理 1 个正在处理请求,能够处理 30 QPS。
max_ongoing_requests [默认值=5]#
注意
max_ongoing_requests 的默认值在 Ray 2.32.0 中从 100 更改为 5。您可以继续手动设置以覆盖默认值。
还有一个最大队列限制,代理在将请求分配给副本时会遵守该限制。使用 max_ongoing_requests 定义该限制。将 max_ongoing_requests 设置为比 target_ongoing_requests 高约 20% 到 50%。
设置得太低会限制吞吐量。请求不会被转发到副本并发执行,而是倾向于在代理处排队,等待副本处理完现有请求。
注意
特别是对于轻量级请求,max_ongoing_requests 应设置得更高,否则整体吞吐量会受到影响。
设置得太高可能导致路由不平衡。具体来说,这会导致在扩容期间出现非常高的尾部延迟,因为当自动扩缩容程序因流量峰值而扩容部署时,在新副本启动之前,大多数或所有请求可能已经被分配到现有副本。
[必需] 定义自动扩缩容的上限和下限#
要使用自动扩缩容,您需要定义系统允许的最小和最大资源数量。
min_replicas [默认值=1]:这是部署的最小副本数。如果您想确保系统始终能够处理一定水平的流量,请将
min_replicas设置为正数。另一方面,如果您预计流量为零并希望缩容到零以节省成本,请设置min_replicas = 0。请注意,将min_replicas = 0会导致更高的尾部延迟;当您开始发送流量时,部署会扩容,并且在 Serve 等待副本启动以服务请求时会有冷启动时间。max_replicas [默认值=1]:这是部署的最大副本数。此值应大于
min_replicas。Ray Serve 自动扩缩容依赖于 Ray 自动扩缩容程序,当当前可用的集群资源(CPU、GPU 等)不足以支持更多副本时,会扩容更多节点。initial_replicas:这是部署最初启动的副本数。此值默认为
min_replicas的值。
