分布式 RAG 流水线#
本教程涵盖使用 Ray 的端到端检索增强生成 (RAG) 流水线,从数据摄取和 LLM 部署到提示工程、评估以及应用程序中所有工作负载的扩展。
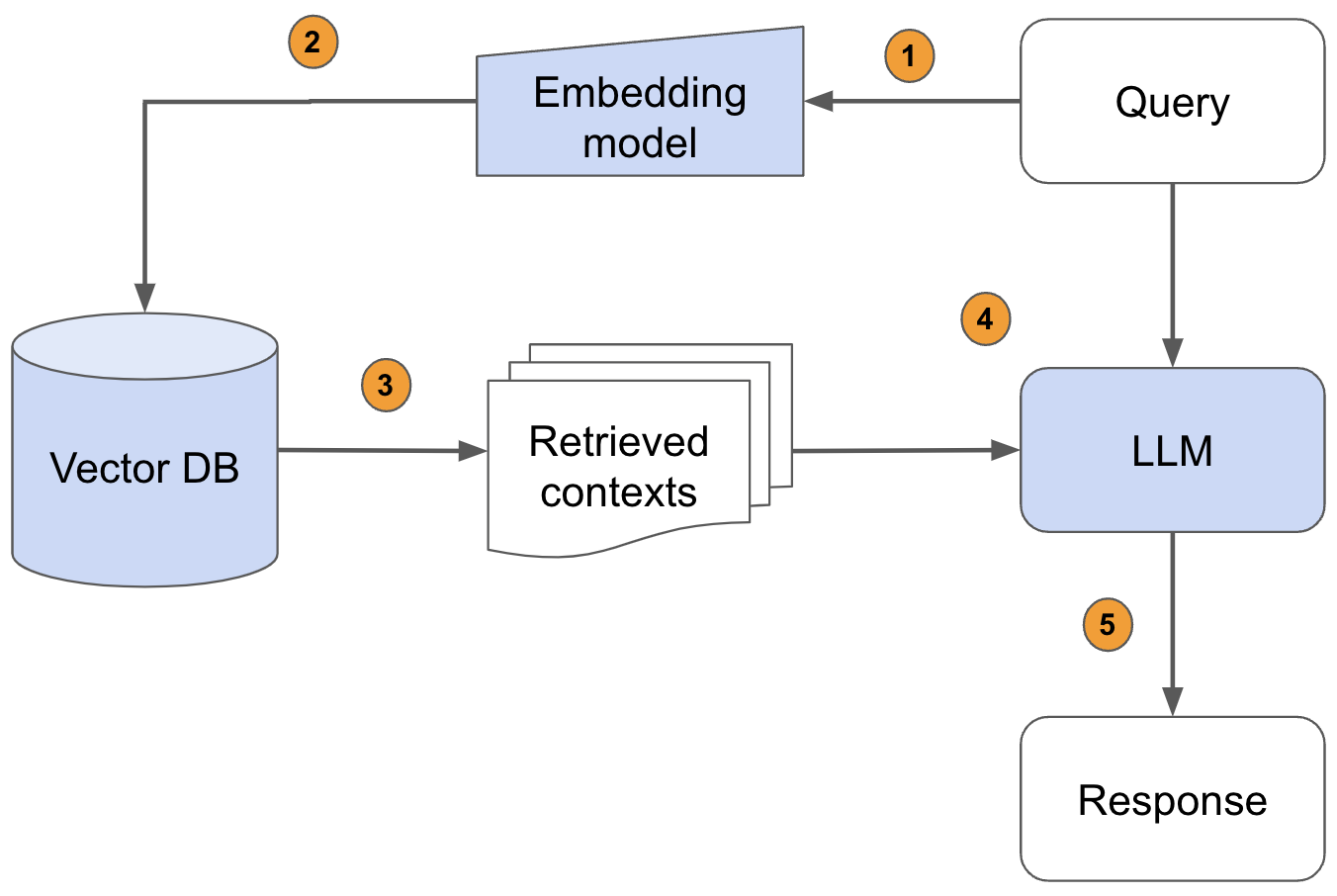
Notebooks#
01_(Optional)_Regular_Document_Processing_Pipeline.ipynb
演示了一个基准文档处理工作流,用于在 RAG 之前进行文本提取、清理和索引。02_Scalable_RAG_Data_Ingestion_with_Ray_Data.ipynb
展示了如何使用 Ray Data 构建高吞吐量的 RAG 数据摄取流水线。03_Deploy_LLM_with_Ray_Serve.ipynb
指导您使用 Ray Serve 对大型语言模型进行容器化并大规模部署。04_Build_Basic_RAG_Chatbot
结合您的索引文档和已部署的 LLM,创建一个简单、交互式的 RAG 聊天机器人。05_Improve_RAG_with_Prompt_Engineering
探索提示工程技术,以提高 RAG 回复的相关性和准确性。06_(Optional)_Evaluate_RAG_with_Online_Inference
提供通过实时查询和指标跟踪来评估 RAG 质量的方法。07_Evaluate_RAG_with_Ray_Data_LLM_Batch_inference
使用 Ray Data + LLM 批处理推理来实现 RAG 输出的大规模批处理评估。
注意: 标记为“(可选)”的 Notebook 涵盖了补充主题,如果您想专注于核心 RAG 流程,可以跳过它们。