监控您的工作负载#
本节通过查看以下内容,帮助您调试和监控 Dataset 的执行:
Ray Data 进度条#
当您执行一个 Dataset 时,Ray Data 会在控制台显示一组进度条。这些进度条显示了各种执行和进度相关的指标,包括已完成/剩余的行数、资源使用情况以及任务/Actor 状态。请参阅带注释的图片,了解如何解释进度条输出的详细信息。

关于进度条的一些补充说明
进度条每秒更新一次;资源使用、指标和任务/Actor 状态可能需要长达 5 秒才能更新。
当任务部分包含标签
[backpressure]时,这表示操作符处于背压状态,意味着操作符将暂停提交更多任务,直到下游操作符准备好接收更多数据。全局资源使用是所有操作符使用资源的汇总,包括活动状态和请求状态(包括待调度和待节点分配)。
配置进度条#
根据您的用例,您可能对完整的进度条输出不感兴趣,或者希望完全关闭它们。Ray Data 提供了几种实现方法:
禁用操作符级别进度条:设置
DataContext.get_current().enable_operator_progress_bars = False。这只会显示全局进度条,并省略操作符级别的进度条。禁用所有进度条:设置
DataContext.get_current().enable_progress_bars = False。这将禁用 Ray Data 中与数据集执行相关的所有进度条。禁用
ray_tqdm:设置DataContext.get_current().use_ray_tqdm = False。这将配置 Ray Data 使用基础的tqdm库,而非自定义的分布式tqdm实现,这在分布式环境下调试日志问题时可能很有用。
对于名称长度超过 100 个字符阈值的操作符,Ray Data 默认会截断名称,以防止操作符名称过长导致进度条过宽无法适应屏幕的情况。
要关闭此行为并显示完整的操作符名称,请设置
DataContext.get_current().enable_progress_bar_name_truncation = False。要更改名称截断的阈值,请更新常量
ray.data._internal.progress_bar.ProgressBar.MAX_NAME_LENGTH = 42。
Ray Data 控制面板#
Ray Data 在 Dataset 执行期间实时发出 Prometheus 指标。这些指标按数据集和操作符进行标记,并在 Ray 控制面板的多个视图中显示。
注意
大多数指标仅适用于使用 map 操作的物理操作符。例如,由 map_batches()、map() 和 flat_map() 创建的物理操作符。
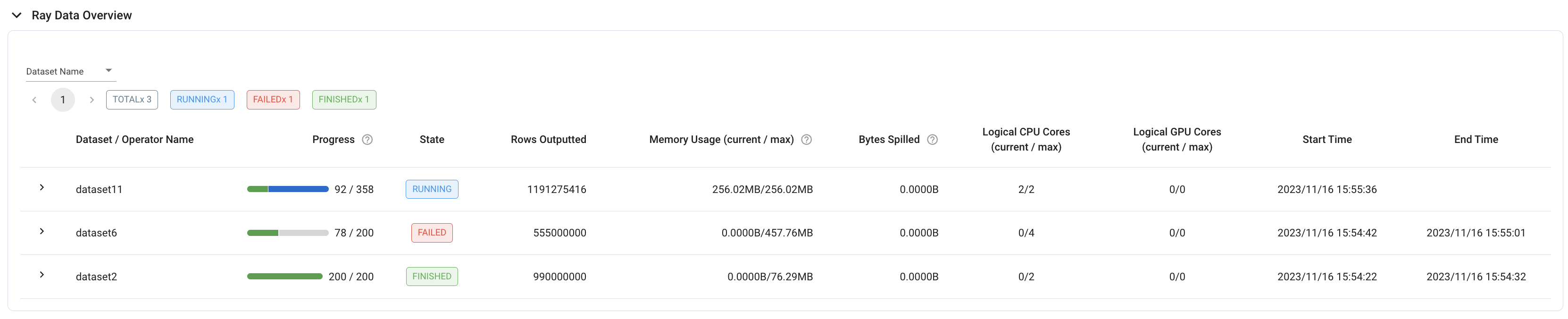
作业:Ray Data 概览#
要查看集群上运行过的所有数据集的概览,请参阅 作业视图 中的 Ray Data 概览。此表格在第一个数据集开始在集群上执行后出现,并显示数据集详细信息,例如:
执行进度(以块为单位衡量)
执行状态(运行中、失败或完成)
数据集开始/结束时间
数据集级别指标(例如,所有操作符处理的行数总和)
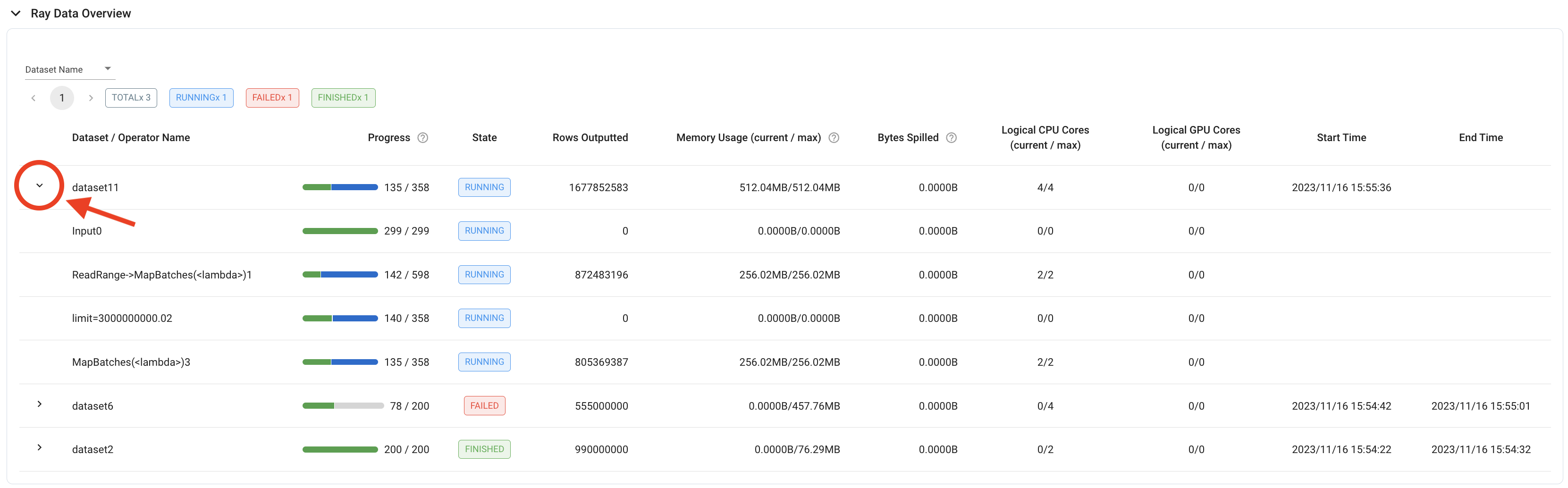
要获得更细粒度的概览,表格中的每个数据集行也可以展开,显示各个操作符的相同详细信息。
提示
要评估数据集级别指标,如果直接对所有单个操作符的值求和不合适,那么查看最后一个操作符的操作符级别指标可能更有用。例如,要计算数据集的吞吐量,请使用数据集最后一个操作符的“输出行数 (Rows Outputted)”,因为数据集级别指标包含所有操作符输出行数的总和。
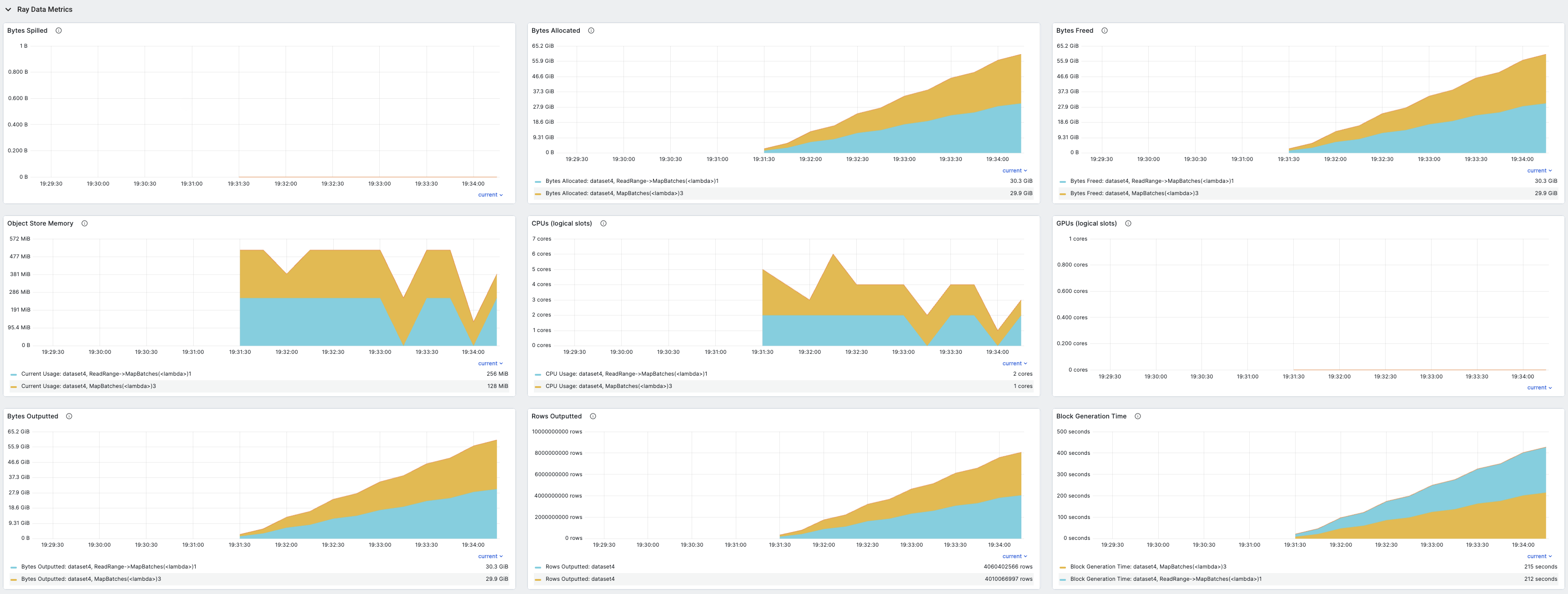
Ray 控制面板指标#
要查看这些指标的时间序列视图,请参阅 指标视图 中的 Ray Data 部分。此部分包含 Ray Data 发出的所有指标的时间序列图。执行指标按数据集和操作符分组,迭代指标按数据集分组。
记录的指标包括:
对象从对象存储溢出到磁盘的字节数
在对象存储中分配的对象字节数
在对象存储中释放的对象字节数
对象存储中当前对象总字节数
分配给数据集操作符的逻辑 CPU 数
分配给数据集操作符的逻辑 GPU 数
数据集操作符输出的字节数
数据集操作符输出的行数
数据操作符接收的输入块数
数据操作符在任务中处理的输入块/字节数
数据操作符向任务提交的输入字节数
数据操作符在任务中生成的输出块/字节/行数
下游操作符提取的输出块/字节数
已完成任务的输出块/字节数
已提交任务数
运行中任务数
