使用 Ray Serve 将 MCP STDIO 服务器部署为可伸缩的 HTTP 服务#
正如教程所示,使用 Ray Serve 将现有的 MCP 部署为 HTTP 服务,可以使您的服务更可靠、更易于扩展。这种方法有以下优点:
解决 MCP stdio 模式的局限性#
使用标准输入/输出流的 MCP stdio 模式通常在本地运行,用于命令行工具或简单集成。这使得它难以作为服务进行部署,因为它依赖于本地进程通信,而这种通信不适用于分布式或云环境。
“货架”上的许多官方 Docker 镜像默认使用 stdio 模式,这使得它们与远程服务器和大规模部署不兼容。通过使用 Ray Serve,您可以将任何基于 stdio 的 MCP 服务器公开为 HTTP 服务,而无需修改或重新构建现有的 Docker 镜像。这种方法带来了几个关键好处:
无需代码更改或镜像重新构建:您不必重写 MCP 服务器或重新构建其 Docker 镜像 — Ray Serve 会封装现有容器并为您处理传输层。
自动工具发现:通过对 /tools 端点的简单 HTTP GET 请求检索可用工具的列表 — 无需自定义脚本。
标准化的 HTTP API:通过 POST 到 /call 端点调用任何工具,并在 JSON 中传递工具名称和参数。
云原生可伸缩性:在负载均衡器后面部署,水平自动扩展,并像其他任何 HTTP 微服务一样与服务网格或 API 网关集成。
通过使用 Ray Serve 将 stdio 模式的 MCP 服务器转换为 HTTP 端点,您可以在不触及现有代码库的情况下,获得生产级部署所需的灵活性和可靠性。以下架构图说明了使用 Ray Serve 部署 MCP Docker 镜像:
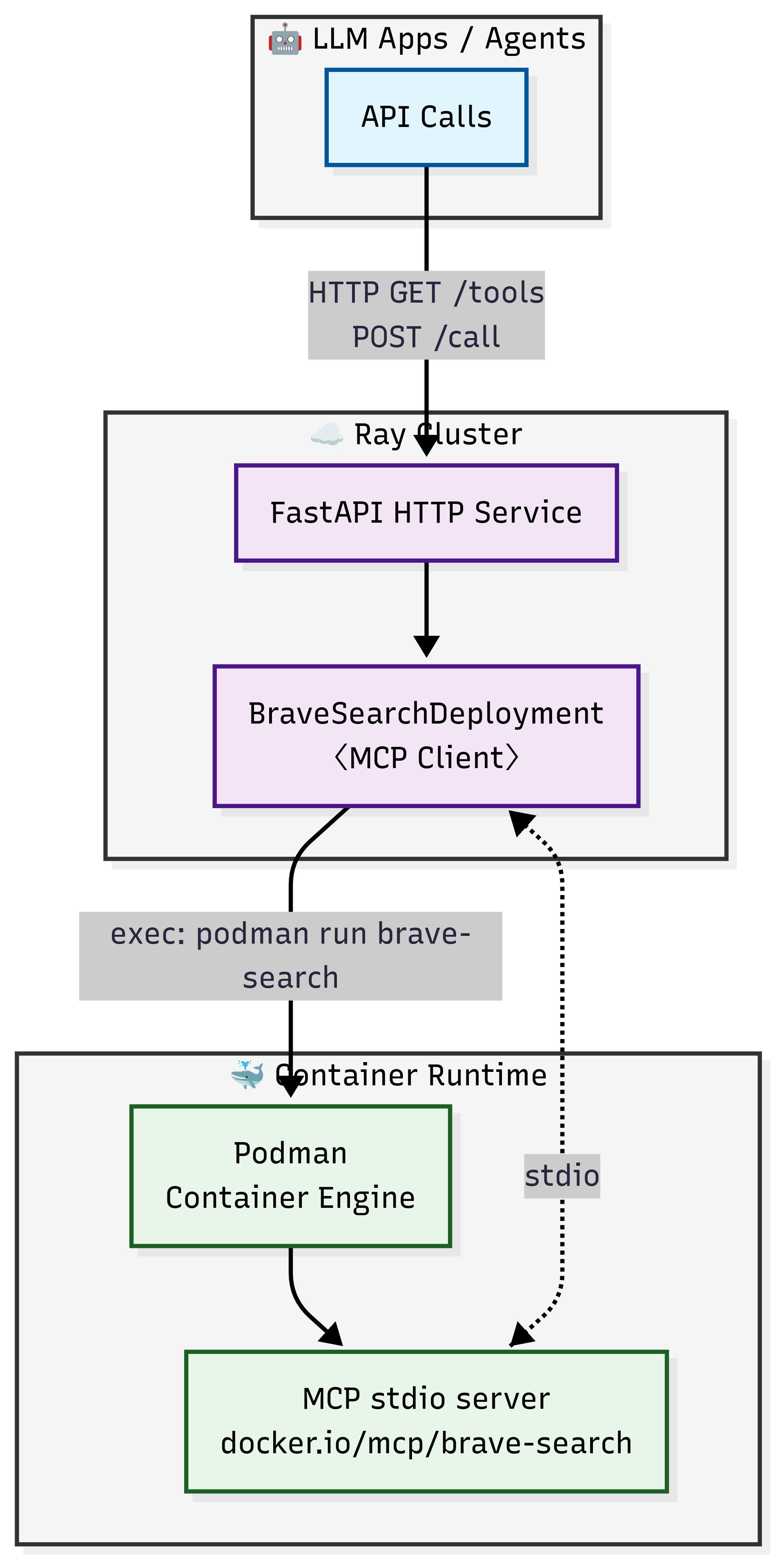
Ray Serve 在 Anyscale 上部署的好处#
正如教程所示,使用 Ray Serve 将 MCP 转换为 HTTP 服务,解决了 stdio 模式的部署挑战。它使得服务更容易管理和部署,尤其是在生产环境中,并提供其他附加功能:
Ray Serve 功能
自动伸缩:Ray Serve 会根据流量需求自动调整副本数量,确保您的服务能够处理增加的负载,同时在高峰使用时段保持响应能力。
负载均衡:Ray Serve 会智能地将传入的请求分发到可用副本,防止任何单个实例过载,并保持一致的性能。
可观察性:内置的监控功能可提供对服务性能的可视性,包括请求指标、资源利用率和系统健康状况指示器。
容错性:Ray Serve 会通过重新启动失败的组件并将请求重新分发给健康的副本,自动检测并从故障中恢复,确保服务的连续可用性。
Anyscale 服务附加好处
生产就绪:Anyscale 提供企业级基础设施管理和自动化部署,使您的 MCP 服务为真实世界的生产流量做好准备。
高可用性:先进的可用区感知调度机制和零停机滚动更新,以确保您的服务保持高可用性。
主节点容错:通过托管的主节点冗余提供额外的弹性,防止 Ray 集群协调层出现单点故障。
组合:通过将多个部署编排成单个管道来构建复杂服务,使您能够无缝地链接预处理、模型推理、后处理和自定义逻辑。
注意:
如果您想使用现成的 MCP Docker 镜像来部署可伸缩的 MCP 服务,本教程仍然适用。但是,在这种方法下,您需要在代理中编写一些自定义代码来正确列出和调用工具。
对于使用您自己的自定义 MCP 工具与 Ray Serve 进行更深入的集成,您也可以在流式 HTTP 模式下将 MCP 与 Ray Serve 结合使用。有关该方法的更多信息,请参阅 Notebook #1 和 #2。这允许您直接将 Claude 与远程 MCP 服务器集成。
先决条件#
Ray [Serve],已包含在基础 Docker 镜像中
