请求路由#
Ray Serve LLM 提供可定制的请求路由,以针对不同的工作负载模式优化副本之间的请求分发。请求路由在副本选择级别上运行,这与入口级别的模型路由不同。
路由与入口#
您需要区分两个路由级别
入口路由(模型级别)
将
model_id映射到部署示例:
OpenAiIngress接收到model="gptoss"的/v1/chat/completions请求,并将其映射到gptoss部署。
请求路由(副本级别)
选择将请求发送到哪个副本
示例:
OpenAiIngress副本内的gptoss部署句柄决定将请求发送到该部署的哪个副本(1、2 或 3)。
本文档重点介绍请求路由(副本选择)。
HTTP Request → Ingress (model routing) → Request Router (replica selection) → Server Replica
请求路由架构#
Ray Serve LLM 请求路由在部署句柄级别运行
┌──────────────┐
│ Ingress │
│ (Replica 1) │
└──────┬───────┘
│
│ handle.remote(request)
↓
┌──────────────────┐
│ Deployment Handle│
│ + Router │ ← Request routing happens here
└──────┬───────────┘
│
│ Chooses replica based on policy
↓
┌───┴────┬────────┬────────┐
│ │ │ │
┌──▼──┐ ┌──▼──┐ ┌──▼──┐ ┌──▼──┐
│ LLM │ │ LLM │ │ LLM │ │ LLM │
│ 1 │ │ 2 │ │ 3 │ │ 4 │
└─────┘ └─────┘ └─────┘ └─────┘
可用的路由策略#
Ray Serve LLM 提供多种请求路由策略,以优化不同工作负载模式
默认路由:二选一算法#
默认路由器使用二选一算法来
随机采样两个副本。
路由到正在处理的请求较少的副本。
这在最小的协调开销下提供了良好的负载均衡。
感知前缀的路由#
PrefixCacheAffinityRouter 通过将具有相似前缀的请求路由到同一副本,从而优化具有共享前缀的工作负载。这提高了 vLLM 的自动前缀缓存 (APC) 中的 KV 缓存命中率。
路由策略
检查负载均衡:如果副本平衡(队列差异 < 阈值),则使用前缀匹配。