至少生成一个输出块的任务数
已完成任务数
失败任务数
操作符内部输入队列大小(以块/字节为单位)
操作符内部输出队列大小(以块/字节为单位)
挂起任务中使用的块大小
对象存储中释放的内存
对象存储中溢出的内存
生成块所花费的时间
任务提交背压所花费的时间
初始化迭代所花费的时间。
迭代期间用户代码阻塞的时间。
迭代期间在用户代码中花费的时间。
要了解有关 Ray 控制面板的更多信息,包括详细的设置说明,请参阅 Ray Dashboard。
Ray Data 日志#
在执行期间,Ray Data 会定期将更新记录到 ray-data.log 文件中。
每隔五秒,Ray Data 会记录数据集中每个操作符的执行进度。要获取更频繁的更新,请设置 RAY_DATA_TRACE_SCHEDULING=1,以便在每个任务分派后记录进度。
Execution Progress:
0: - Input: 0 active, 0 queued, 0.0 MiB objects, Blocks Outputted: 200/200
1: - ReadRange->MapBatches(<lambda>): 10 active, 190 queued, 381.47 MiB objects, Blocks Outputted: 100/200
当操作符完成时,该操作符的指标也会被记录。
Operator InputDataBuffer[Input] -> TaskPoolMapOperator[ReadRange->MapBatches(<lambda>)] completed. Operator Metrics:
{'num_inputs_received': 20, 'bytes_inputs_received': 46440, 'num_task_inputs_processed': 20, 'bytes_task_inputs_processed': 46440, 'num_task_outputs_generated': 20, 'bytes_task_outputs_generated': 800, 'rows_task_outputs_generated': 100, 'num_outputs_taken': 20, 'bytes_outputs_taken': 800, 'num_outputs_of_finished_tasks': 20, 'bytes_outputs_of_finished_tasks': 800, 'num_tasks_submitted': 20, 'num_tasks_running': 0, 'num_tasks_have_outputs': 20, 'num_tasks_finished': 20, 'obj_store_mem_freed': 46440, 'obj_store_mem_spilled': 0, 'block_generation_time': 1.191296085, 'cpu_usage': 0, 'gpu_usage': 0, 'ray_remote_args': {'num_cpus': 1, 'scheduling_strategy': 'SPREAD'}}
此日志文件可在本地路径 /tmp/ray/{SESSION_NAME}/logs/ray-data/ray-data.log 找到。也可在 Ray 控制面板的头节点日志下的 日志视图 中找到。
Ray Data 统计数据#
要查看数据集执行的详细统计数据,您可以使用 stats() 方法。
操作符统计数据#
统计数据输出包含每个操作符的个体执行统计摘要。Ray Data 会跨许多不同的块计算此摘要,因此一些统计数据会显示所有块聚合的统计数据的最小值、最大值、平均值和总和。以下是操作符级别包含的各种统计数据的描述:
远程墙钟时间 (Remote wall time):墙钟时间是操作符的开始到结束时间。它包括操作符未处理数据、休眠、等待 I/O 等待的时间。
远程 CPU 时间 (Remote CPU time):CPU 时间是操作符的进程时间,不包括休眠时间。此时间包括用户和系统 CPU 时间。
UDF 时间 (UDF time):UDF 时间是花费在用户定义函数中的时间。此时间包括您传递给 Ray Data 方法(如
map()、map_batches()、filter()等)中的时间。您可以使用此统计数据跟踪在您定义的函数中花费的时间,以及优化这些函数可以节省多少时间。内存使用 (Memory usage):输出显示每个块的内存使用量(单位为 MiB)。