Podman
在您的环境中设置了一个 Brave API 密钥(
BRAVE_API_KEY)MCP Python 库。
依赖项#
构建用于 Ray Serve 部署的 Docker 镜像
在本教程中,您需要使用此代码库中包含的 Dockerfile,为在 Anyscale 上进行部署构建 Docker 镜像。
原因是,当您从工作区终端运行 apt-get install -y podman(例如,安装系统软件包)时,它只存在于 Ray 主节点中,不会传播到您的 Ray 工作节点。
构建 Docker 镜像后,在工作区中的“依赖项”选项卡中导航并选择您刚刚创建的相应镜像,然后设置 BRAVE_API_KEY 环境变量。
注意:此 Docker 镜像仅用于部署带 Ray Serve 的 MCP。请确保您的 MCP docker 镜像(例如 docker.io/mcp/brave-search)已发布到您自己的私有注册表或公共注册表。
常见问题#
FileNotFoundError: [Errno 2] No such file or directory
通常表示 Podman 未正确安装。请验证 Podman 的安装。
KeyError: ‘BRAVE_API_KEY’
确保您已在环境中导出了 BRAVE_API_KEY 或将其包含在依赖项配置中。
1. 创建部署文件#
将以下代码保存为 brave_mcp_ray_serve.py。此脚本定义了一个 Ray Serve 部署,该部署使用 Podman 将请求代理到 MCP Brave Search 服务器。
import os
import asyncio
import logging
from contextlib import AsyncExitStack
from typing import Any, Dict, List
from fastapi import FastAPI, Request, HTTPException
from ray import serve
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
app = FastAPI()
logger = logging.getLogger("MCPDeployment")
@serve.deployment(num_replicas=3, ray_actor_options={"num_cpus": 0.5})
@serve.ingress(app)
class BraveSearchDeployment:
"""MCP deployment that exposes every tool provided by its server.
* **GET /tools** - list tools (name, description, and input schema)
* **POST /call** - invoke a tool
```json
{
"tool_name": "<name>", // optional - defaults to brave_web_search
"tool_args": { ... } // **required** - arguments for the tool
}
```
"""
DEFAULT_TOOL = "brave_web_search"
def __init__(self) -> None:
self._init_task = asyncio.create_task(self._initialize())
