一个使用 Ray Core 的简单 MapReduce 示例#

本示例展示了如何使用 Ray 来解决一个常见的分布式计算问题——统计跨多个文档的单词出现次数。其复杂性在于处理大型语料库,需要多个计算节点来处理数据。使用 Ray 实现 MapReduce 的简洁性是分布式计算领域的一个重要里程碑。许多流行的大数据技术,如 Hadoop,都建立在此编程模型之上,这突显了使用 Ray Core 的影响力。
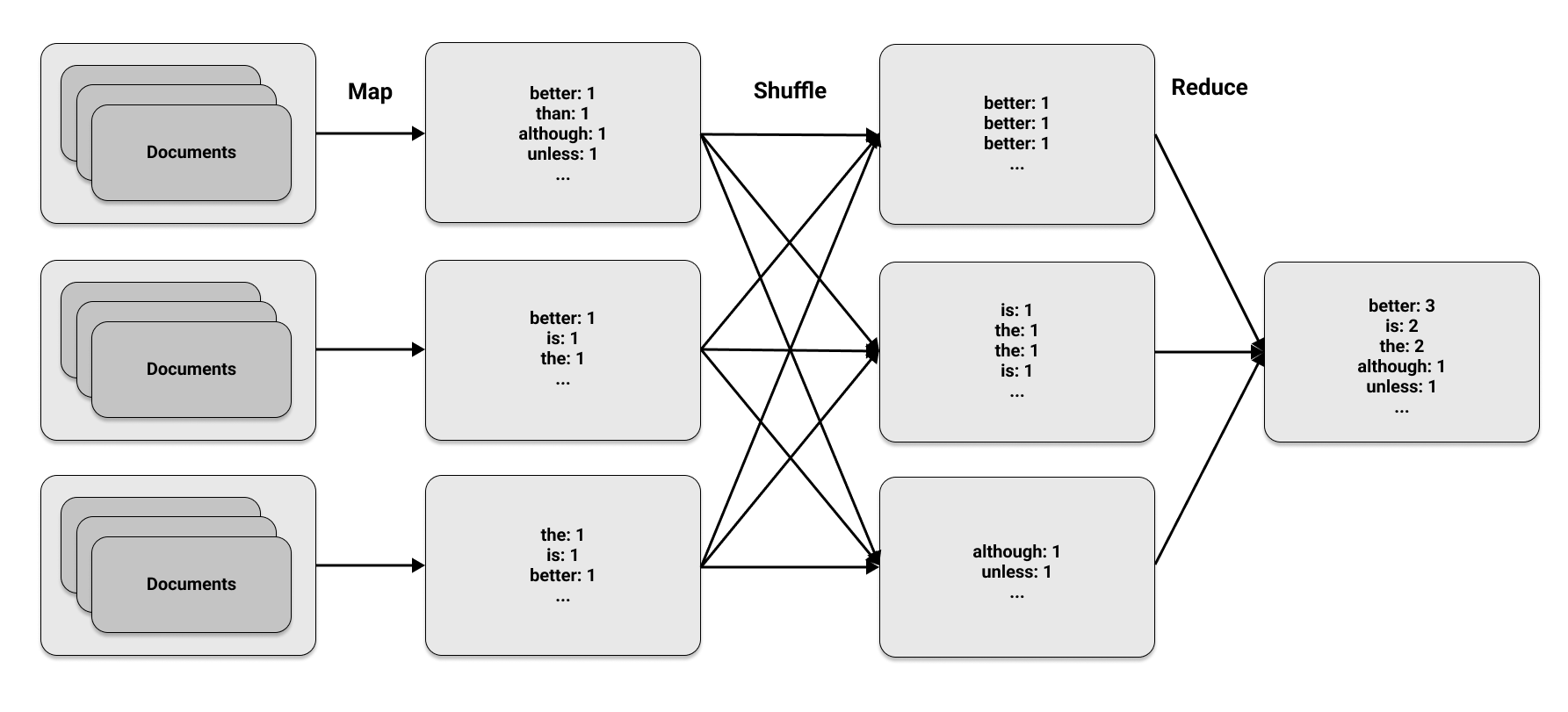
MapReduce 方法分为三个阶段
Map 阶段 Map 阶段将指定函数应用于数据集中的元素进行转换或映射。它生成键值对:键代表一个元素,值是为该元素计算的指标。为了统计每个单词在文档中出现的次数,map 函数在每次单词出现时输出对
(word, 1),表示它被找到了一次。Shuffle 阶段 Shuffle 阶段收集 map 阶段的所有输出,并按键组织它们。当在多个计算节点上找到相同的键时,此阶段涉及在不同节点之间传输或混洗数据。如果 map 阶段生成四次
(word, 1)对,则 shuffle 阶段会将该单词的所有出现次数放在同一节点上。Reduce 阶段 Reduce 阶段聚合来自 shuffle 阶段的元素。每个单词的总出现次数是每个节点上出现次数的总和。例如,四个
(word, 1)实例合并后,最终计数为word: 4。
第一阶段和最后一阶段在 MapReduce 的名称中,但中间阶段同样关键。这些阶段看似简单,但它们的力量在于在多台机器上并发运行。下图说明了在文档集上执行的三个 MapReduce 阶段
加载数据#
我们使用 Python 实现用于单词计数的 MapReduce 算法,并使用 Ray 来并行化计算。我们首先加载 Python 之禅(Python 社区的一组编码指南)中的一些示例数据。按照彩蛋传统,可以通过在 Python 会话中键入 import this 来访问 Python 之禅。我们将 Python 之禅分为三个单独的“文档”,方法是将每一行视为一个独立实体,然后将这些行分成三个分区。
import subprocess
zen_of_python = subprocess.check_output(["python", "-c", "import this"])
corpus = zen_of_python.split()
num_partitions = 3
chunk = len(corpus) // num_partitions
partitions = [
corpus[i * chunk: (i + 1) * chunk] for i in range(num_partitions)
]
映射数据#
为了确定 map 阶段,我们需要一个用于每个文档的 map 函数。对于文档中找到的每个单词,输出为对 (word, 1)。对于加载为 Python 字符串的基本文本文档,过程如下
def map_function(document):
for word in document.lower().split():
yield word, 1
我们使用 apply_map 函数处理大量文档集合,方法是使用 @ray.remote 装饰器将其标记为 Ray 中的一个任务。当我们调用 apply_map 时,我们将其应用于三组文档数据 (num_partitions=3)。apply_map 函数返回三个列表,每个分区一个,以便 Ray 可以重新排列 map 阶段的结果并将其分发到相应的节点。
import ray
@ray.remote
def apply_map(corpus, num_partitions=3):
map_results = [list() for _ in range(num_partitions)]