[可选] 定义系统如何应对变化的流量#
在流量稳定且 min_replicas 和 max_replicas 配置得当的情况下,系统的稳态对于选定的 target_ongoing_requests 配置值来说是基本固定的。然而,在达到稳态之前,您的系统会根据流量变化做出反应。您希望系统如何应对流量变化决定了如何设置其余的自动扩缩容配置。
upscale_delay_s [默认值=30秒]:这定义了 Serve 在扩缩部署副本数量之前等待的时间。换句话说,此参数控制扩容决策的频率。如果副本在
upscale_delay_s秒的时间内*持续*处理的请求数量高于预期,则 Serve 会根据聚合的正在处理请求指标扩缩副本数量。例如,如果您的服务可能经历流量突增,您可以降低upscale_delay_s,以便您的应用能够快速响应流量的增加。downscale_delay_s [默认值=600秒]:这定义了 Serve 在缩减部署副本数量之前等待的时间。换句话说,此参数控制缩容决策的频率。如果副本在
downscale_delay_s秒的时间内*持续*处理的请求数量低于预期,则 Serve 会根据聚合的正在处理请求指标缩减副本数量。例如,如果您的应用初始化较慢,您可以增加downscale_delay_s,以便缩容发生得更不频繁,并在将来应用需要再次扩容时避免重新初始化。upscale_smoothing_factor [默认值=1.0] (已弃用):此参数已重命名为
upscaling_factor。upscale_smoothing_factor将在未来的版本中移除。downscale_smoothing_factor [默认值=1.0] (已弃用):此参数已重命名为
downscaling_factor。downscale_smoothing_factor将在未来的版本中移除。upscaling_factor [默认值=1.0]:用于放大或缓和每次扩容决策的乘法因子。例如,当应用在短时间内有高流量时,您可以增加