输出统计 (Output stats):输出包括每个块输出行数和输出大小(以字节为单位)的统计数据。每个任务的输出行数也包含在内。所有这些共同让您深入了解 Ray Data 在每个块和每个任务级别输出的数据量。
任务统计 (Task Stats):输出显示任务到节点的调度情况,这让您可以查看是否按预期充分利用了所有节点。
吞吐量 (Throughput):摘要计算操作符的吞吐量,并为了进行比较,它还计算同一任务在单个节点上的吞吐量估算值。此估算值假设工作的总时间保持不变,但没有并发。整体摘要还计算数据集级别的吞吐量,包括单个节点估算值。
迭代器统计数据#
如果您对数据进行迭代,Ray Data 也会生成迭代统计数据。即使您没有直接对数据进行迭代,您也可能会看到迭代统计数据,例如,如果您调用了 take_all()。Ray Data 在迭代器级别包含的一些统计数据有:
迭代器初始化 (Iterator initialization):Ray Data 初始化迭代器所花费的时间。此时间是 Ray Data 内部时间。
用户线程阻塞时间 (Time user thread is blocked):Ray Data 在迭代器中生成数据所花费的时间。如果您之前没有将数据集具体化,此时间通常是数据集的主要执行时间。
用户线程时间 (Time in user thread):在 Ray Data 代码之外,用于迭代数据集的用户线程中花费的时间。如果此时间很高,请考虑优化迭代数据集的循环体。
批次迭代统计 (Batch iteration stats):Ray Data 还包括关于批次预取的统计数据。这些时间是 Ray Data 内部代码的时间,但您可以通过调整预取过程来进一步优化此时间。
详细统计数据#
默认情况下,Ray Data 仅记录最重要的顶层统计数据。要启用详细统计数据输出,请在您的 Ray Data 代码中包含以下代码片段:
from ray.data import DataContext
context = DataContext.get_current()
context.verbose_stats_logs = True
启用详细模式后,Ray Data 会添加更多输出:
额外指标 (Extra metrics):操作符、执行器等可以将各种指标添加到此字典中。默认输出和此字典中的统计数据存在一些重复,但对于高级用户来说,此统计数据提供了对数据集执行的更深入了解。
运行时指标 (Runtime metrics):这些指标是对数据集执行运行时的顶层细分。这些统计数据是每个操作符完成所需时间的摘要,以及该操作符占总执行时间的比例。由于可能存在多个并发操作符,这些百分比不一定总和为 100%。相反,它们显示了在整个数据集执行过程中每个操作符的运行时间。
示例统计数据#
作为一个具体示例,下面是 使用 PyTorch ResNet18 进行图像分类批量推理 的统计数据输出:
Operator 1 ReadImage->Map(preprocess_image): 384 tasks executed, 386 blocks produced in 9.21s
* Remote wall time: 33.55ms min, 2.22s max, 1.03s mean, 395.65s total
* Remote cpu time: 34.93ms min, 3.36s max, 1.64s mean, 632.26s total
* UDF time: 535.1ms min, 2.16s max, 975.7ms mean, 376.62s total
* Peak heap memory usage (MiB): 556.32 min, 1126.95 max, 655 mean
* Output num rows per block: 4 min, 25 max, 24 mean, 9469 total
* Output size bytes per block: 6060399 min, 105223020 max, 31525416 mean, 12168810909 total
* Output rows per task: 24 min, 25 max, 24 mean, 384 tasks used
* Tasks per node: 32 min, 64 max, 48 mean; 8 nodes used
* Operator throughput:
* Ray Data throughput: 1028.5218637702708 rows/s
