Prefill-decode 分离#
Prefill-decode (PD) 分离是一种服务模式,它将预填充阶段(处理输入提示)与解码阶段(生成 token)分开。这种模式最初在 DistServe 中得到推广,通过根据每个阶段的具体需求独立扩展来优化资源利用率。
架构概述#
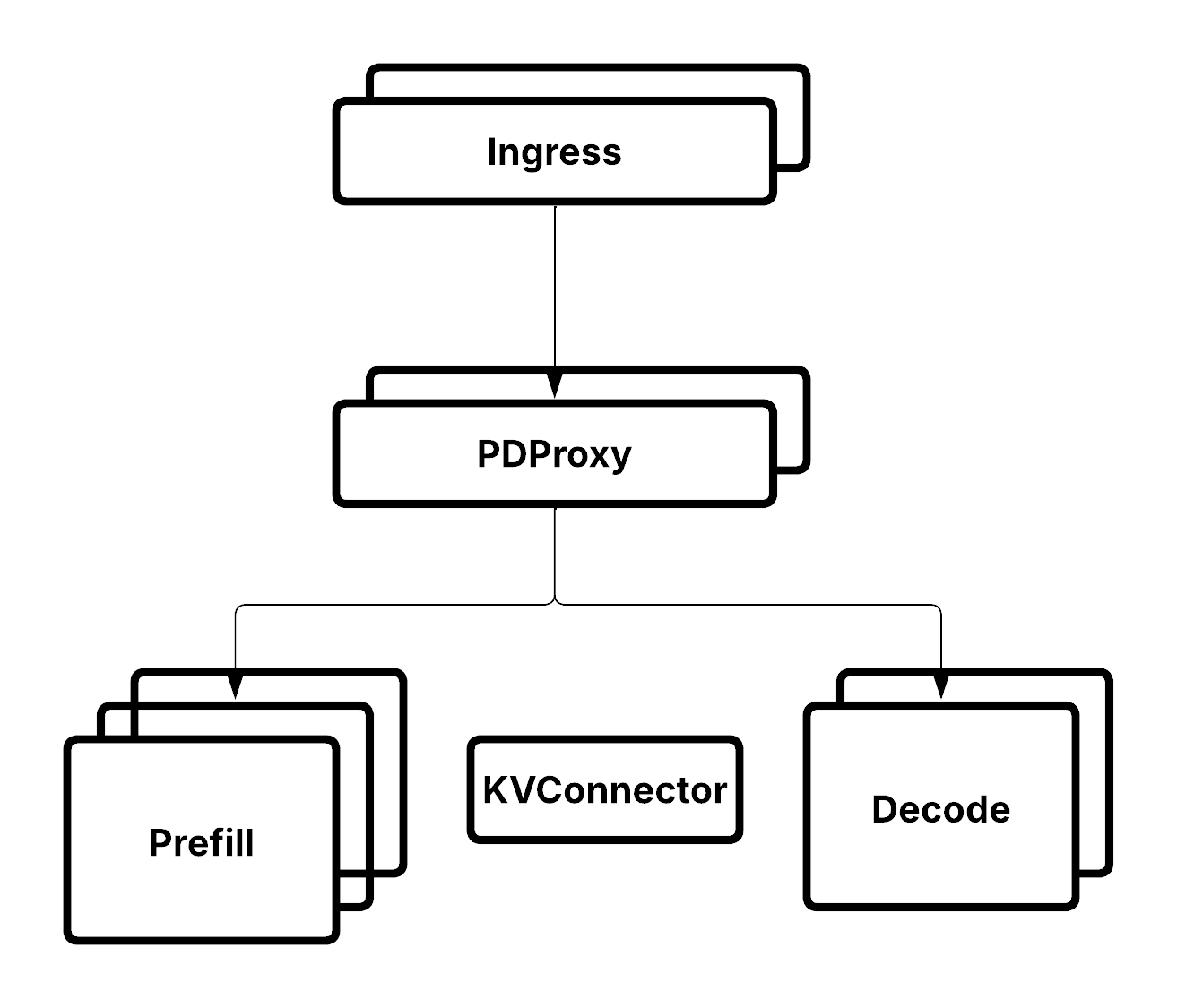
Prefill-decode 分离架构,其中 PDProxyServer 协调预填充和解码的部署。#
在 Prefill-decode 分离中
预填充部署:处理输入提示并生成初始 KV 缓存。
解码部署:使用传输的 KV 缓存来生成输出 token。
独立扩展:每个阶段根据自身负载进行扩展。
资源优化:为不同阶段配置不同的引擎。
为什么要分离?#
资源特性#
预填充和解码具有不同的计算模式
阶段 |
特性 |
资源需求 |
|---|---|---|
预填充 |
一次性处理整个提示 |
高计算量,低内存 |
并行 token 处理 |
受益于高 FLOPS |
|
每个请求持续时间短 |
当受解码限制时可以使用较少的副本 |
|
解码 |
一次生成一个 token |
低计算量,高内存 |
自回归生成 |
受益于大批量 |
|
持续时间长(许多 token) |
需要更多副本 |
扩展带来的好处#
分离使得
成本优化:预填充和解码实例的正确比例可提高每节点的整体吞吐量。
动态流量调整:根据工作负载(预填充密集型或解码密集型)和流量 volume 独立扩展预填充和解码。
效率:预填充在解码生成时服务多个请求,允许一个预填充实例服务多个解码实例。
组件#
PDProxyServer#
PDProxyServer 协调分离式服务
class PDProxyServer:
"""Proxy server for prefill-decode disaggregation."""
