使用 Ray Tune 进行超参数调优#
重要提示
本用户指南展示了如何集成 Ray Train 和 Ray Tune,以便对重新设计的 Ray Train V2(从 Ray 2.43 开始可用)的分布式超参数运行进行调优,方法是启用环境变量 RAY_TRAIN_V2_ENABLED=1。本用户指南假定已启用该环境变量。
有关弃用和迁移的信息,请参阅此处。
Ray Train 可以与 Ray Tune 一起使用,对分布式训练运行进行超参数扫描。当你想在所有可用的集群资源上使用性能最佳的超参数长时间运行之前,对关键超参数进行小范围扫描时,这通常很有用。
快速入门#
在下面的示例中
Tuner启动调优任务,该任务使用不同的超参数配置运行train_driver_fn的试验。train_driver_fn(1) 接收超参数配置,(2) 实例化一个TorchTrainer(或其他框架的 Trainer),(3) 启动分布式训练任务。ScalingConfig定义了单个 Ray Train 运行所需的训练 worker 数量和每个 worker 的资源。train_fn_per_worker是在分布式训练 worker 上执行的 Python 代码,用于一次试验。
import random
import tempfile
import uuid
import ray.train
import ray.train.torch
import ray.tune
from ray.tune.integration.ray_train import TuneReportCallback
# [1] Define your Ray Train worker code.
def train_fn_per_worker(train_loop_config: dict):
# Unpack train worker hyperparameters.
# Train feeds in the `train_loop_config` defined below.
lr = train_loop_config["lr"]
# training code here...
print(
ray.train.get_context().get_world_size(),
ray.train.get_context().get_world_rank(),
train_loop_config,
)
# model = ray.train.torch.prepare_model(...) # Wrap model in DDP.
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
ray.train.report(
{"loss": random.random()},
checkpoint=ray.train.Checkpoint.from_directory(temp_checkpoint_dir),
)
# [2] Define a function that launches the Ray Train run.
def train_driver_fn(config: dict):
# Unpack run-level hyperparameters.
# Tune feeds in hyperparameters defined in the `param_space` below.
num_workers = config["num_workers"]
trainer = ray.train.torch.TorchTrainer(
train_fn_per_worker,
train_loop_config=config["train_loop_config"],
scaling_config=ray.train.ScalingConfig(
num_workers=num_workers,
# Uncomment to use GPUs.
# use_gpu=True,
),
run_config=ray.train.RunConfig(
# [3] Assign unique names to each run.
# Recommendation: use the trial id as part of the run name.
name=f"train-trial_id={ray.tune.get_context().get_trial_id()}",
# [4] (Optional) Pass in a `TuneReportCallback` to propagate
# reported results to the Tuner.
callbacks=[TuneReportCallback()],
# (If multi-node, configure S3 / NFS as the storage path.)
# storage_path="s3://...",
),
)
trainer.fit()
# Launch a single Train run.
train_driver_fn({"num_workers": 4, "train_loop_config": {"lr": 1e-3}})