* Estimated single node throughput: 23.932674100499128 rows/s
Operator 2 MapBatches(ResnetModel): 14 tasks executed, 48 blocks produced in 27.43s
* Remote wall time: 523.93us min, 7.01s max, 1.82s mean, 87.18s total
* Remote cpu time: 523.23us min, 6.23s max, 1.76s mean, 84.61s total
* UDF time: 4.49s min, 17.81s max, 10.52s mean, 505.08s total
* Peak heap memory usage (MiB): 4025.42 min, 7920.44 max, 5803 mean
* Output num rows per block: 84 min, 334 max, 197 mean, 9469 total
* Output size bytes per block: 72317976 min, 215806447 max, 134739694 mean, 6467505318 total
* Output rows per task: 319 min, 720 max, 676 mean, 14 tasks used
* Tasks per node: 3 min, 4 max, 3 mean; 4 nodes used
* Operator throughput:
* Ray Data throughput: 345.1533728632648 rows/s
* Estimated single node throughput: 108.62003864820711 rows/s
Dataset iterator time breakdown:
* Total time overall: 38.53s
* Total time in Ray Data iterator initialization code: 16.86s
* Total time user thread is blocked by Ray Data iter_batches: 19.76s
* Total execution time for user thread: 1.9s
* Batch iteration time breakdown (summed across prefetch threads):
* In ray.get(): 70.49ms min, 2.16s max, 272.8ms avg, 13.09s total
* In batch creation: 3.6us min, 5.95us max, 4.26us avg, 204.41us total
* In batch formatting: 4.81us min, 7.88us max, 5.5us avg, 263.94us total
Dataset throughput:
* Ray Data throughput: 1026.5318925757008 rows/s
* Estimated single node throughput: 19.611578909587674 rows/s
对于启用详细模式的同一示例,统计数据输出为:
Operator 1 ReadImage->Map(preprocess_image): 384 tasks executed, 387 blocks produced in 9.49s
* Remote wall time: 22.81ms min, 2.5s max, 999.95ms mean, 386.98s total
* Remote cpu time: 24.06ms min, 3.36s max, 1.63s mean, 629.93s total
* UDF time: 552.79ms min, 2.41s max, 956.84ms mean, 370.3s total
* Peak heap memory usage (MiB): 550.95 min, 1186.28 max, 651 mean
* Output num rows per block: 4 min, 25 max, 24 mean, 9469 total
* Output size bytes per block: 4444092 min, 105223020 max, 31443955 mean, 12168810909 total