for document in corpus:
for result in map_function(document):
first_letter = result[0].decode("utf-8")[0]
word_index = ord(first_letter) % num_partitions
map_results[word_index].append(result)
return map_results
对于可以存储在单台机器上的文本语料库,map 阶段不是必需的。但是,当数据需要在多个节点上划分时,map 阶段就很有用了。为了并行地对语料库应用 map 阶段,我们像前面的示例一样,对 apply_map 进行远程调用。主要区别在于我们希望使用 num_returns 参数返回三个结果(每个分区一个)。
map_results = [
apply_map.options(num_returns=num_partitions)
.remote(data, num_partitions)
for data in partitions
]
for i in range(num_partitions):
mapper_results = ray.get(map_results[i])
for j, result in enumerate(mapper_results):
print(f"Mapper {i}, return value {j}: {result[:2]}")
Mapper 0, return value 0: [(b'of', 1), (b'is', 1)]
Mapper 0, return value 1: [(b'python,', 1), (b'peters', 1)]
Mapper 0, return value 2: [(b'the', 1), (b'zen', 1)]
Mapper 1, return value 0: [(b'unless', 1), (b'in', 1)]
Mapper 1, return value 1: [(b'although', 1), (b'practicality', 1)]
Mapper 1, return value 2: [(b'beats', 1), (b'errors', 1)]
Mapper 2, return value 0: [(b'is', 1), (b'is', 1)]
Mapper 2, return value 1: [(b'although', 1), (b'a', 1)]
Mapper 2, return value 2: [(b'better', 1), (b'than', 1)]
本示例演示了如何使用 ray.get 在驱动程序上收集数据。如果在映射阶段后要继续执行另一个任务,则无需这样做。下一节将展示如何高效地将所有阶段一起运行。
混洗和归约数据#
reduce 阶段的目标是将所有来自第 j 个返回值对传输到同一节点。在 reduce 阶段,我们创建一个字典,用于汇总每个分区上的所有单词出现次数
@ray.remote
def apply_reduce(*results):
reduce_results = dict()
for res in results:
for key, value in res:
if key not in reduce_results:
reduce_results[key] = 0
reduce_results[key] += value
return reduce_results
我们可以从每个 mapper 中获取第 j 个返回值,并使用以下方法将其发送到第 j 个 reducer。请注意,此代码适用于无法容纳在单台机器上的大型数据集,因为我们使用 Ray 对象而不是实际数据本身来传递数据的引用。map 和 reduce 阶段都可以在任何 Ray 集群上运行,并且 Ray 处理数据混洗。
