异步验证检查点#
在训练期间,您可能希望定期验证模型以监控训练进度。标准方法是在训练循环中定期在训练和验证之间切换。相反,Ray Train 允许您在单独的 Ray 任务中异步验证模型,这具有以下优点:
在不阻塞训练循环的情况下并行运行验证
在与训练不同的硬件上运行验证
利用 自动伸缩 仅为验证期间启动用户指定的机器
允许训练在保存具有部分指标(例如,损失)的检查点后立即继续,然后尽快接收验证指标(例如,准确率)。如果初始指标和验证指标共享相同的键,则验证指标将覆盖初始指标。
教程#
首先,定义一个 validate_fn,它接受一个要验证的 ray.train.Checkpoint 和一个可选的 validate_config 字典。此字典可以包含验证所需的参数,例如验证数据集。您的函数应返回该验证的指标字典。以下是一个简单的示例,仅用于教学目的。由于验证任务始终在 CPU 上运行,因此它是不切实际的;有关更现实的示例,请参阅 编写分布式验证函数。
import os
import torch
import ray.train
def validate_fn(checkpoint: ray.train.Checkpoint, config: dict) -> dict:
# Load the checkpoint
model = ...
with checkpoint.as_directory() as checkpoint_dir:
model_state_dict = torch.load(os.path.join(checkpoint_dir, "model.pt"))
model.load_state_dict(model_state_dict)
model.eval()
# Perform validation on the data
total_accuracy = 0
dataset = config["dataset"]
with torch.no_grad():
for batch in dataset.iter_torch_batches(batch_size=128):
images, labels = batch["image"], batch["label"]
outputs = model(images)
total_accuracy += (outputs.argmax(1) == labels).sum().item()
return {"score": total_accuracy / len(dataset)}
警告
请勿将大型对象传递给 validate_fn,因为 Ray Train 会将其作为 Ray 任务运行并序列化所有捕获的变量。相反,请将大型对象打包在 Checkpoint 中,并按照 保存和加载检查点 中的说明从共享存储中访问它们。
接下来,在您的训练循环中,像下面这样从 rank 0 工作节点调用 ray.train.report(),并将 validate_fn 和 validate_config 作为参数传入。
import tempfile
import ray.data
def train_func(config: dict) -> None:
...
epochs = ...
model = ...
rank = ray.train.get_context().get_world_rank()
for epoch in epochs:
... # training step
if rank == 0:
training_metrics = {"loss": ..., "epoch": epoch}
local_checkpoint_dir = tempfile.mkdtemp()
torch.save(
model.module.state_dict(),
os.path.join(local_checkpoint_dir, "model.pt"),
)
ray.train.report(
training_metrics,
checkpoint=ray.train.Checkpoint.from_directory(local_checkpoint_dir),
checkpoint_upload_mode=ray.train.CheckpointUploadMode.ASYNC,
validate_fn=validate_fn,
validate_config={
"dataset": config["validation_dataset"],
"train_run_name": ray.train.get_context().get_experiment_name(),
"epoch": epoch,
},
)
else:
ray.train.report({}, None)
def run_trainer() -> ray.train.Result:
train_dataset = ray.data.read_parquet(...)
validation_dataset = ray.data.read_parquet(...)