* Output rows per task: 24 min, 25 max, 24 mean, 384 tasks used
* Tasks per node: 39 min, 60 max, 48 mean; 8 nodes used
* Operator throughput:
* Ray Data throughput: 997.9207015895857 rows/s
* Estimated single node throughput: 24.46899945870273 rows/s
* Extra metrics: {'num_inputs_received': 384, 'bytes_inputs_received': 1104723940, 'num_task_inputs_processed': 384, 'bytes_task_inputs_processed': 1104723940, 'bytes_inputs_of_submitted_tasks': 1104723940, 'num_task_outputs_generated': 387, 'bytes_task_outputs_generated': 12168810909, 'rows_task_outputs_generated': 9469, 'num_outputs_taken': 387, 'bytes_outputs_taken': 12168810909, 'num_outputs_of_finished_tasks': 387, 'bytes_outputs_of_finished_tasks': 12168810909, 'num_tasks_submitted': 384, 'num_tasks_running': 0, 'num_tasks_have_outputs': 384, 'num_tasks_finished': 384, 'num_tasks_failed': 0, 'block_generation_time': 386.97945193799995, 'task_submission_backpressure_time': 7.263684450000142, 'obj_store_mem_internal_inqueue_blocks': 0, 'obj_store_mem_internal_inqueue': 0, 'obj_store_mem_internal_outqueue_blocks': 0, 'obj_store_mem_internal_outqueue': 0, 'obj_store_mem_pending_task_inputs': 0, 'obj_store_mem_freed': 1104723940, 'obj_store_mem_spilled': 0, 'obj_store_mem_used': 12582535566, 'cpu_usage': 0, 'gpu_usage': 0, 'ray_remote_args': {'num_cpus': 1, 'scheduling_strategy': 'SPREAD'}}
Operator 2 MapBatches(ResnetModel): 14 tasks executed, 48 blocks produced in 28.81s
* Remote wall time: 134.84us min, 7.23s max, 1.82s mean, 87.16s total
* Remote cpu time: 133.78us min, 6.28s max, 1.75s mean, 83.98s total
* UDF time: 4.56s min, 17.78s max, 10.28s mean, 493.48s total
* Peak heap memory usage (MiB): 3925.88 min, 7713.01 max, 5688 mean
* Output num rows per block: 125 min, 259 max, 197 mean, 9469 total
* Output size bytes per block: 75531617 min, 187889580 max, 134739694 mean, 6467505318 total
* Output rows per task: 325 min, 719 max, 676 mean, 14 tasks used