高匹配率 (≥10%):路由到前缀匹配度最高的副本。
低匹配率 (<10%):路由到缓存利用率最低的副本。
回退:当负载不平衡时,使用二选一算法。
有关更多详细信息,请参阅 感知前缀的路由。
自定义路由策略的设计模式#
自定义请求路由器是 Ray Serve 原生 API 中的一项功能,您可以按部署进行定义。对于每个部署,您可以自定义每次从调用方调用部署句柄上的 .remote() 时执行的路由逻辑。由于部署句柄是集群中全局可用的对象,因此您可以从 Ray 集群中的任何 actor 或任务调用它们。有关此 API 的更多详细信息,请参阅 使用自定义算法进行请求路由。
这允许您运行相同的路由逻辑,即使您有多个句柄。Ray Serve 中的默认请求路由器是二选一算法,它平衡了负载均衡并优先考虑局部性路由。但是,您可以自定义此设置以使用特定于 LLM 的指标。
Ray Serve LLM 在框架中包含感知前缀的路由。自定义请求路由器的两种常见架构模式。它们之间存在明显的权衡,因此请选择合适的模式并平衡简洁性与性能。
模式 1:集中式单例指标存储#
在此方法中,您维护一个集中式指标存储(例如,一个单例 actor)来跟踪与路由相关的信息。请求路由器逻辑实际运行在拥有部署句柄的进程上,因此可以有许多这样的进程。每个进程都可以查询单例 actor,创建一个多租户 actor,为请求路由器提供集群状态的一致视图。
单个 actor 可以提供原子线程安全的操作,例如用于查询全局状态的 get() 和用于更新全局状态的 set(),路由器可以在 choose_replicas() 和 on_request_routed() 期间使用它们。
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Ingress │────►│ Metric │◄────│ Ingress │
│ 1 │ │ Store │ │ 2 │
└────┬────┘ └─────────┘ └────┬────┘
│ │
└────────────────┬──────────────┘
│
┌──────────┴──────────┐
│ │
┌────▼────┐ ┌────▼────┐
│ LLM │ │ LLM │
│ Server │ │ Server │
└─────────┘ └─────────┘
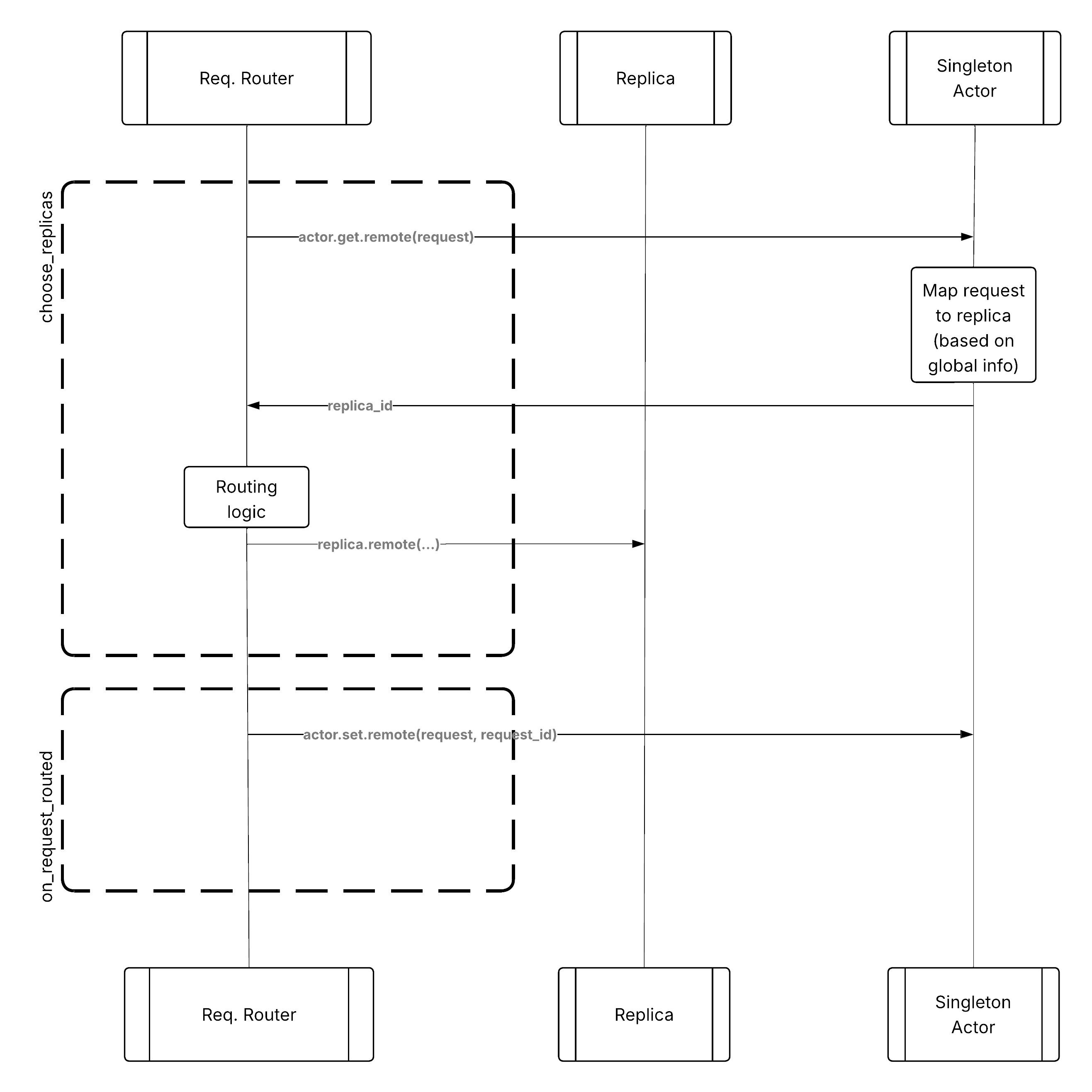
