Ray Tune 入门#
本教程将引导您完成设置 Tune 实验的过程。首先,我们将使用一个 PyTorch 模型,并向您展示如何利用 Ray Tune 优化该模型的超参数。具体来说,我们将利用早停和通过 HyperOpt 实现的贝叶斯优化来完成此操作。
提示
如果您对如何改进本教程有任何建议,请告诉我们!
要运行此示例,您需要安装以下项
$ pip install "ray[tune]" torch torchvision
设置要调优的 PyTorch 模型#
首先,让我们导入一些依赖项。我们导入一些 PyTorch 和 TorchVision 模块来帮助创建和训练模型。此外,我们还将导入 Ray Tune 来帮助我们优化模型。正如您所见,我们使用了一个所谓的调度器,在本例中是 ASHAScheduler,我们将在本教程的后续部分使用它来调优模型。
import numpy as np
import torch
import torch.optim as optim
import torch.nn as nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
from ray import tune
from ray.tune.schedulers import ASHAScheduler
接下来,让我们定义一个我们将要训练的简单 PyTorch 模型。如果您不熟悉 PyTorch,定义模型的最简单方法是实现一个 nn.Module。这要求您使用 __init__ 设置模型,然后实现一个 forward 正向传播。在此示例中,我们使用了一个小型卷积神经网络,它由一个 2D 卷积层、一个全连接层和一个 softmax 函数组成。
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
# In this example, we don't change the model architecture
# due to simplicity.
self.conv1 = nn.Conv2d(1, 3, kernel_size=3)
self.fc = nn.Linear(192, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 3))
x = x.view(-1, 192)
x = self.fc(x)
return F.log_softmax(x, dim=1)
下面,我们实现了用于训练和评估 PyTorch 模型的功能。为此,我们定义了一个 train 函数和一个 test 函数。如果您知道如何执行此操作,请跳到下一节。
训练和评估模型
# Change these values if you want the training to run quicker or slower.
EPOCH_SIZE = 512
TEST_SIZE = 256
def train_func(model, optimizer, train_loader):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# We set this just for the example to run quickly.
if batch_idx * len(data) > EPOCH_SIZE:
return
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
def test_func(model, data_loader):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.eval()
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (data, target) in enumerate(data_loader):
# We set this just for the example to run quickly.
if batch_idx * len(data) > TEST_SIZE:
break
data, target = data.to(device), target.to(device)
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
return correct / total
为 Tune 训练运行设置 Tuner#
下面,我们定义一个函数,用于训练 PyTorch 模型多个 epoch。该函数将在幕后一个单独的 Ray Actor(进程)上执行,因此我们需要将模型的性能反馈给 Tune(它位于主 Python 进程上)。
为此,我们在训练函数中调用 tune.report(),这将性能值发送回 Tune。由于函数在单独的进程上执行,请确保该函数可以由 Ray 序列化。
import os
import tempfile
from ray.tune import Checkpoint
def train_mnist(config):
# Data Setup
mnist_transforms = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))])
train_loader = DataLoader(
datasets.MNIST("~/data", train=True, download=True, transform=mnist_transforms),
batch_size=64,
shuffle=True)
test_loader = DataLoader(
datasets.MNIST("~/data", train=False, transform=mnist_transforms),
batch_size=64,
shuffle=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = ConvNet()
model.to(device)
optimizer = optim.SGD(
model.parameters(), lr=config["lr"], momentum=config["momentum"])
for i in range(10):
train_func(model, optimizer, train_loader)
acc = test_func(model, test_loader)
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
checkpoint = None
if (i + 1) % 5 == 0:
# This saves the model to the trial directory
torch.save(
model.state_dict(),
os.path.join(temp_checkpoint_dir, "model.pth")
)
checkpoint = Checkpoint.from_directory(temp_checkpoint_dir)
# Send the current training result back to Tune
tune.report({"mean_accuracy": acc}, checkpoint=checkpoint)
让我们通过调用 Tuner.fit 运行一次 trial,并从学习率和动量的均匀分布中随机采样。
search_space = {
"lr": tune.sample_from(lambda spec: 10 ** (-10 * np.random.rand())),
"momentum": tune.uniform(0.1, 0.9),
}
# Uncomment this to enable distributed execution
# `ray.init(address="auto")`
# Download the dataset first
datasets.MNIST("~/data", train=True, download=True)
tuner = tune.Tuner(
train_mnist,
param_space=search_space,
)
results = tuner.fit()
Tuner.fit 返回一个 ResultGrid 对象。您可以使用它来绘制此 trial 的性能。
dfs = {result.path: result.metrics_dataframe for result in results}
[d.mean_accuracy.plot() for d in dfs.values()]
注意
Tune 将自动在您的机器或集群上所有可用的核心/GPU 上并行运行 trials。要限制并发 trials 的数量,请使用 ConcurrencyLimiter。
使用自适应逐次减半 (ASHAScheduler) 进行早停#
让我们将早停集成到我们的优化过程中。让我们使用 ASHA,这是一种用于实现规范早停的可伸缩算法。
从高层次上看,ASHA 会终止前景较差的 trials,并为前景较好的 trials 分配更多时间和资源。随着我们的优化过程变得更高效,我们可以通过调整参数 num_samples 来将搜索空间扩大 5 倍。
ASHA 在 Tune 中实现为“Trial Scheduler”。这些 Trial 调度器可以提早终止不良 trials、暂停 trials、克隆 trials 并修改正在运行的 trial 的超参数。有关可用调度器和库集成的更多详细信息,请参阅TrialScheduler 文档。
tuner = tune.Tuner(
train_mnist,
tune_config=tune.TuneConfig(
num_samples=20,
scheduler=ASHAScheduler(metric="mean_accuracy", mode="max"),
),
param_space=search_space,
)
results = tuner.fit()