upscaling_factor以快速扩容资源。此参数就像一个“增益”因子,用于放大自动扩缩容算法的响应。downscaling_factor [默认值=1.0]:用于放大或缓和每次缩容决策的乘法因子。例如,如果您希望应用对流量下降不那么敏感,并更保守地缩容,您可以减小
downscaling_factor以减缓缩容的速度。metrics_interval_s [默认值=10]:这控制每个副本向自动扩缩容程序发送当前正在处理请求报告的频率。请注意,如果自动扩缩容程序未收到更新的指标,则无法做出新决策,因此您很可能希望将
metrics_interval_s设置为小于或等于扩容和缩容延迟值的值。例如,如果您设置upscale_delay_s = 3,但保持metrics_interval_s = 10,则自动扩缩容程序大约每 10 秒才会扩容一次。look_back_period_s [默认值=30]:这是计算每个副本平均正在处理请求数量的时间窗口。
模型组合示例#
确定多模型应用的自动扩缩容配置需要了解每个部署的扩缩容需求。每个部署都有不同的延迟和不同的并发级别。因此,为模型组合应用找到正确的自动扩缩容配置需要进行实验。
本示例是一个包含三个组合部署的简单应用,旨在帮助您了解多模型自动扩缩容。假设这些部署是
HeavyLoad: 一个模拟的 200 毫秒工作负载,CPU 使用率高。LightLoad: 一个模拟的 100 毫秒工作负载,CPU 使用率高。Driver: 一个驱动部署,扇出到HeavyLoad和LightLoad部署,并聚合两个输出。
尝试 1:一个 Driver 副本#
首先考虑以下部署配置。由于驱动部署的 CPU 使用率低,并且仅异步调用下游部署,因此分配一个固定的 Driver 副本是合理的。
- name: Driver
num_replicas: 1
max_ongoing_requests: 200
- name: HeavyLoad
max_ongoing_requests: 3
