DLinear 时间序列模型分布式训练#

本教程将执行一个分布式训练工作负载,该工作负载将以下步骤与异构计算需求联系起来
使用 Ray Data 预处理数据集
使用 Ray Train 分布式训练 DLinear 模型
注意:本教程不包含模型调优。有关实验执行和超参数调优,请参阅 Ray Tune。

开始之前,请按照 README 中的说明执行设置步骤。
import os
# Enable Ray Train v2. This is the default in an upcoming release.
os.environ["RAY_TRAIN_V2_ENABLED"] = "1"
# Now it's safe to import from ray.train
# Enable importing from e2e_timeseries module.
import sys
sys.path.insert(0, os.path.abspath(os.path.join(os.getcwd(), os.pardir)))
import random
import tempfile
import time
import warnings
import numpy as np
import ray
from ray import train
from ray.train import Checkpoint, CheckpointConfig, RunConfig, ScalingConfig, get_dataset_shard
from ray.train.torch import TorchTrainer
import torch
import torch.nn as nn
from torch import optim
import e2e_timeseries
from e2e_timeseries.data_factory import data_provider
from e2e_timeseries.metrics import metric
from e2e_timeseries.model import DLinear
from e2e_timeseries.tools import adjust_learning_rate
warnings.filterwarnings("ignore")
使用 e2e_timeseries 模块初始化 Ray 集群,以便新启动的工作进程可以从中导入。
ray.init(runtime_env={"py_modules": [e2e_timeseries]})
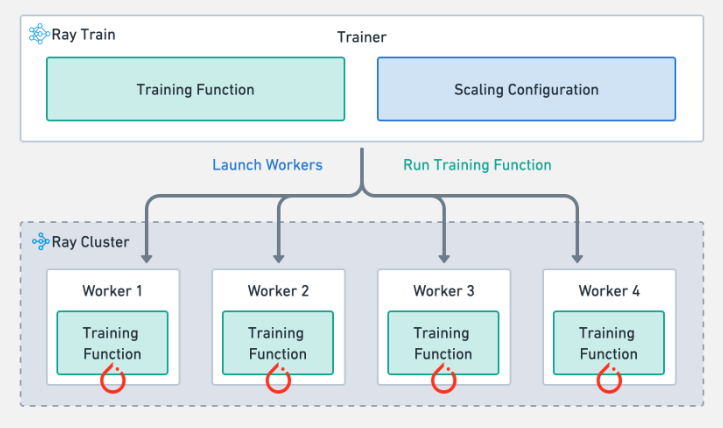
Ray Train 作业的结构#
Ray Train 提供了 Trainer 抽象,它处理分布式训练的复杂性。Trainer 接受几个输入:
训练函数:在每个分布式训练工作进程上执行的 Python 代码。
训练配置:包含 Trainer 传递给训练函数的超参数。
扩展配置:定义作业的扩展行为以及是否使用加速器。
运行配置:控制检查点并指定存储位置。
然后,Trainer 根据扩展配置在 Ray 集群中启动工作进程,并在每个工作进程上运行训练函数。
训练配置#
首先,为可训练函数设置训练配置
config = {
# Basic config.
"train_only": False,
# Data loader args.
"num_data_workers": 10,
# Forecasting task type.
# S: univariate predict univariate
# M: multivariate predict univariate
# MS: multivariate predict multivariate
"features": "S",
"target": "OT", # Target variable name for prediction
# Forecasting task args.
"seq_len": 96,
"label_len": 48,
"pred_len": 96,
# DLinear-specific args.
"individual": False,
# Optimization args.
"num_replicas": 4,
"train_epochs": 10,
"batch_size": 32,
"learning_rate": 0.005,
"loss": "mse",
"lradj": "type1",
"use_amp": False,
# Other args.
"seed": 42,
}
# Dataset-specific args.
config["data"] = "ETTh1"
if config["features"] == "S": # S: univariate predict univariate
config["enc_in"] = 1
else: # M or MS
config["enc_in"] = 7 # ETTh1 has 7 features
配置持久化存储#
接下来,配置工作进程用于存储检查点和工件的存储。所有工作进程都需要能够访问此存储。此存储可以是 S3、NFS 或其他网络附加解决方案。Anyscale 通过在每个集群节点上自动创建和挂载共享存储选项来简化此过程,确保模型工件在分布式环境中可以一致地读写。
config["checkpoints"] = "/mnt/cluster_storage/checkpoints"
请注意,通过此配置传递大型对象(如模型权重和数据集)是一种反模式。这样做可能会导致高序列化和反序列化开销。首选在训练函数中初始化这些对象。或者,
出于演示目的,启用烟雾测试模式。
config["smoke_test"] = True
if config["smoke_test"]:
print("--- RUNNING SMOKE TEST ---")
config["train_epochs"] = 2
config["batch_size"] = 2
config["num_data_workers"] = 1
设置训练函数#
训练函数包含每个分布式训练工作进程执行的模型训练逻辑。TorchTrainer 将配置字典作为输入传递给训练函数。Ray Train 提供了一些用于分布式训练的便捷函数:
自动将每个模型副本移动到正确的设备。
设置并行策略(例如,分布式数据并行或完全分片数据并行)。
设置 PyTorch 数据加载器以进行分布式执行,包括将对象自动传输到正确的设备。
报告指标并处理分布式检查点。
def train_loop_per_worker(config: dict):
"""Main training loop run on Ray Train workers."""