# Obtain a trial dataframe from all run trials of this `tune.run` call.
dfs = {result.path: result.metrics_dataframe for result in results}
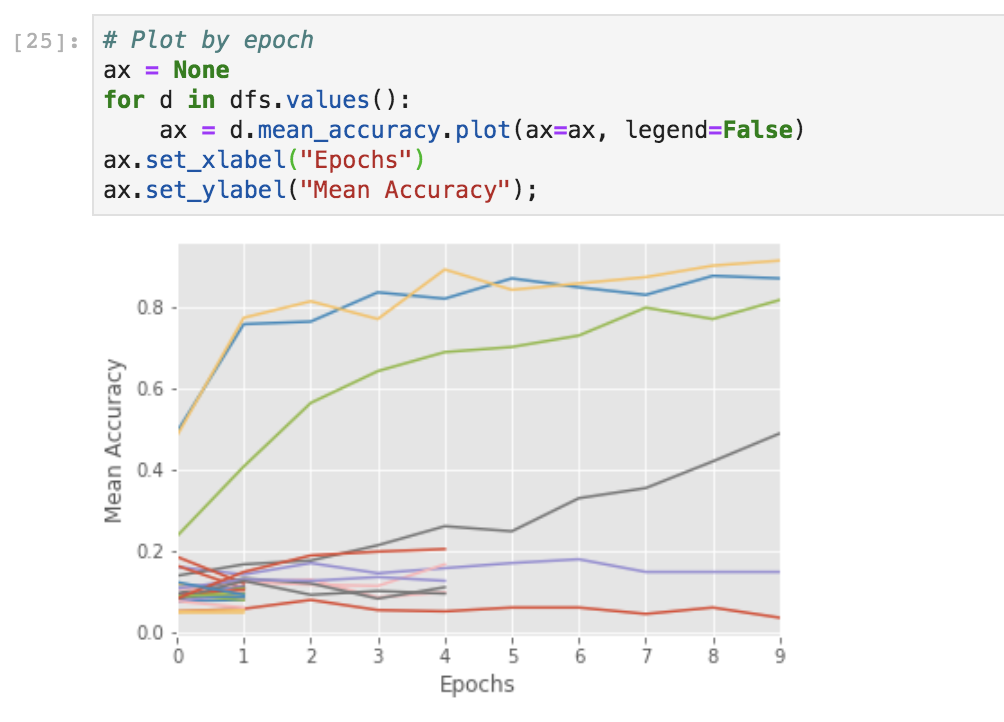
您可以在 Jupyter notebook 中运行以下代码来可视化 trial 进度。
# Plot by epoch
ax = None # This plots everything on the same plot
for d in dfs.values():
ax = d.mean_accuracy.plot(ax=ax, legend=False)
您还可以使用 TensorBoard 可视化结果。
$ tensorboard --logdir {logdir}
在 Tune 中使用搜索算法#
除了Trial 调度器之外,您还可以使用贝叶斯优化等智能搜索技术进一步优化超参数。为此,您可以使用 Tune 的搜索算法。搜索算法利用优化算法智能地探索给定的超参数空间。
请注意,每个库都有特定的定义搜索空间的方式。
from hyperopt import hp
from ray.tune.search.hyperopt import HyperOptSearch
space = {
"lr": hp.loguniform("lr", -10, -1),
"momentum": hp.uniform("momentum", 0.1, 0.9),
}
hyperopt_search = HyperOptSearch(space, metric="mean_accuracy", mode="max")
tuner = tune.Tuner(
train_mnist,
tune_config=tune.TuneConfig(
num_samples=10,
search_alg=hyperopt_search,
),
)
results = tuner.fit()
# To enable GPUs, use this instead:
# analysis = tune.run(
# train_mnist, config=search_space, resources_per_trial={'gpu': 1})
注意
Tune 允许您将某些搜索算法与不同的 trial 调度器结合使用。有关更多详细信息,请参阅此页面。
调优后评估您的模型#
您可以使用 ExperimentAnalysis 对象评估最佳训练模型并检索最佳模型
best_result = results.get_best_result("mean_accuracy", mode="max")
with best_result.checkpoint.as_directory() as checkpoint_dir:
state_dict = torch.load(os.path.join(checkpoint_dir, "model.pth"))
model = ConvNet()
model.load_state_dict(state_dict)
后续步骤#
查看 Tune 教程,获取关于如何在您偏好的机器学习库中使用 Tune 的指南。
浏览我们的示例画廊,了解如何将 Tune 与 PyTorch、XGBoost、Tensorflow 等结合使用。
如果您遇到问题或有任何疑问,请在我们的 Github 上提 issue 告诉我们。
要检查您的应用运行情况,您可以使用 Ray dashboard。