* Tasks per node: 3 min, 4 max, 3 mean; 4 nodes used
* Operator throughput:
* Ray Data throughput: 328.71474145609153 rows/s
* Estimated single node throughput: 108.6352856660782 rows/s
* Extra metrics: {'num_inputs_received': 387, 'bytes_inputs_received': 12168810909, 'num_task_inputs_processed': 0, 'bytes_task_inputs_processed': 0, 'bytes_inputs_of_submitted_tasks': 12168810909, 'num_task_outputs_generated': 1, 'bytes_task_outputs_generated': 135681874, 'rows_task_outputs_generated': 252, 'num_outputs_taken': 1, 'bytes_outputs_taken': 135681874, 'num_outputs_of_finished_tasks': 0, 'bytes_outputs_of_finished_tasks': 0, 'num_tasks_submitted': 14, 'num_tasks_running': 14, 'num_tasks_have_outputs': 1, 'num_tasks_finished': 0, 'num_tasks_failed': 0, 'block_generation_time': 7.229860895999991, 'task_submission_backpressure_time': 0, 'obj_store_mem_internal_inqueue_blocks': 13, 'obj_store_mem_internal_inqueue': 413724657, 'obj_store_mem_internal_outqueue_blocks': 0, 'obj_store_mem_internal_outqueue': 0, 'obj_store_mem_pending_task_inputs': 12168810909, 'obj_store_mem_freed': 0, 'obj_store_mem_spilled': 0, 'obj_store_mem_used': 1221136866.0, 'cpu_usage': 0, 'gpu_usage': 4}
Dataset iterator time breakdown:
* Total time overall: 42.29s
* Total time in Ray Data iterator initialization code: 20.24s
* Total time user thread is blocked by Ray Data iter_batches: 19.96s
* Total execution time for user thread: 2.08s
* Batch iteration time breakdown (summed across prefetch threads):
* In ray.get(): 73.0ms min, 2.15s max, 246.3ms avg, 11.82s total
* In batch creation: 3.62us min, 6.6us max, 4.39us avg, 210.7us total
* In batch formatting: 4.75us min, 8.67us max, 5.52us avg, 264.98us total
Dataset throughput:
* Ray Data throughput: 468.11051989434594 rows/s
* Estimated single node throughput: 972.8197093015862 rows/s
Runtime Metrics:
* ReadImage->Map(preprocess_image): 9.49s (46.909%)
* MapBatches(ResnetModel): 28.81s (142.406%)
* Scheduling: 6.16s (30.448%)
* Total: 20.23s (100.000%)