# ------------------------------------------------------------------ #
# 1. Start podman + MCP session
# ------------------------------------------------------------------ #
async def _initialize(self) -> None:
params = StdioServerParameters(
command="podman",
args=[
"run",
"-i",
"--rm",
"-e",
f"BRAVE_API_KEY={os.environ['BRAVE_API_KEY']}",
"docker.io/mcp/brave-search",
],
env=os.environ.copy(),
)
self._exit_stack = AsyncExitStack()
stdin, stdout = await self._exit_stack.enter_async_context(stdio_client(params))
self.session: ClientSession = await self._exit_stack.enter_async_context(ClientSession(stdin, stdout))
await self.session.initialize()
logger.info("BraveSearchDeployment replica ready.")
async def _ensure_ready(self) -> None:
"""Block until _initialize finishes (and surface its errors)."""
await self._init_task
# ------------------------------------------------------------------ #
# 2. Internal helper: list tools
# ------------------------------------------------------------------ #
async def _list_tools(self) -> List[Dict[str, Any]]:
await self._ensure_ready()
resp = await self.session.list_tools()
return [
{
"name": tool.name,
"description": tool.description,
"input_schema": tool.inputSchema,
}
for tool in resp.tools
]
# ------------------------------------------------------------------ #
# 3. HTTP endpoints
# ------------------------------------------------------------------ #
@app.get("/tools")
async def tools(self):
"""Return all tools exposed by the backing MCP server."""
return {"tools": await self._list_tools()}
@app.post("/call")
async def call_tool(self, request: Request):
"""Generic endpoint to invoke any tool exposed by the server."""
