KubeRay 内存与可伸缩性基准测试#
架构#
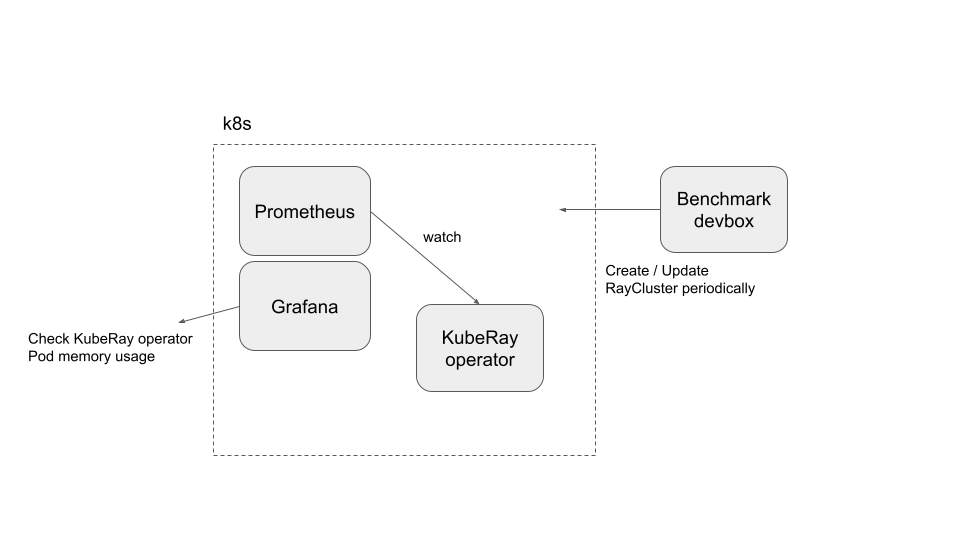
这种架构不是最佳实践,但可以满足当前需求。
准备工作#
克隆 KubeRay 仓库 并切换到 master 分支。本教程需要仓库中的一些文件。
步骤 1:创建一个新的 Kubernetes 集群#
创建一个启用了自动伸缩功能的 GKE 集群。以下命令在 Google GKE 上创建一个名为 kuberay-benchmark-cluster 的 Kubernetes 集群。该集群最多可以扩展到 16 个节点,每个 e2-highcpu-16 类型的节点有 16 个 CPU 和 16 GB 内存。以下实验可能在 Kubernetes 集群中创建多达约 150 个 Pod,每个 Ray Pod 需要 1 个 CPU 和 1 GB 内存。
gcloud container clusters create kuberay-benchmark-cluster \
--num-nodes=1 --min-nodes 0 --max-nodes 16 --enable-autoscaling \
--zone=us-west1-b --machine-type e2-highcpu-16
步骤 2:安装 Prometheus 和 Grafana#
# Path: kuberay/
./install/prometheus/install.sh
按照 prometheus-grafana.md 中的“步骤 2:通过 Helm Chart 安装 Kubernetes Prometheus Stack”来安装 kube-prometheus-stack v48.2.1 Chart 和相关的自定义资源。
步骤 3:安装 KubeRay Operator#
按照 本文档 通过 Helm 仓库安装最新的稳定版 KubeRay Operator。
步骤 4:运行实验#
步骤 4.1:确保
kubectlCLI 可以连接到您的 GKE 集群。如果不能,运行gcloud auth login。步骤 4.2:运行一个实验。
# You can modify `memory_benchmark_utils` to run the experiment you want to run. # (path: benchmark/memory_benchmark/scripts) python3 memory_benchmark_utils.py | tee benchmark_log
步骤 4.3:按照 prometheus-grafana.md 访问 Grafana 的控制面板。
登录 Grafana 控制面板。
点击“Dashboards”。
选择“Kubernetes / Compute Resources / Pod”。
找到 KubeRay Operator Pod 的“Memory Usage”面板。
选择时间范围,然后点击“Inspect”,接着点击“Data”下载 KubeRay Operator Pod 的内存使用数据。
步骤 4.4:删除所有 RayCluster 自定义资源。
kubectl delete --all rayclusters.ray.io --namespace=default
步骤 4.5:对其他实验重复步骤 4.2 到 步骤 4.4。
实验#
此基准测试基于三个实验
实验 1:启动一个包含 1 个 head 和 0 个 worker 的 RayCluster。每隔 20 秒启动一个新集群,直到总共有 150 个 RayCluster 自定义资源。
实验 2:创建一个 Kubernetes 集群,其中只有 1 个 RayCluster。每隔 60 秒向该 RayCluster 添加 5 个新的 worker Pod,直到总数达到 150 个 Pod。
实验 3:每隔 60 秒创建一个 5 节点(1 个 head + 4 个 worker)的 RayCluster,最多创建 30 个 RayCluster 自定义资源。
根据 KubeRay 用户调查,基准测试目标设置为 150 个 Ray Pod 以覆盖大多数用例。
实验结果 (KubeRay v0.6.0)#

您可以通过运行以下命令生成上图
# (path: benchmark/memory_benchmark/scripts) python3 experiment_figures.py # The output image `benchmark_result.png` will be stored in `scripts/`.
如图所示,KubeRay Operator Pod 的内存使用量与 Kubernetes 集群中的 Pod 数量高度正相关。此外,Kubernetes 集群中的自定义资源数量对内存使用量没有显著影响。
请注意,x 轴的“Pod 数量”是指创建的 Pod 数量,而非正在运行的 Pod 数量。如果 Kubernetes 集群没有足够的计算资源,GKE Autopilot 会向集群添加新的 Kubernetes 节点。此过程可能需要几分钟,因此一些 Pod 可能会处于待处理状态。这种延迟可能解释了内存使用量为何受到一定程度的限制。