autoscaling_config:
target_ongoing_requests: 1
min_replicas: 0
initial_replicas: 0
max_replicas: 200
upscale_delay_s: 3
downscale_delay_s: 60
upscaling_factor: 0.3
downscaling_factor: 0.3
metrics_interval_s: 2
look_back_period_s: 10
- name: LightLoad
max_ongoing_requests: 3
autoscaling_config:
target_ongoing_requests: 1
min_replicas: 0
initial_replicas: 0
max_replicas: 200
upscale_delay_s: 3
downscale_delay_s: 60
upscaling_factor: 0.3
downscaling_factor: 0.3
metrics_interval_s: 2
look_back_period_s: 10
import time
from ray import serve
from ray.serve.handle import DeploymentHandle
@serve.deployment
class LightLoad:
async def __call__(self) -> str:
start = time.time()
while time.time() - start < 0.1:
pass
return "light"
@serve.deployment
class HeavyLoad:
async def __call__(self) -> str:
start = time.time()
while time.time() - start < 0.2:
pass
return "heavy"
@serve.deployment
class Driver:
def __init__(self, a_handle, b_handle):
self.a_handle: DeploymentHandle = a_handle
self.b_handle: DeploymentHandle = b_handle
async def __call__(self) -> str:
a_future = self.a_handle.remote()
b_future = self.b_handle.remote()
return (await a_future), (await b_future)
app = Driver.bind(HeavyLoad.bind(), LightLoad.bind())
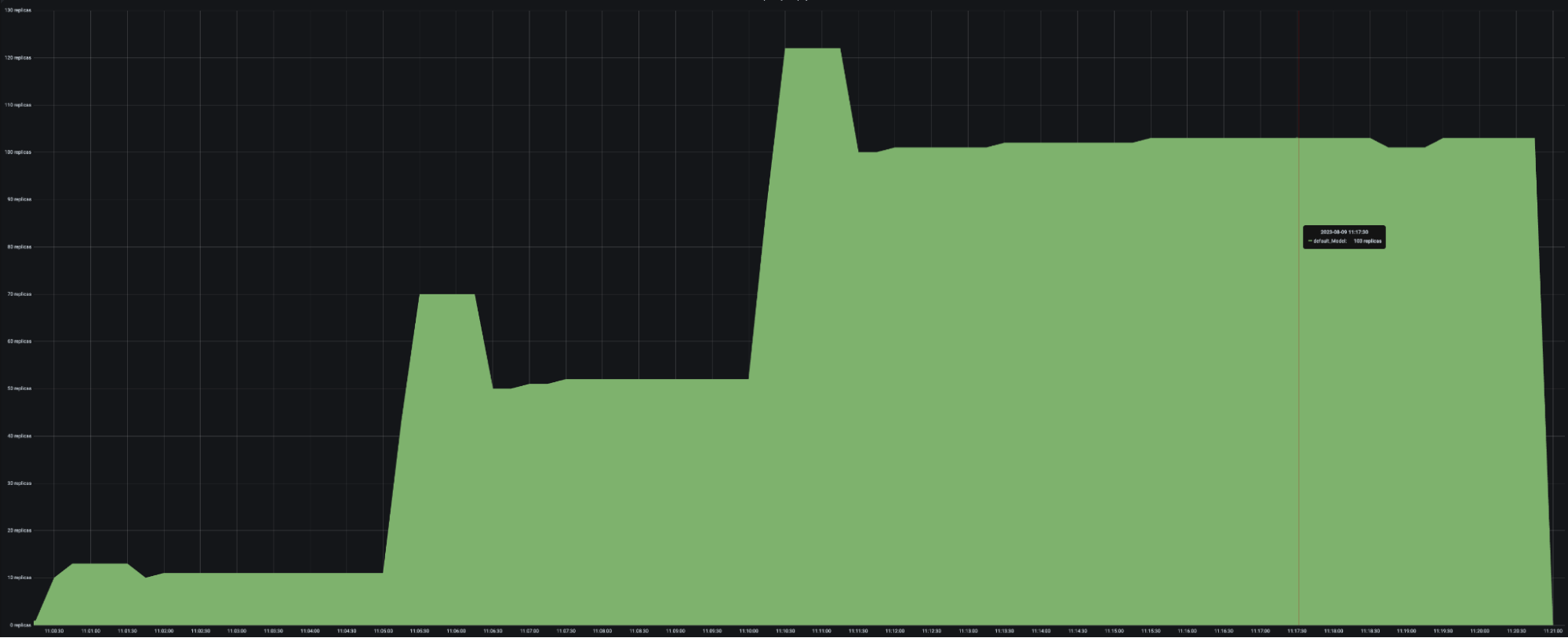
运行与 Resnet 工作负载 中相同的 Locust 负载测试,生成以下结果
HeavyLoad 和 LightLoad 副本数量 |
|
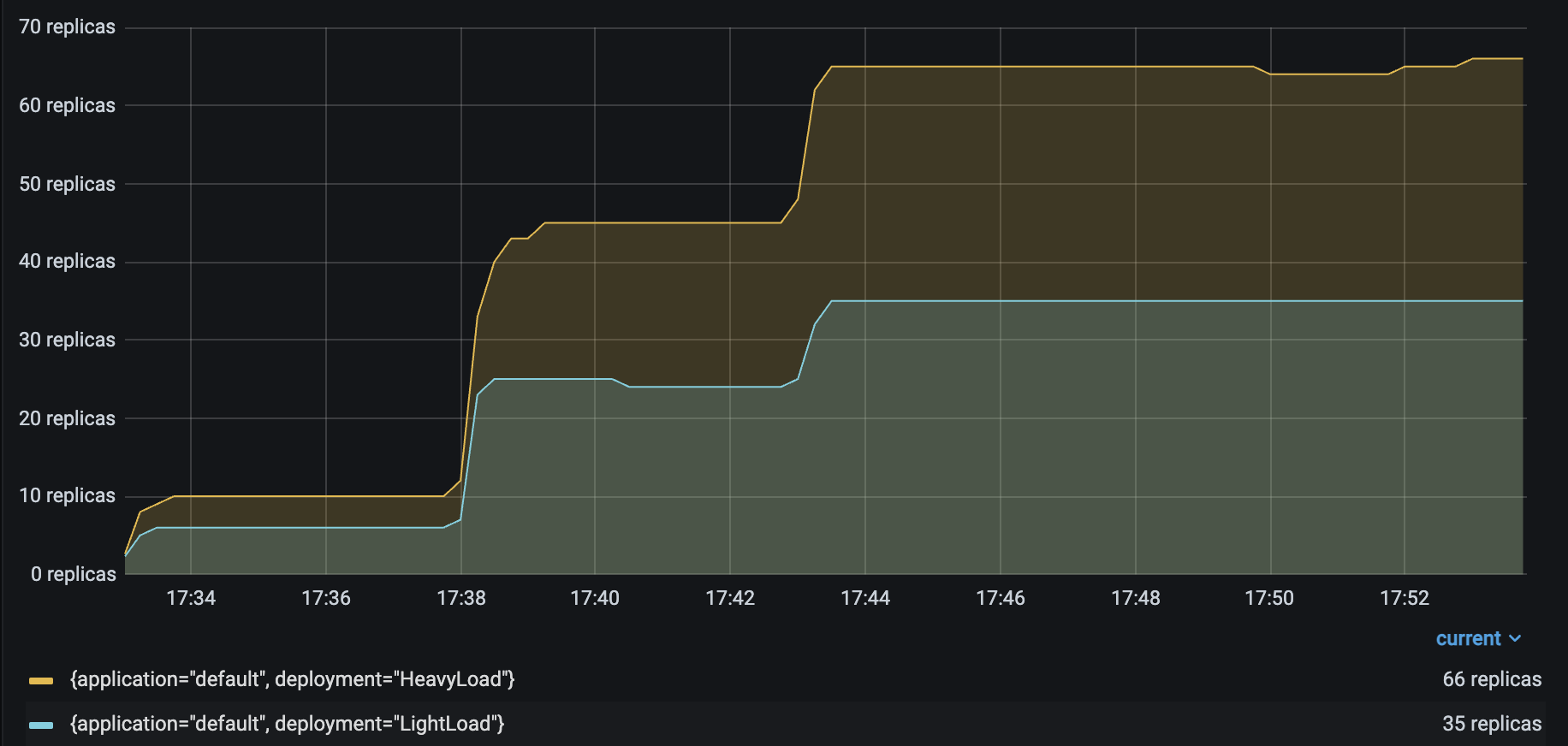
正如您可能预期的那样,自动扩缩容的 LightLoad 副本数量大约是自动扩缩容的 HeavyLoad 副本数量的一半。尽管每秒发送到两个部署的请求数量相同,但 LightLoad 副本每秒可以处理的请求数量是 HeavyLoad 副本的两倍,因此该部署处理相同流量负载所需的副本数量应为一半。
不幸的是,当 Locust 用户数量增加到 100 时,服务延迟从 230 毫秒上升到 400 毫秒。
P50 延迟 |
QPS |
|---|---|
|
|