自定义路由的集中式指标存储模式#
优点
实现简单 - 无需修改部署逻辑即可记录副本统计信息。
请求指标立即可用。
强大的一致性保证。
缺点
在吞吐量很高的应用程序中,单个 actor 可能会成为瓶颈,此时 TTFT 会受到 RPC 调用(~1000 次请求/秒)的影响。
每次路由决策都需要额外的网络跳数。
模式 2:从 Serve 控制器广播的指标#
在此方法中,Serve 控制器轮询每个副本以获取本地统计信息,然后将它们广播到其部署句柄上的所有请求路由器。然后,请求路由器可以使用此全局广播的信息来选择正确的副本。请求到达副本后,副本会更新其本地统计信息,以便在控制器下次轮询时将其发送回 Serve 控制器。
┌──────────────┐
│ Serve │
│ Controller │
└──────┬───────┘
│ (broadcast)
┌─────────┴─────────┐
│ │
┌────▼────┐ ┌────▼────┐
│ Ingress │ │ Ingress │
│ +Cache │ │ +Cache │
└────┬────┘ └────┬────┘
│ │
└────────┬──────────┘
│
┌──────┴──────┐
│ │
┌────▼────┐ ┌────▼────┐
│ LLM │ │ LLM │
│ Server │ │ Server │
└─────────┘ └─────────┘
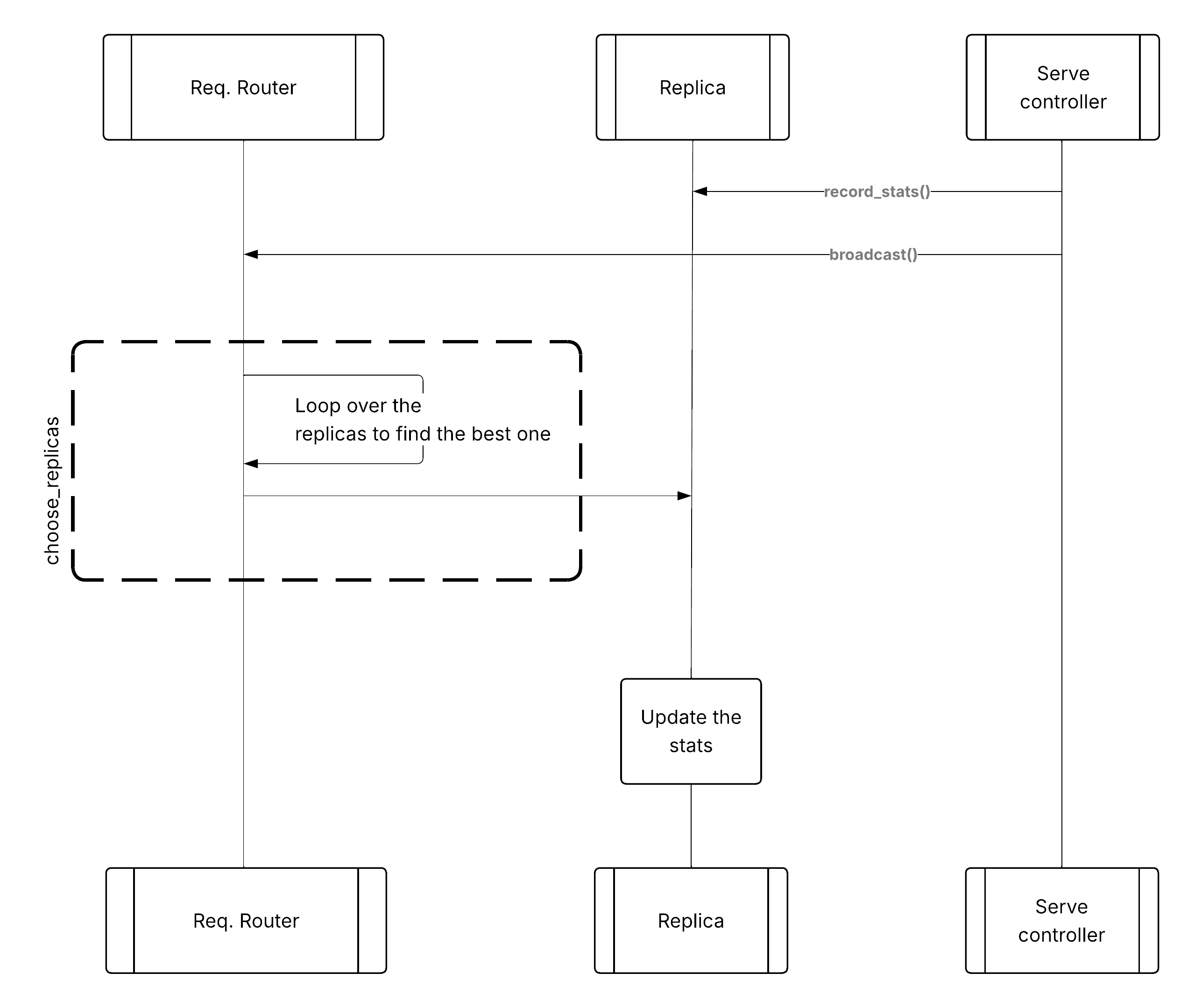
自定义路由的指标广播模式#
优点
可扩展到更高的吞吐量。
每次路由决策无需额外的 RPC 开销。
分布式路由决策。
缺点
请求路由器对统计信息的视图与副本的实际状态之间存在时间延迟。
最终一致性 - 路由器可能会根据略微过时的数据做出决策。
需要与 Serve 控制器协调,实现更复杂。
使用模式 1(集中式存储):当您需要强一致性、中等吞吐量要求或希望简化实现时。
使用模式 2(广播指标):当您需要极高的吞吐量、可以容忍最终一致性或希望最小化每次请求开销时。
自定义路由策略#
您可以通过扩展 Ray Serve 的 RequestRouter 基类来实施自定义路由策略。有关实施自定义路由器的详细示例和分步指南,请参阅 使用自定义算法进行请求路由。
要实现的键方法
choose_replicas():选择哪些副本应处理请求。on_request_routed():成功路由请求后更新路由器状态。on_replica_actor_died():副本死亡时清理状态。