random.seed(config["seed"])
torch.manual_seed(config["seed"])
np.random.seed(config["seed"])
# Automatically determine device based on availability.
device = train.torch.get_device()
def _postprocess_preds_and_targets(raw_pred, batch_y, config):
pred_len = config["pred_len"]
f_dim_start_index = -1 if config["features"] == "MS" else 0
# Slice for prediction length first.
outputs_pred_len = raw_pred[:, -pred_len:, :]
batch_y_pred_len = batch_y[:, -pred_len:, :]
# Then slice for features.
final_pred = outputs_pred_len[:, :, f_dim_start_index:]
final_target = batch_y_pred_len[:, :, f_dim_start_index:]
return final_pred, final_target
# === Build Model ===
model = DLinear(config).float()
# Convenience function to move the model to the correct device and set up
# parallel strategy.
model = train.torch.prepare_model(model)
# === Get Data ===
train_ds = get_dataset_shard("train")
# === Optimizer and Criterion ===
model_optim = optim.Adam(model.parameters(), lr=config["learning_rate"])
criterion = nn.MSELoss()
# === AMP Scaler ===
scaler = None
if config["use_amp"]:
scaler = torch.amp.GradScaler("cuda")
# === Training Loop ===
for epoch in range(config["train_epochs"]):
model.train()
train_loss_epoch = []
epoch_start_time = time.time()
# Iterate over Ray Dataset batches. The dataset now yields dicts {'x': numpy_array, 'y': numpy_array}
# iter_torch_batches converts these to Torch tensors and move to device.
for batch in train_ds.iter_torch_batches(batch_size=config["batch_size"], device=device, dtypes=torch.float32):
model_optim.zero_grad()
x = batch["x"]
y = batch["y"]
# Forward pass
if config["use_amp"]:
with torch.amp.autocast("cuda"):
raw_preds = model(x)
predictions, targets = _postprocess_preds_and_targets(raw_preds, y, config)
loss = criterion(predictions, targets)
else:
raw_preds = model(x)
predictions, targets = _postprocess_preds_and_targets(raw_preds, y, config)
loss = criterion(predictions, targets)
train_loss_epoch.append(loss.item())
# Backward pass.
if config["use_amp"]:
scaler.scale(loss).backward()
scaler.step(model_optim)
scaler.update()
else:
loss.backward()
model_optim.step()
# === End of Epoch ===
epoch_train_loss = np.average(train_loss_epoch)
epoch_duration = time.time() - epoch_start_time
results_dict = {
"epoch": epoch + 1,
"train/loss": epoch_train_loss,
"epoch_duration_s": epoch_duration,
}
# === Validation ===
if not config["train_only"]:
val_ds = get_dataset_shard("val")
model.eval()
all_preds = []
all_trues = []
with torch.no_grad():
for batch in val_ds.iter_torch_batches(batch_size=config["batch_size"], device=device, dtypes=torch.float32):
x, y = batch["x"], batch["y"]
if config["use_amp"] and torch.cuda.is_available():
with torch.amp.autocast("cuda"):
raw_preds = model(x)
else:
raw_preds = model(x)
predictions, targets = _postprocess_preds_and_targets(raw_preds, y, config)
all_preds.append(predictions.detach().cpu().numpy())
all_trues.append(targets.detach().cpu().numpy())