trainer = ray.train.torch.TorchTrainer(
train_func,
# Pass training dataset in datasets arg to split it across training workers
datasets={"train": train_dataset},
# Pass validation dataset in train_loop_config so validate_fn can choose how to use it later
train_loop_config={"validation_dataset": validation_dataset},
scaling_config=ray.train.ScalingConfig(
num_workers=2,
use_gpu=True,
# Use powerful GPUs for training
accelerator_type="A100",
),
)
return trainer.fit()
最后,训练完成后,您可以使用 ray.train.Result 对象来访问您的检查点及其相关指标。有关更多详细信息,请参阅 检查训练结果。
编写分布式验证函数#
上面的 validate_fn 在单个 Ray 任务中运行,但您可以通过启动更多 Ray 任务或 Actor 来提高其性能。Ray 团队建议通过以下方法之一来实现:
创建一个仅执行验证而不执行训练的
ray.train.torch.TorchTrainer。使用
ray.data.Dataset.map_batches()在验证集上计算指标。
选择一种方法#
如果您这样做,则应使用 TorchTrainer:
您希望保留现有的验证逻辑,并避免迁移到 Ray Data。训练函数 API 允许您完全自定义验证循环,以匹配您当前的设置。
您的验证代码依赖于在 Torch 进程组内运行 — 例如,您的指标聚合逻辑使用集体通信调用,或者您的模型并行设置在前向传播期间需要跨 GPU 通信。
如果您这样做,则应使用 map_batches:
您关心验证性能。初步基准测试表明
map_batches的速度更快。您更喜欢 Ray Data 的原生指标聚合 API 而不是 PyTorch,在 PyTorch 中,您必须手动使用低级集体操作来实现聚合,或依赖于 torchmetrics 等第三方库。
示例:使用 Ray Train TorchTrainer 进行验证#
这是一个 validate_fn,它使用 TorchTrainer 在验证集上计算平均交叉熵损失。请注意此示例的以下几点:
它
report了一个虚拟检查点,以便TorchTrainer保留指标。虽然您通常使用
TorchTrainer进行训练,但您可以像本示例一样仅将其用于验证。由于训练通常比推理具有更高的 GPU 内存要求,因此您可以为训练和验证设置不同的资源要求,例如,训练使用 A100,验证使用 A10G。
import torchmetrics
from torch.nn import CrossEntropyLoss
import ray.train.torch
def eval_only_train_fn(config_dict: dict) -> None:
# Load the checkpoint
model = ...
with config_dict["checkpoint"].as_directory() as checkpoint_dir:
model_state_dict = torch.load(os.path.join(checkpoint_dir, "model.pt"))
model.load_state_dict(model_state_dict)
model.cuda().eval()
# Set up metrics and data loaders
criterion = CrossEntropyLoss()
mean_valid_loss = torchmetrics.MeanMetric().cuda()
test_data_shard = ray.train.get_dataset_shard("validation")
test_dataloader = test_data_shard.iter_torch_batches(batch_size=128)
# Compute and report metric
with torch.no_grad():
for batch in test_dataloader:
images, labels = batch["image"], batch["label"]
outputs = model(images)
loss = criterion(outputs, labels)
mean_valid_loss(loss)
ray.train.report(
metrics={"score": mean_valid_loss.compute().item()},
checkpoint=ray.train.Checkpoint(
ray.train.get_context()
.get_storage()
.build_checkpoint_path_from_name("placeholder")
),
checkpoint_upload_mode=ray.train.CheckpointUploadMode.NO_UPLOAD,
)
def validate_fn(checkpoint: ray.train.Checkpoint, config: dict) -> dict:
trainer = ray.train.torch.TorchTrainer(
eval_only_train_fn,
train_loop_config={"checkpoint": checkpoint},
scaling_config=ray.train.ScalingConfig(
num_workers=2, use_gpu=True, accelerator_type="A10G"
),
# Name validation run to easily associate it with training run
run_config=ray.train.RunConfig(
name=f"{config['train_run_name']}_validation_epoch_{config['epoch']}"
),
# User weaker GPUs for validation
datasets={"validation": config["dataset"]},
)
result = trainer.fit()
return result.metrics
示例:使用 Ray Data map_batches 进行验证#
下面是一个 validate_fn,它使用 ray.data.Dataset.map_batches() 在验证集上计算平均准确率。有关如何使用 map_batches 进行批推理的更多信息,请参阅 端到端:离线批推理。
class Predictor:
def __init__(self, checkpoint: ray.train.Checkpoint):
self.model = ...