实用工具混合类#
Ray Serve 提供混合类,为路由器添加通用功能。有关示例,请参阅 使用自定义算法进行请求路由。
LocalityMixin:优先选择同一节点上的副本以减少网络延迟。MultiplexMixin:跟踪每个副本上加载了哪些模型,用于 LoRA 部署。FIFOMixin:确保请求的 FIFO 顺序。
路由器生命周期#
请求路由器的典型生命周期包括以下阶段
初始化:使用副本列表创建路由器。
请求路由:为每个请求调用
choose_replicas()。回调:成功路由后调用
on_request_routed()。副本故障:副本死亡时调用
on_replica_actor_died()。清理:部署删除时清理路由器。
异步操作#
为了获得最佳性能,路由器应使用异步操作。以下示例演示了推荐的模式
# Recommended pattern: Async operation
async def choose_replicas(self, ...):
state = await self.state_actor.get.remote()
return self._select(state)
# Not recommended pattern: Blocking operation
async def choose_replicas(self, ...):
state = ray.get(self.state_actor.get.remote()) # Blocks!
return self._select(state)
状态管理#
对于具有状态的路由器,请使用适当的同步。以下示例显示了推荐的模式
class StatefulRouter(RequestRouter):
def __init__(self):
self.lock = asyncio.Lock() # For async code
self.state = {}
async def choose_replicas(self, ...):
async with self.lock: # Protect shared state
# Update state
self.state[...] = ...
return [...]
另请参阅#
感知前缀的路由 - 部署感知前缀路由的用户指南
使用自定义算法进行请求路由 - Ray Serve 实施自定义路由器的指南
RequestRouterAPI 参考 - 完整的 API 文档