请注意,HeavyLoad 副本的数量应大致与 Locust 用户数量匹配,以充分服务 Locust 流量。然而,当 Locust 用户数量增加到 100 时,HeavyLoad 部署难以达到 100 个副本,而只达到了 65 个副本。每个部署的延迟揭示了根本原因。HeavyLoad 和 LightLoad 的延迟分别稳定在 200 毫秒和 100 毫秒,而 Driver 的延迟从 230 毫秒上升到 400 毫秒。这表明高 Locust 工作负载可能压垮了 Driver 副本并影响了其异步事件循环的性能。
尝试 2:自动扩缩容 Driver#
对于这次尝试,也为 Driver 设置自动扩缩容配置,将 target_ongoing_requests = 20。现在的部署配置如下
- name: Driver
max_ongoing_requests: 200
autoscaling_config:
target_ongoing_requests: 20
min_replicas: 1
initial_replicas: 1
max_replicas: 10
upscale_delay_s: 3
downscale_delay_s: 60
upscaling_factor: 0.3
downscaling_factor: 0.3
metrics_interval_s: 2
look_back_period_s: 10
- name: HeavyLoad
max_ongoing_requests: 3
autoscaling_config:
target_ongoing_requests: 1
min_replicas: 0
initial_replicas: 0
max_replicas: 200
upscale_delay_s: 3
downscale_delay_s: 60
upscaling_factor: 0.3
downscaling_factor: 0.3
metrics_interval_s: 2
look_back_period_s: 10
- name: LightLoad
max_ongoing_requests: 3
autoscaling_config:
target_ongoing_requests: 1
min_replicas: 0