# Launch a sweep of hyperparameters with Ray Tune.
tuner = ray.tune.Tuner(
train_driver_fn,
param_space={
"num_workers": ray.tune.choice([2, 4]),
"train_loop_config": {
"lr": ray.tune.grid_search([1e-3, 3e-4]),
"batch_size": ray.tune.grid_search([32, 64]),
},
},
run_config=ray.tune.RunConfig(
name=f"tune_train_example-{uuid.uuid4().hex[:6]}",
# (If multi-node, configure S3 / NFS as the storage path.)
# storage_path="s3://...",
),
# [5] (Optional) Set the maximum number of concurrent trials
# in order to prevent too many Train driver processes from
# being launched at once.
tune_config=ray.tune.TuneConfig(max_concurrent_trials=2),
)
results = tuner.fit()
print(results.get_best_result(metric="loss", mode="min"))
Ray Tune 提供了什么?#
Ray Tune 提供了以下实用工具:
本用户指南仅侧重于 Ray Train 和 Ray Tune 之间的集成层。有关 Ray Tune 的更多详细信息,请参阅 Ray Tune 文档。
配置多个试验的资源#
Ray Tune 启动多个试验,这些试验在远程 Ray actor 中运行用户定义的函数,每个试验都有不同的采样超参数配置。
单独使用 Ray Tune 时,试验直接在 Ray actor 内部进行计算。例如,每个试验可以请求 1 个 GPU 并在远程 actor 内部执行一些单进程模型训练。在 Ray Tune 函数中使用 Ray Train 时,Tune 试验实际上并没有在这个 actor 内部进行大量的计算——它只是充当一个驱动进程,用于启动和监控在其他地方运行的 Ray Train worker。
Ray Train 通过 ScalingConfig 请求自己的资源。详情请参阅配置规模和 GPU。
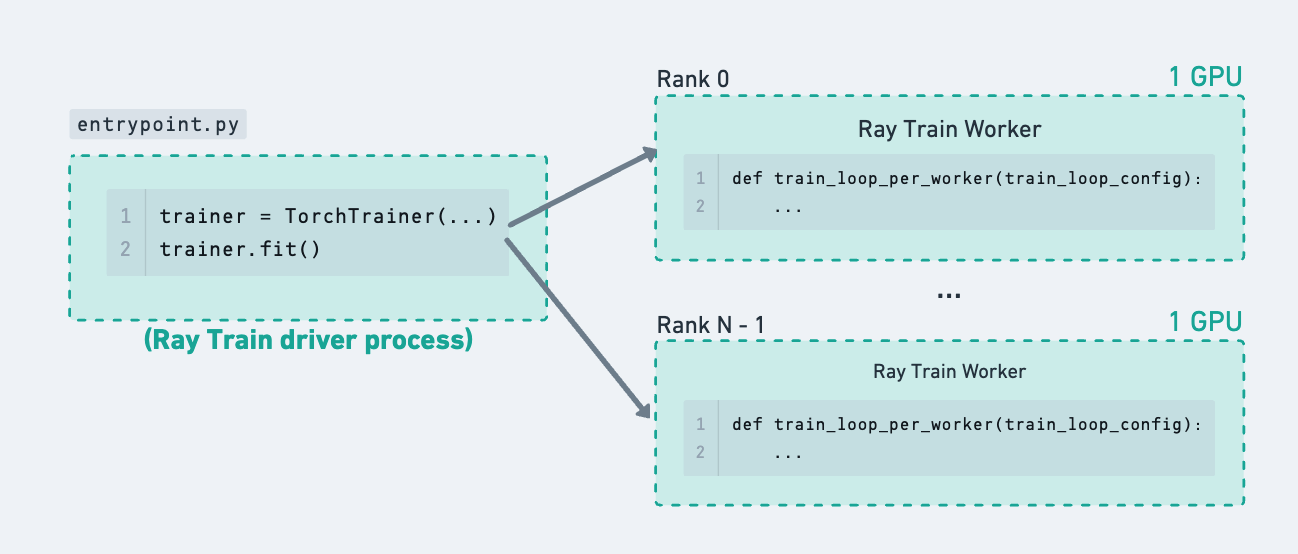
单个 Ray Train 运行,展示在下图中如何使用 Ray Tune 仅在此进程树中添加一层层次结构。#
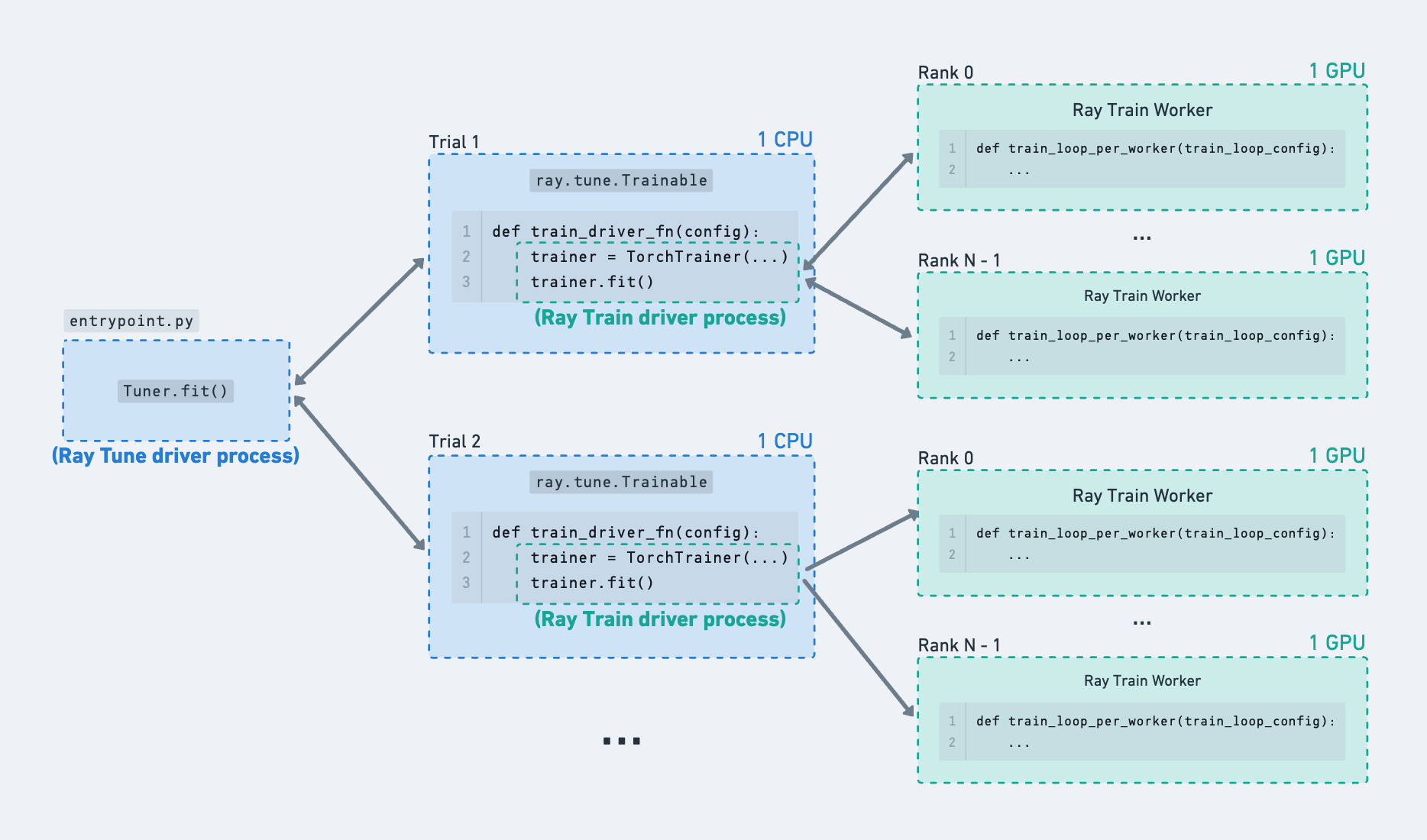
从 Ray Tune 试验中启动 Ray Train 运行的示例。#
限制并发 Ray Train 运行数量#
Ray Train 运行只有在一次性获取所有 worker 的资源时才能启动。这意味着多个发起 Train 运行的 Tune 试验将竞争 Ray 集群中可用的逻辑资源。
如果存在 GPU 等限制性集群资源,则无法并发运行所有超参数配置的训练。由于集群仅有足够的资源同时运行少数试验,请在 Tuner 上设置 tune.TuneConfig(max_concurrent_trials) 来限制“正在进行中”的 Train 运行数量,从而避免任何试验因资源不足而饥饿。