outputs = []
for i in range(num_partitions):
outputs.append(
apply_reduce.remote(*[partition[i] for partition in map_results])
)
counts = {k: v for output in ray.get(outputs) for k, v in output.items()}
sorted_counts = sorted(counts.items(), key=lambda item: item[1], reverse=True)
for count in sorted_counts:
print(f"{count[0].decode('utf-8')}: {count[1]}")
is: 10
better: 8
than: 8
the: 6
to: 5
of: 3
although: 3
be: 3
unless: 2
one: 2
if: 2
implementation: 2
idea.: 2
special: 2
should: 2
do: 2
may: 2
a: 2
never: 2
way: 2
explain,: 2
ugly.: 1
implicit.: 1
complex.: 1
complex: 1
complicated.: 1
flat: 1
readability: 1
counts.: 1
cases: 1
rules.: 1
in: 1
face: 1
refuse: 1
one--: 1
only: 1
--obvious: 1
it.: 1
obvious: 1
first: 1
often: 1
*right*: 1
it's: 1
it: 1
idea: 1
--: 1
let's: 1
python,: 1
peters: 1
simple: 1
sparse: 1
dense.: 1
aren't: 1
practicality: 1
purity.: 1
pass: 1
silently.: 1
silenced.: 1
ambiguity,: 1
guess.: 1
and: 1
preferably: 1
at: 1
you're: 1
dutch.: 1
good: 1
are: 1
great: 1
more: 1
zen: 1
by: 1
tim: 1
beautiful: 1
explicit: 1
nested.: 1
enough: 1
break: 1
beats: 1
errors: 1
explicitly: 1
temptation: 1
there: 1
that: 1
not: 1
now: 1
never.: 1
now.: 1
hard: 1
bad: 1
easy: 1
namespaces: 1
honking: 1
those!: 1
要深入了解如何使用 Ray 在多个节点上扩展 MapReduce 任务,包括内存管理,请阅读关于此主题的博客文章。
总结#
这个 MapReduce 示例展示了 Ray 编程模型的灵活性。生产级的 MapReduce 实现需要更多努力,但能够快速重现这样的常见算法大有裨益。在 MapReduce 的早期,大约在 2010 年,这种范式通常是表达工作负载的唯一可用模型。借助 Ray,任何中级 Python 程序员都可以访问各种有趣的分布式计算模式。
要了解有关 Ray 的更多信息,尤其是 Ray Core,请参阅Ray Core 示例库,或我们的用例库中的 ML 工作负载。此 MapReduce 示例可在“学习 Ray”中找到,其中包含更多类似的示例。