def __init__(
self,
prefill_handle: DeploymentHandle,
decode_handle: DeploymentHandle,
):
self.prefill_handle = prefill_handle
self.decode_handle = decode_handle
async def chat(
self,
request: ChatCompletionRequest,
) -> AsyncGenerator[str, None]:
"""Handle chat completion with PD flow.
Flow:
1. Send request to prefill deployment
2. Prefill processes prompt, transfers KV to decode
3. Decode generates tokens, streams to client
"""
# Prefill phase
prefill_result = await self.prefill_handle.chat.remote(request)
# Extract KV cache metadata
kv_metadata = prefill_result["kv_metadata"]
# Decode phase with KV reference
async for chunk in self.decode_handle.chat.remote(
request,
kv_metadata=kv_metadata
):
yield chunk
主要职责
在预填充和解码之间路由请求。
处理 KV 缓存元数据传输。
将响应流式传输回客户端。
为每个请求管理任一阶段的错误。
Prefill LLMServer#
配置为预填充的标准 LLMServer
prefill_config = LLMConfig(
model_loading_config=dict(
model_id="llama-3.1-8b",
model_source="meta-llama/Llama-3.1-8B-Instruct"
),
engine_kwargs=dict(
# Prefill-specific configuration
kv_transfer_config={
"kv_connector": "NixlConnector",
"kv_role": "kv_both",
},
),
)
Decode LLMServer#
配置为解码的标准 LLMServer
decode_config = LLMConfig(
model_loading_config=dict(
model_id="llama-3.1-8b",
model_source="meta-llama/Llama-3.1-8B-Instruct"
),
engine_kwargs=dict(
# Decode-specific configuration
kv_transfer_config={
"kv_connector": "NixlConnector",
"kv_role": "kv_both",
},
),
)
请求流#

Prefill-decode 请求流,显示了阶段之间的 KV 缓存传输。#
详细的请求流程
客户端请求:HTTP POST 到
/v1/chat/completions。入口:路由到
PDProxyServer。代理 → 预填充:
PDProxyServer调用预填充部署。预填充服务器处理提示。
生成 KV 缓存。
将 KV 传输到存储后端。
返回 KV 元数据(位置、大小等)。
代理 → 解码:
PDProxyServer使用 KV 元数据调用解码部署。解码服务器从存储加载 KV 缓存。
开始 token 生成。
通过代理流式传输 token 回来。
响应流式传输:客户端接收生成的 token。
注意
KV 缓存传输对客户端是透明的。从客户端的角度来看,这是一个标准的 OpenAI API 调用。
性能特性#
何时使用 PD 分离#
Prefill-decode 分离在以下情况效果最好:
长生成:解码阶段占主导地位,决定了端到端延迟。
阶段不平衡:预填充和解码需要不同的资源。
成本优化:为每个阶段使用不同类型的 GPU。
高解码负载:许多请求同时处于解码阶段。
批处理效率:预填充可以高效地批处理多个请求。
何时不使用 PD#
在以下情况下考虑替代方案:
短输出:解码延迟很小,开销不值得。
网络限制:KV 传输开销过高。
小型模型:两个阶段都能轻松适应相同的资源。
设计注意事项#
KV 缓存传输延迟#
预填充和解码之间 KV 缓存传输的延迟会影响整体请求延迟,并且主要由网络带宽决定。NIXL 有不同的后端插件,但其在不同网络堆栈上的性能尚不成熟。您应该检查您的部署以验证 NIXL 是否为您的环境使用了正确的网络后端。
阶段负载均衡#
系统必须平衡预填充和解码阶段之间的负载。不匹配的扩展可能导致:
预填充瓶颈:请求在预填充处排队,解码副本空闲。
解码瓶颈:预填充快速完成,解码跟不上。
监控两个阶段,并相应地调整副本数量和自动缩放策略。
另请参阅#
架构概述 - 高层架构概述
核心组件 - 核心组件和协议
数据并行注意力 - 数据并行注意力架构
Prefill/decode 分离 - 实际部署指南