# For a fixed size cluster, calculate this based on the limiting resource (ex: GPUs).
total_cluster_gpus = 8
num_gpu_workers_per_trial = 4
max_concurrent_trials = total_cluster_gpus // num_gpu_workers_per_trial
def train_driver_fn(config: dict):
trainer = ray.train.torch.TorchTrainer(
train_fn_per_worker,
scaling_config=ray.train.ScalingConfig(
num_workers=num_gpu_workers_per_trial, use_gpu=True
),
)
trainer.fit()
tuner = ray.tune.Tuner(
train_driver_fn,
tune_config=ray.tune.TuneConfig(max_concurrent_trials=max_concurrent_trials),
)
举个具体的例子,考虑一个固定大小的集群,有 128 个 CPU 和 8 个 GPU。
Tuner(param_space)使用网格搜索扫描 4 个超参数配置:param_space={“train_loop_config”: {“batch_size”: tune.grid_search([8, 16, 32, 64])}}每个 Ray Train 运行配置为使用 4 个 GPU worker 进行训练:
ScalingConfig(num_workers=4, use_gpu=True)。由于只有 8 个 GPU,一次只能有 2 个 Train 运行获取全部资源。然而,由于集群中有许多可用的 CPU,总共 4 个 Ray Tune 试验(默认请求 1 个 CPU)可以立即启动。这导致启动了 2 个额外的 Ray Tune 试验进程,尽管它们的内部 Ray Train 运行只是等待资源,直到其他试验完成。这会在 Train 等待资源时引入一些冗余的日志消息。如果超参数配置的总数很大,Ray Tune 试验进程的数量也可能过多。
为了解决这个问题,设置
Tuner(tune_config=tune.TuneConfig(max_concurrent_trials=2))。现在,一次只会运行两个 Ray Tune 试验进程。这个数字可以根据限制性集群资源以及每个试验所需的该资源数量来计算。
高级:设置 Train 驱动程序资源#
默认的 Train 驱动程序作为 Ray Tune 函数运行,使用 1 个 CPU。Ray Tune 会将这些函数调度到集群中任何有空闲逻辑 CPU 资源的节点上运行。
建议:如果你正在启动长时间运行的训练任务或使用 Spot 实例,这些充当 Ray Train 驱动进程的 Tune 函数应该在“安全节点”上运行,这些节点的宕机风险较低。例如,它们不应该被调度到可抢占的 Spot 实例上运行,也不应该与训练 worker colocated。这可以是你的集群中的 Head Node 或专用的 CPU 节点。
这是因为 Ray Train 驱动进程负责处理 worker 进程的容错,而 worker 进程更容易出错。运行 Train worker 的节点可能会由于 Spot 抢占或用户定义的模型训练代码引起的其他错误而崩溃。
如果 Train worker 节点发生故障,仍然在另一个节点上运行的 Ray Train 驱动进程可以优雅地处理该错误。
另一方面,如果驱动进程发生故障,那么所有 Ray Train worker 都将非优雅地退出,并且部分运行状态可能无法完全提交。
实现这种行为的一种方法是在某些节点类型上设置自定义资源,并配置 Tune 函数请求这些资源。
# Cluster setup:
# head_node:
# resources:
# CPU: 16.0
# worker_node_cpu:
# resources:
# CPU: 32.0
# TRAIN_DRIVER_RESOURCE: 1.0
# worker_node_gpu:
# resources:
# GPU: 4.0
import ray.tune
def train_driver_fn(config):
# trainer = TorchTrainer(...)
...