initial_replicas: 0
max_replicas: 200
upscale_delay_s: 3
downscale_delay_s: 60
upscaling_factor: 0.3
downscaling_factor: 0.3
metrics_interval_s: 2
look_back_period_s: 10
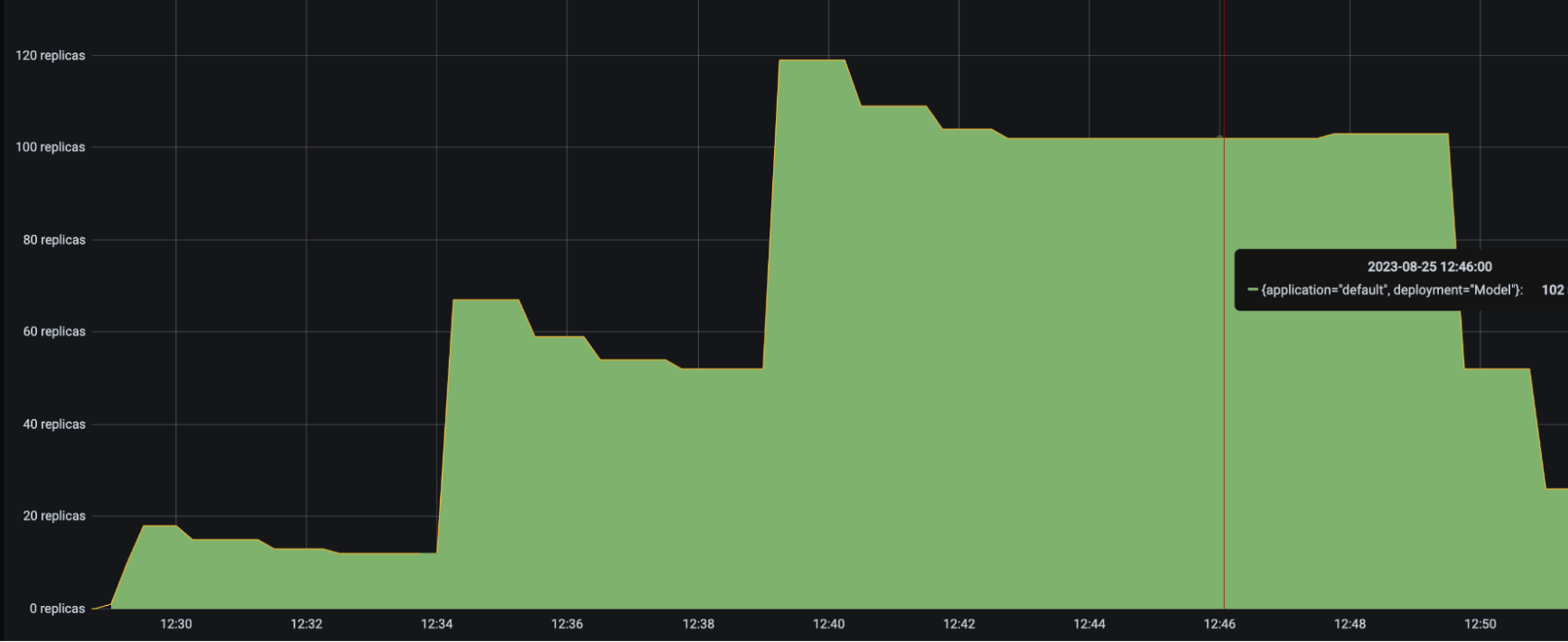
再次运行相同的 Locust 负载测试,生成以下结果
HeavyLoad 和 LightLoad 副本数量 |
|
Driver 副本数量 |
|
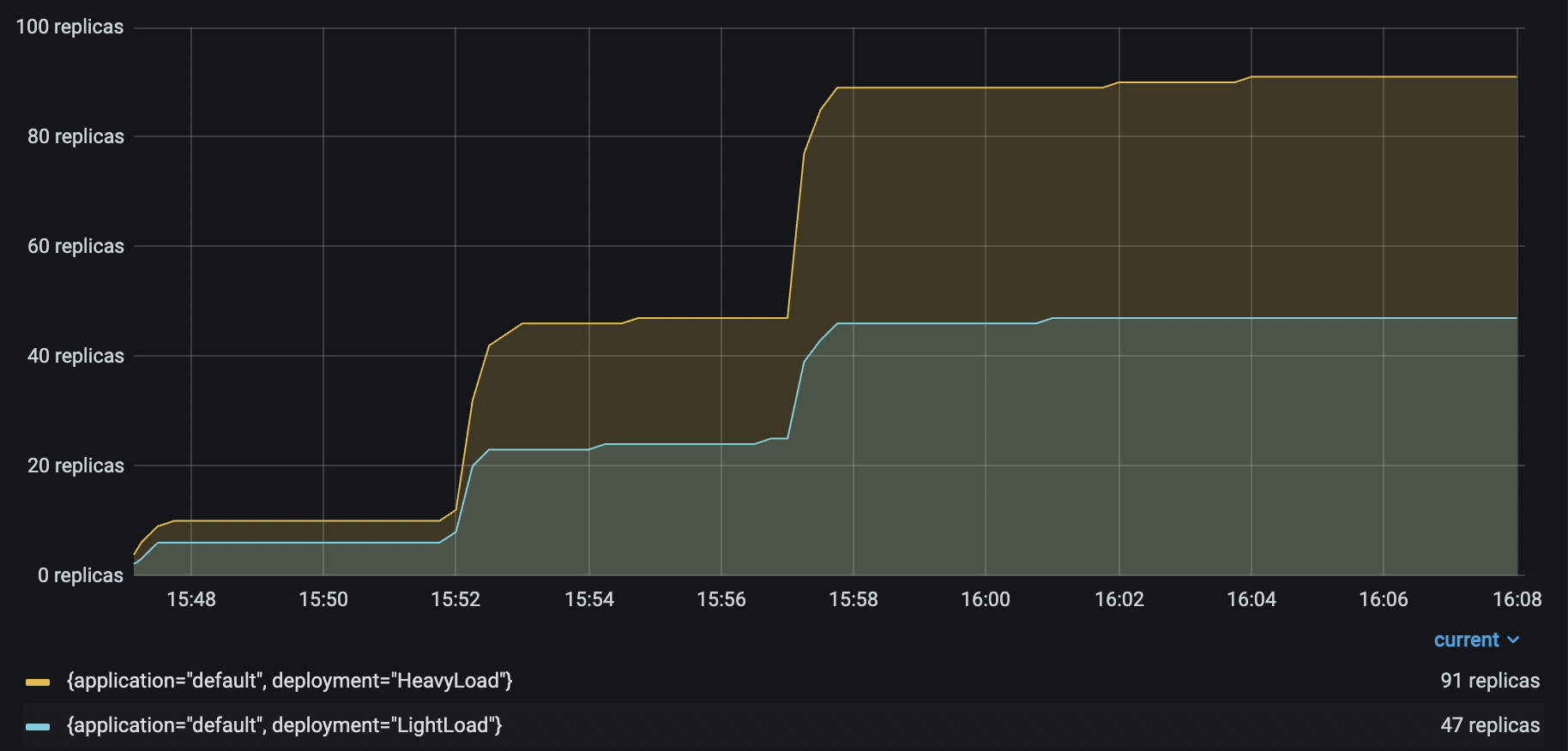
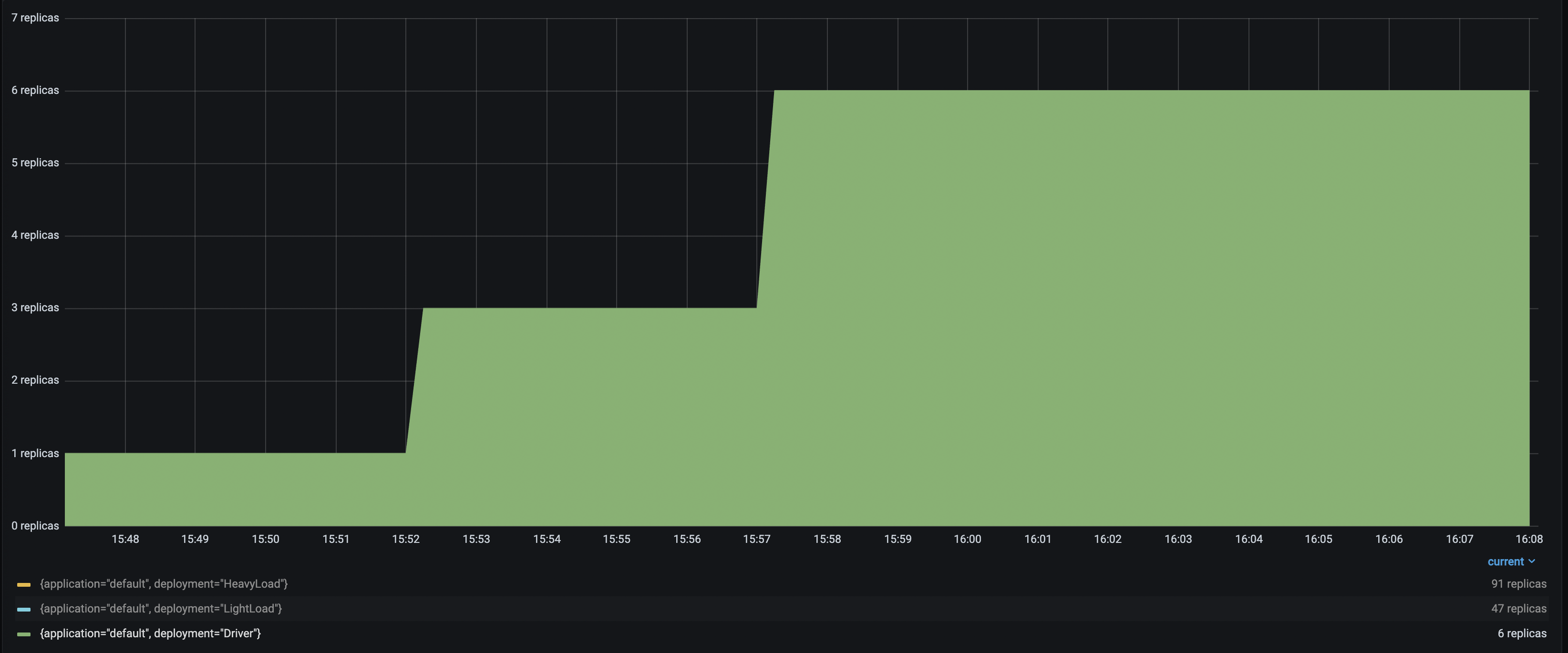
有了多达 6 个 Driver 部署来接收和分发传入请求,HeavyLoad 部署成功扩容到 90 多个副本,LightLoad 扩容到 47 个副本。这种配置有助于在流量负载增加时保持应用延迟的一致性。
改进的 P50 延迟 |
改进的 RPS |
|---|---|
|
|


故障排除指南#
自动扩缩容副本数量不稳定#
如果您的部署副本数量即使在流量相对稳定的情况下仍在持续波动,请尝试以下方法
设置更小的
upscaling_factor和downscaling_factor。将这两个值都设置得小于 1 有助于自动扩缩容程序做出更保守的扩容和缩容决策。这能有效平滑副本数量图,并减少“尖锐边缘”。设置一个与其余自动扩缩容配置匹配的
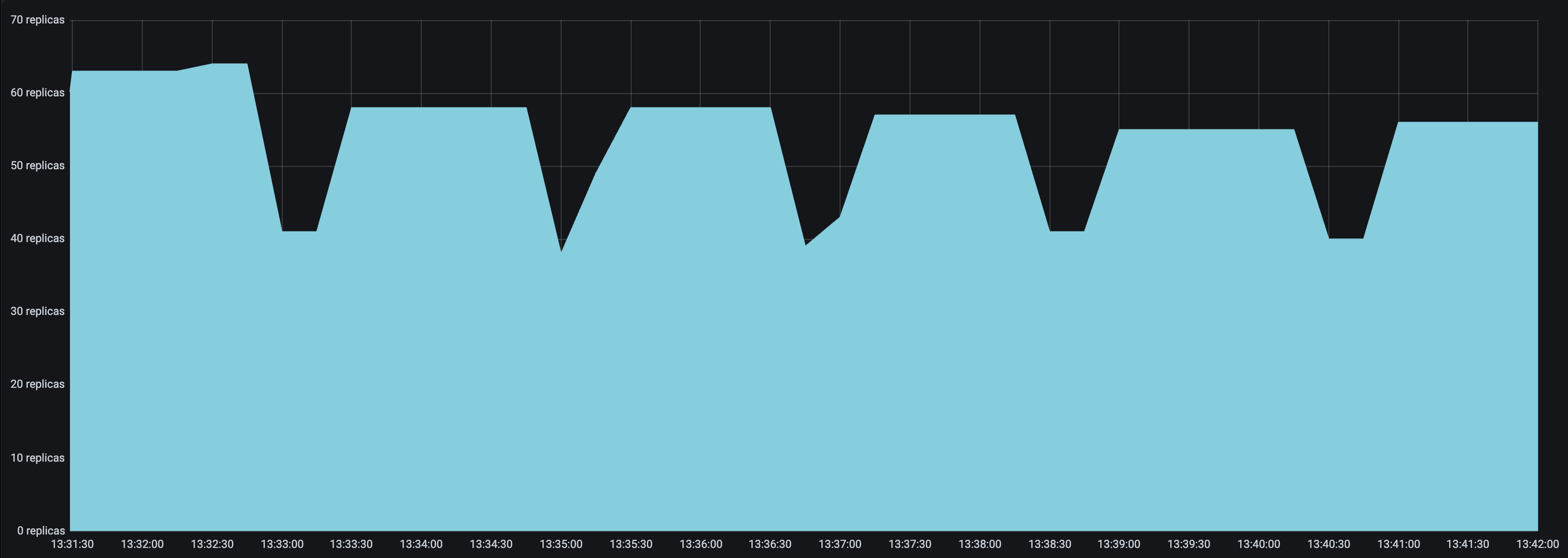
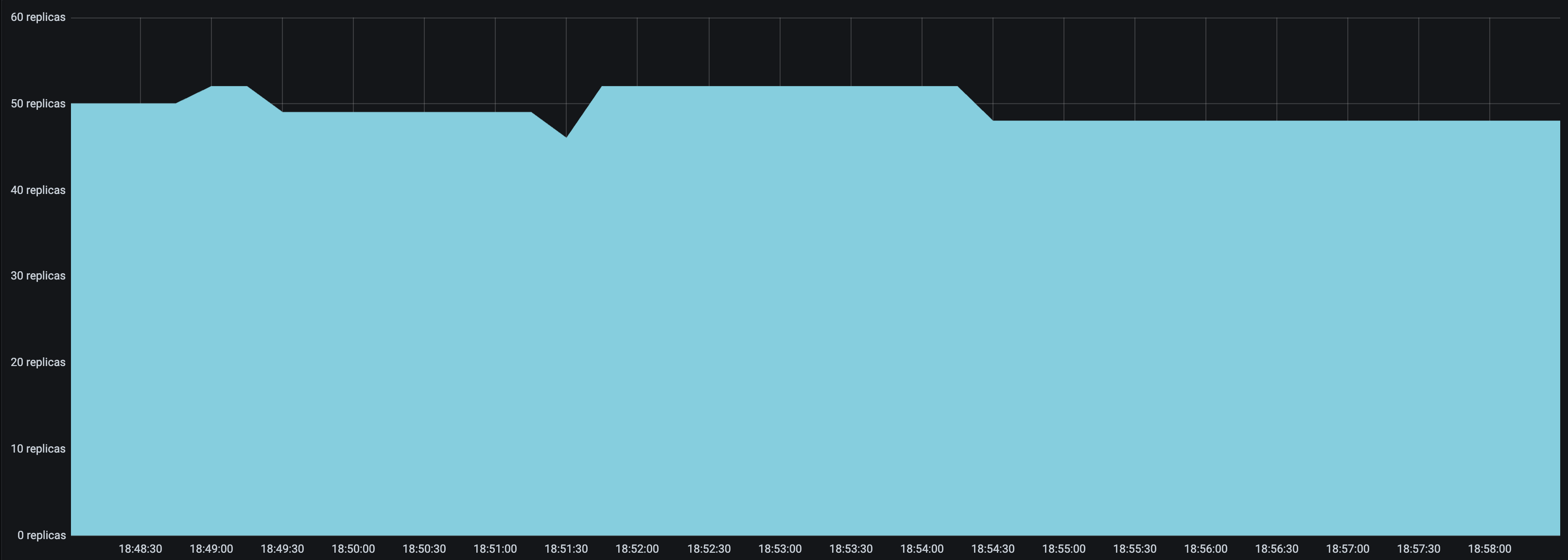
look_back_period_s值。对于较长的扩容和缩容延迟值,较长的回溯周期可能有助于稳定副本图,但对于较短的扩容和缩容延迟值,较短的回溯周期可能更合适。例如,以下副本图显示了upscale_delay_s = 3的部署在使用较长与较短回溯周期时的表现。