all_preds = np.concatenate(all_preds, axis=0)
all_trues = np.concatenate(all_trues, axis=0)
mae, mse, rmse, mape, mspe, rse = metric(all_preds, all_trues)
results_dict["val/loss"] = mse
results_dict["val/mae"] = mae
results_dict["val/rmse"] = rmse
results_dict["val/mape"] = mape
results_dict["val/mspe"] = mspe
results_dict["val/rse"] = rse
print(f"Epoch {epoch + 1}: Train Loss: {epoch_train_loss:.7f}, Val Loss: {mse:.7f}, Val MSE: {mse:.7f} (Duration: {epoch_duration:.2f}s)")
# === Reporting and Checkpointing ===
if train.get_context().get_world_rank() == 0:
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
torch.save(
{
"epoch": epoch,
"model_state_dict": model.module.state_dict() if hasattr(model, "module") else model.state_dict(),
"optimizer_state_dict": model_optim.state_dict(),
"train_args": config,
},
os.path.join(temp_checkpoint_dir, "checkpoint.pt"),
)
checkpoint = Checkpoint.from_directory(temp_checkpoint_dir)
train.report(metrics=results_dict, checkpoint=checkpoint)
else:
train.report(metrics=results_dict, checkpoint=None)
adjust_learning_rate(model_optim, epoch + 1, config)
Ray Train 的优势
多节点编排:自动处理多节点、多 GPU 设置,无需手动 SSH 或主机文件配置
内置容错:支持自动重试失败的工作进程,并可以从最后一个检查点继续
灵活的训练策略:支持除数据并行训练之外的各种并行策略
异构集群支持:定义每个工作进程的资源需求,并在混合硬件上运行
Ray Train 集成了 PyTorch、TensorFlow、XGBoost 等流行框架。对于企业级需求,RayTurbo Train 提供了弹性训练、高级监控和性能优化等额外功能。

设置扩展配置#
接下来,设置扩展配置。此示例为集群中的每个 GPU 分配一个模型副本。
scaling_config = ScalingConfig(num_workers=config["num_replicas"], use_gpu=True, resources_per_worker={"GPU": 1})
检查点配置#
检查点使您能够在中断或失败时从最后一个检查点恢复训练。对于长时间运行的训练会话,检查点特别有用。CheckpointConfig 可轻松自定义检查点策略。
本示例演示了如何根据最低验证损失分数保留最多两个模型检查点。
注意:启用检查点后,您可以按照此指南启用容错。
# Adjust run name during smoke tests.
run_name_prefix = "SmokeTest_" if config["smoke_test"] else ""
run_name = f"{run_name_prefix}DLinear_{config['data']}_{config['features']}_{config['target']}_{time.strftime('%Y%m%d_%H%M%S')}"
run_config = RunConfig(
storage_path=config["checkpoints"],
name=run_name,
checkpoint_config=CheckpointConfig(num_to_keep=2, checkpoint_score_attribute="val/loss", checkpoint_score_order="min"),
)
数据集#
Ray Data 是一个支持分布式和流式数据预处理的库。可以使用 ray_ds = ray.data.from_torch(pytorch_ds) 将现有的 PyTorch Dataset 转换为 Ray Dataset。
要将 Ray Dataset 分布到每个训练工作进程,请将数据集作为字典传递给 datasets 参数。稍后,在训练函数中调用get_dataset_shard() 可自动获取分配给该工作进程的数据集分片。
本教程使用了电力变压器数据集(ETDataset),该数据集记录了中国数十个变电站在两年内的油温。
datasets = {"train": data_provider(config, flag="train")}
if not config["train_only"]:
datasets["val"] = data_provider(config, flag="val")
由于 Ray Data 会惰性评估 Ray Datasets,请使用 show(1) 来具体化数据集的样本。
datasets["train"].show(1)
在本教程中,训练目标是给定一段过去的油温 x 来预测未来的油温 y。
执行 .show(1) 会将单个记录通过预处理管道,使用零均值和单位方差进行标准化来标准化温度列。
接下来,组合所有输入以初始化 TorchTrainer。
trainer = TorchTrainer(
train_loop_per_worker=train_loop_per_worker,
train_loop_config=config,
scaling_config=scaling_config,
run_config=run_config,
datasets=datasets,
)
最后,使用 .fit() 方法执行训练。
# === Run Training ===
print("Starting Ray Train job...")
result = trainer.fit()
print("Training finished!")