with checkpoint.as_directory() as checkpoint_dir:
model_state_dict = torch.load(os.path.join(checkpoint_dir, "model.pt"))
self.model.load_state_dict(model_state_dict)
self.model.cuda().eval()
def __call__(self, batch: dict) -> dict:
image = torch.as_tensor(batch["image"], dtype=torch.float32, device="cuda")
label = torch.as_tensor(batch["label"], dtype=torch.float32, device="cuda")
pred = self.model(image)
return {"res": (pred.argmax(1) == label).cpu().numpy()}
def validate_fn(checkpoint: ray.train.Checkpoint, config: dict) -> dict:
# Set name to avoid confusion; default name is "Dataset"
config["dataset"].set_name("validation")
eval_res = config["dataset"].map_batches(
Predictor,
batch_size=128,
num_gpus=1,
fn_constructor_kwargs={"checkpoint": checkpoint},
concurrency=2,
)
mean = eval_res.mean(["res"])
return {
"score": mean,
}
检查点指标的生命周期#
在训练循环期间,您的检查点和指标会发生以下情况:
您会报告一个带有初始指标(例如,训练损失)、
validate_fn和validate_config的检查点。Ray Train 会在新的 Ray 任务中异步运行您的
validate_fn,并传入该检查点和validate_config。当该验证任务完成时,Ray Train 会将您的
validate_fn返回的指标与该检查点相关联。训练完成后,您可以使用
ray.train.Result对象来访问您的检查点及其相关指标。有关更多详细信息,请参阅 检查训练结果。
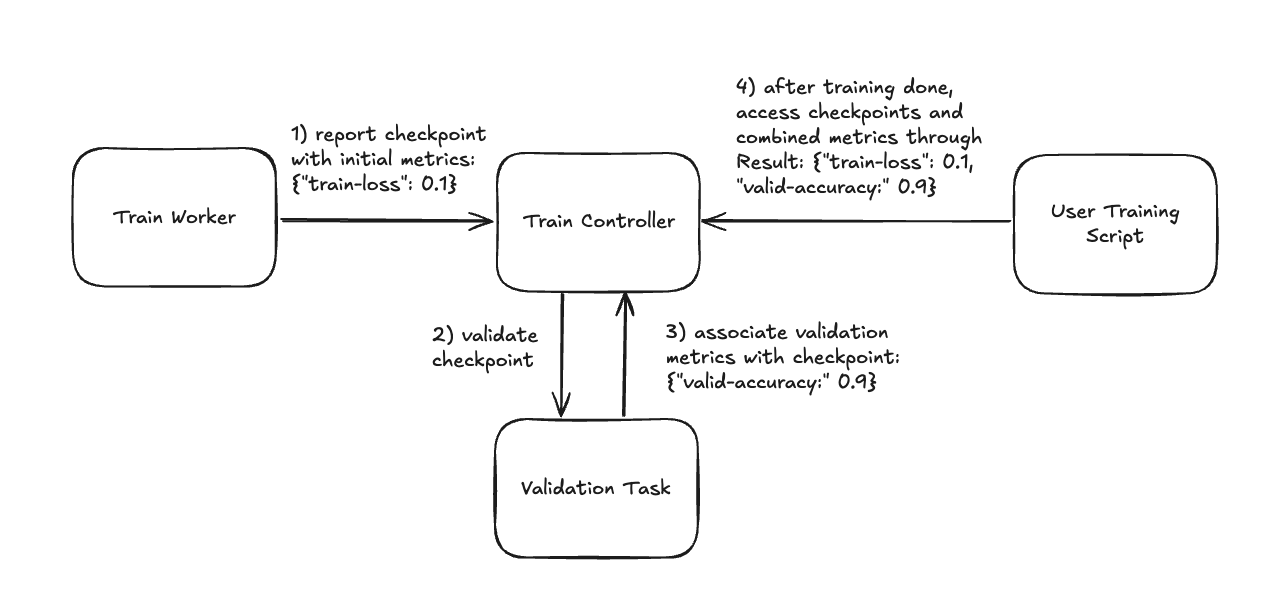
Ray Train 在训练期间如何填充检查点指标以及您在训练后如何访问它们。#