tuner = ray.tune.Tuner(
ray.tune.with_resources(
train_driver_fn,
# Note: 0.01 is an arbitrary value to schedule the actor
# onto the `worker_node_cpu` node type.
{"TRAIN_DRIVER_RESOURCE": 0.01},
),
)
报告指标和检查点#
Ray Train 和 Ray Tune 都提供了实用工具,通过 ray.train.report 和 ray.tune.report API 来帮助上传和跟踪检查点。有关更多详细信息,请参阅保存和加载检查点用户指南。
如果 Ray Train worker 报告了检查点,则不需要在 Train driver 级别另存一个 Ray Tune 检查点,因为它不包含任何额外的训练状态。Ray Train 驱动进程已经会定期将其状态快照到配置的 storage_path,这在下一节的容错部分中进一步描述。
为了从 Tuner 输出访问检查点,可以将检查点路径作为指标附加。提供的 TuneReportCallback 通过将报告的 Ray Train 结果传播到 Ray Tune 来实现此目的,检查点路径作为单独的指标附加在那里。
高级:容错#
如果运行 Ray Train 驱动进程的 Ray Tune 试验崩溃,您可以通过 ray.tune.Tuner(run_config=ray.tune.RunConfig(failure_config)) 在 Ray Tune 端启用试验容错。
Ray Train 端的容错是单独配置和处理的。有关更多详细信息,请参阅处理故障和节点抢占用户指南。
import tempfile
import ray.tune
import ray.train
import ray.train.torch
def train_fn_per_worker(train_loop_config: dict):
# [1] Train worker restoration logic.
checkpoint = ray.train.get_checkpoint()
if checkpoint:
with checkpoint.as_directory() as temp_checkpoint_dir:
# model.load_state_dict(torch.load(...))
...
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
# torch.save(...)
ray.train.report(
{"loss": 0.1},
checkpoint=ray.train.Checkpoint.from_directory(temp_checkpoint_dir),
)
def train_fn_driver(config: dict):
trainer = ray.train.torch.TorchTrainer(
train_fn_per_worker,
run_config=ray.train.RunConfig(
# [2] Train driver restoration is automatic, as long as
# the (storage_path, name) remains the same across trial restarts.
# The easiest way to do this is to attach the trial ID in the name.
# **Do not include any timestamps or random values in the name.**
name=f"train-trial_id={ray.tune.get_context().get_trial_id()}",
# [3] Enable worker-level fault tolerance to gracefully handle
# Train worker failures.
failure_config=ray.train.FailureConfig(max_failures=3),
# (If multi-node, configure S3 / NFS as the storage path.)
# storage_path="s3://...",
),
)
trainer.fit()
tuner = ray.tune.Tuner(
train_fn_driver,
run_config=ray.tune.RunConfig(
# [4] Enable trial-level fault tolerance to gracefully handle
# Train driver process failures.
failure_config=ray.tune.FailureConfig(max_failures=3)
),
)
tuner.fit()
高级:使用 Ray Tune 回调#
Ray Tune 回调应在 Tuner 级别传递到 ray.tune.RunConfig(callbacks) 中。
对于依赖于内置或自定义 Ray Tune 回调行为的 Ray Train 用户,可以通过将 Ray Train 作为单个试验 Tune 运行,并将回调传递给 Tuner 来使用它们。
如果任何回调功能依赖于报告的指标,请确保将 ray.tune.integration.ray_train.TuneReportCallback 传递给 trainer 回调,这将结果传播到 Tuner。
import ray.tune
from ray.tune.integration.ray_train import TuneReportCallback
from ray.tune.logger import TBXLoggerCallback
def train_driver_fn(config: dict):
trainer = TorchTrainer(
...,
run_config=ray.train.RunConfig(..., callbacks=[TuneReportCallback()])
)
trainer.fit()
tuner = ray.tune.Tuner(
train_driver_fn,
run_config=ray.tune.RunConfig(callbacks=[TBXLoggerCallback()])
)
Tuner(trainer) API 弃用#
直接接受 Ray Train trainer 实例的 Tuner(trainer) API 已在 Ray 2.43 中弃用,并将在未来的版本中移除。
动机#
此 API 更改提供了以下几个优点:
更好地关注点分离:解耦 Ray Train 和 Ray Tune 的职责
改进的配置体验:使超参数和运行配置更加清晰和灵活
迁移步骤#
要从旧的 Tuner(trainer) API 迁移到新模式:
启用环境变量
RAY_TRAIN_V2_ENABLED=1。将
Tuner(trainer)替换为基于函数的方法,其中 Ray Train 在 Tune 试验内部启动。将你的训练逻辑移到一个驱动函数中,Tune 会使用不同的超参数调用该函数。
更多资源#
Train V2 REP:关于 API 更改的技术细节
Train V2 迁移指南:Train V2 的完整迁移指南
使用 Ray Tune 进行超参数调优(已弃用 API):旧 API 的文档