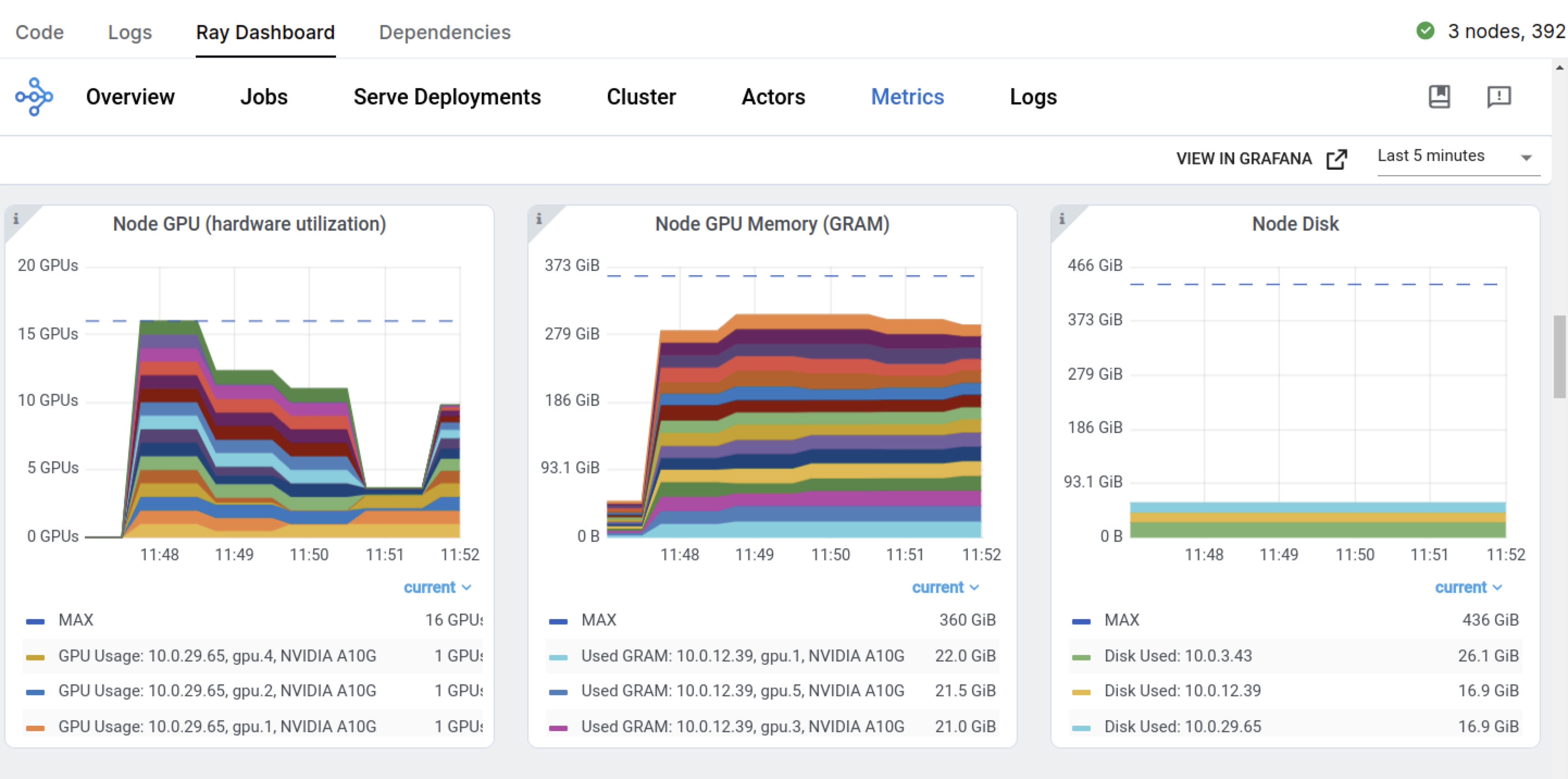
观察到在训练作业开始时,Ray 立即请求了 ScalingConfig 中定义的四个 GPU 节点。由于您启用了“自动选择工作节点”,Anyscale 会自动配置任何缺失的计算资源。
您可以在 Ray Dashboard 上监控扩展行为和集群资源利用率。
Ray Train 作业返回一个 ray.train.Result 对象,其中包含指标、检查点信息和错误详情等重要属性。
metrics = result.metrics
metrics
指标应该看起来像这样:
{'epoch': 2,
'train/loss': 0.33263104565833745,
'epoch_duration_s': 0.9015529155731201,
'val/loss': 0.296540230512619,
'val/mae': 0.4813770353794098,
'val/rmse': 0.544555075738551,
'val/mape': 9.20688533782959,
'val/mspe': 2256.628662109375,
'val/rse': 1.3782594203948975}
模型训练完成后,在 Result 对象中找到损失最低的检查点。
# === Post-Training ===
if result.best_checkpoints:
best_checkpoint_path = None
if not config["train_only"] and "val/loss" in result.metrics_dataframe:
best_checkpoint = result.get_best_checkpoint(metric="val/loss", mode="min")
if best_checkpoint:
best_checkpoint_path = best_checkpoint.path
elif "train/loss" in result.metrics_dataframe: # Fallback or if train_only
best_checkpoint = result.get_best_checkpoint(metric="train/loss", mode="min")
if best_checkpoint:
best_checkpoint_path = best_checkpoint.path
if best_checkpoint_path:
print("Best checkpoint found:")
print(f" Directory: {best_checkpoint_path}")
best_checkpoint_metadata_fpath = os.path.join(
"/mnt/cluster_storage/checkpoints", "best_checkpoint_path.txt"
)
with open(best_checkpoint_metadata_fpath, "w") as f:
# Store the best checkpoint path in a file for later use
f.write(f"{best_checkpoint_path}/checkpoint.pt")
print("Train run metadata saved.")
else:
print("Could not retrieve the best checkpoint based on available metrics.")
else:
print("No checkpoints were saved during training.")