body = await request.json()
tool_name: str = body.get("tool_name", self.DEFAULT_TOOL)
tool_args: Dict[str, Any] | None = body.get("tool_args")
if tool_args is None:
raise HTTPException(400, "must include 'tool_args'")
await self._ensure_ready()
try:
result = await self.session.call_tool(tool_name, tool_args)
return {"result": result}
except Exception as exc:
logger.exception("MCP tool call failed")
raise HTTPException(500, "Tool execution error") from exc
# ------------------------------------------------------------------ #
# 4. Tidy shutdown
# ------------------------------------------------------------------ #
async def __del__(self):
if hasattr(self, "_exit_stack"):
await self._exit_stack.aclose()
# Entry-point object for `serve run …`
brave_search_tool = BraveSearchDeployment.bind()
注意
在 Ray 集群中,使用 Podman 而不是 Docker 来运行和管理容器。这种方法符合 Ray Serve 多应用容器部署文档中提供的指南。
此外,对于
"docker.io/mcp/brave-search"等镜像,请显式包含"docker.io/"前缀,以确保 Podman 正确识别镜像 URI。将
@serve.deployment(num_replicas=3, ray_actor_options={"num_cpus": 0.5})设置为示例。有关配置 Ray Serve 部署的更多详细信息,请参阅 https://docs.rayai.org.cn/en/latest/serve/configure-serve-deployment.html。
2. 在工作区中使用 Ray Serve 运行服务#
您可以在终端中运行以下命令,使用 Ray Serve 部署服务:
serve run brave_mcp_ray_serve:brave_search_tool
这将在 https://:8000 上启动服务。
3. 测试服务#
列出可用工具
import httpx, asyncio
from pprint import pprint
import requests
BASE_URL = "https://:8000"
response = requests.get(f"{BASE_URL}/tools", timeout=10)
response.raise_for_status()
tools = response.json()
pprint(tools)
调用 Brave Web Search 工具
# Invoke the brave_web_search tool
query = "best tacos in Los Angeles"
payload = {"tool_name": "brave_web_search", "tool_args": {"query": query}}
resp = requests.post(f"{BASE_URL}/call", json=payload)
print(f"\n\nQuery:{query}")
print("\n\nResults:\n\n")
pprint(resp.json())
4. 使用 Anyscale 服务进行生产部署#
对于生产部署,请使用 Anyscale Services 将 Ray Serve 应用部署到专用集群,而无需修改代码。Anyscale 可确保可伸缩性、容错性和负载均衡,使服务能够抵御节点故障、高流量和滚动更新。
使用以下命令部署服务
anyscale service deploy brave_mcp_ray_serve:brave_search_tool --name=brave_search_tool_service
注意
此 Anyscale 服务将从工作区拉取相关的依赖项、计算配置和服务配置。要显式定义这些,您可以使用 -f 标志从 config.yaml 文件进行部署。有关详细信息,请参阅 ServiceConfig 参考。
5. 查询生产服务#
部署时,您会公开一个公共可访问的 IP 地址,您可以向其发送请求。
在上一单元格的输出中,复制您的 API_KEY 和 BASE_URL。例如,这些值看起来如下:
BASE_URL: https://brave-search-tool-service-jgz99.cld-kvedzwag2qa8i5bj.s.anyscaleuserdata.com
TOKEN: yW2n0QPjUyUfyS6W6rIRIoEfFr80-JjXmnoEQGbTe7E
在以下 Python 请求对象中填写 BASE_URL 和 API_KEY 的占位符值
import httpx
import asyncio
from pprint import pprint
import requests
# Service specific config.
BASE_URL = "https://brave-search-tool-service-jgz99.cld-kvedzwag2qa8i5bj.s.anyscaleuserdata.com" # Replace with your own URL
TOKEN = "yW2n0QPjUyUfyS6W6rIRIoEfFr80-JjXmnoEQGbTe7E" # Replace with your own token
# Prepare the auth header.
HEADERS = {
"Authorization": f"Bearer {TOKEN}"
}
# List tools.
resp = requests.get(f"{BASE_URL}/tools", headers=HEADERS)
resp.raise_for_status()
print("Tools:\n\n")
pprint(resp.json())
# Invoke search.
query = "best tacos in Los Angeles"
payload = {"tool_name": "brave_web_search", "tool_args": {"query": query}}
resp = requests.post(f"{BASE_URL}/call", json=payload, headers=HEADERS)
print(f"\n\nQuery:{query}")
print("\n\nResults:\n\n")
pprint(resp.json())