|
|
|---|---|
|
|
流量突增期间延迟出现高峰#
如果您预计应用会接收突发流量,同时又希望在非活跃期间缩减部署,您可能会担心部署扩容和响应流量突增的速度。虽然流量突增初期延迟的增加可能无法避免,但您可以尝试以下方法来改善流量突增期间的延迟。
设置较低的
upscale_delay_s。自动扩缩容程序在决定扩容之前总是等待upscale_delay_s秒,因此降低此延迟允许自动扩缩容程序更快地响应流量变化,特别是突发流量。设置较大的
upscaling_factor。如果upscaling_factor > 1,则自动扩缩容程序会比正常情况下更积极地扩容。此设置可以使您的部署对流量突增更敏感。降低
metric_interval_s。务必将metric_interval_s设置为小于或等于upscale_delay_s,否则由于自动扩缩容程序接收新信息的频率不够,扩容会延迟。设置较低的
max_ongoing_requests。如果max_ongoing_requests相对于target_ongoing_requests过高,那么当流量增加时,Serve 可能在新副本启动之前将大多数或所有请求分配给现有副本。此设置可能导致扩容期间出现非常高的延迟。
部署缩容过快#
您可能会观察到部署缩容过快。相反,您可能希望缩容更加保守,以最大限度地提高服务的可用性。
设置较长的
downscale_delay_s。自动扩缩容程序在决定缩容之前总是等待downscale_delay_s秒,因此增加此值可以使您的系统在流量下降后有一个更长的“宽限期”,然后自动扩缩容程序才开始移除副本。设置较小的
downscaling_factor。如果downscaling_factor < 1,则自动扩缩容程序移除的副本数量会少于它认为为了达到目标正在处理请求数量应该移除的数量。换句话说,自动扩缩容程序会做出更保守的缩容决策。
|
|
|---|---|
|
|