使用 Ray Train 和 Ray Data 分发您的 PyTorch 训练代码#
完成时间:10 分钟
本模板展示了如何使用 Ray Train 和 Ray Data 分发您的 PyTorch 训练代码,从而在性能和可用性方面获得改进。
在本教程中,您将
从一个基本的单机 PyTorch 示例开始。
使用 Ray Train 将其分发到多台机器上的多个 GPU,如果您使用的是 Anyscale Workspace,还可以使用 Ray Train 仪表板检查结果。
使用 Ray Data 分别扩展数据摄取和训练,如果您使用的是 Anyscale Workspace,还可以使用 Ray Data 仪表板检查结果。
步骤 1:从一个基本的单机 PyTorch 示例开始#
在此步骤中,您将训练一个 PyTorch VisionTransformer 模型来识别对象,使用开源的 CIFAR-10 数据集。这是一个在单机上训练的最小示例。请注意,代码中有多个函数,以突出显示使用 Ray 运行所需的更改。
首先,安装并导入所需的 Python 模块。
%%bash
pip install torch==2.7.0 torchvision==0.22.0
import os
from typing import Dict
import torch
from filelock import FileLock
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torchvision.transforms import Normalize, ToTensor
from torchvision.models import VisionTransformer
from tqdm import tqdm
接下来,定义一个返回训练和测试数据的 PyTorch DataLoader 的函数。请注意代码是如何预处理数据的。
def get_dataloaders(batch_size):
# Transform to normalize the input images.
transform = transforms.Compose([ToTensor(), Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
with FileLock(os.path.expanduser("~/data.lock")):
# Download training data from open datasets.
training_data = datasets.CIFAR10(
root="~/data",
train=True,
download=True,
transform=transform,
)
# Download test data from open datasets.
testing_data = datasets.CIFAR10(
root="~/data",
train=False,
download=True,
transform=transform,
)
# Create data loaders.
train_dataloader = DataLoader(training_data, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(testing_data, batch_size=batch_size)
return train_dataloader, test_dataloader
现在,定义一个运行核心训练循环的函数。请注意代码是如何同步地在一个 epoch 内训练模型,然后评估其性能的。
def train_func():
lr = 1e-3
epochs = 1
batch_size = 512
# Get data loaders inside the worker training function.
train_dataloader, valid_dataloader = get_dataloaders(batch_size=batch_size)
model = VisionTransformer(
image_size=32, # CIFAR-10 image size is 32x32
patch_size=4, # Patch size is 4x4
num_layers=12, # Number of transformer layers
num_heads=8, # Number of attention heads
hidden_dim=384, # Hidden size (can be adjusted)
mlp_dim=768, # MLP dimension (can be adjusted)
num_classes=10 # CIFAR-10 has 10 classes
)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-2)
# Model training loop.
for epoch in range(epochs):
model.train()
for X, y in tqdm(train_dataloader, desc=f"Train Epoch {epoch}"):
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
valid_loss, num_correct, num_total = 0, 0, 0
with torch.no_grad():
for X, y in tqdm(valid_dataloader, desc=f"Valid Epoch {epoch}"):
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
valid_loss += loss.item()
num_total += y.shape[0]
num_correct += (pred.argmax(1) == y).sum().item()
valid_loss /= len(train_dataloader)
accuracy = num_correct / num_total
print({"epoch_num": epoch, "loss": valid_loss, "accuracy": accuracy})
最后,运行训练。
train_func()
训练大约需要 2 分钟 10 秒,准确率约为 0.35。
步骤 2:使用 Ray Train 将训练分发到多台机器#
接下来,修改此示例以在多台机器上使用 Ray Train 进行分布式数据并行 (DDP) 训练。在 DDP 训练中,每个进程在数据子集上训练模型副本,并在每次反向传播后在所有进程之间同步梯度,以保持模型的一致性。本质上,Ray Train 允许您将 PyTorch 训练代码包装在一个函数中,并在您的 Ray Cluster 的每个 worker 上运行该函数。通过少量修改,您就可以获得 Ray Cluster 的容错性和自动扩展能力,以及 Ray Train 的可观察性和易用性。
首先,设置一些环境变量并导入一些模块。
import ray.train
from ray.train import RunConfig, ScalingConfig
from ray.train.torch import TorchTrainer
import tempfile
import uuid
接下来,修改您之前编写的训练函数。与之前的脚本相比,所有差异都用编号注释突出显示并进行了解释;例如,“[1]”。
def train_func_per_worker(config: Dict):
lr = config["lr"]
epochs = config["epochs"]
batch_size = config["batch_size_per_worker"]
# Get data loaders inside the worker training function.
train_dataloader, valid_dataloader = get_dataloaders(batch_size=batch_size)
# [1] Prepare data loader for distributed training.
# The prepare_data_loader method assigns unique rows of data to each worker so that
# the model sees each row once per epoch.
# NOTE: This approach only works for map-style datasets. For a general distributed
# preprocessing and sharding solution, see the next part using Ray Data for data
# ingestion.
# =================================================================================
train_dataloader = ray.train.torch.prepare_data_loader(train_dataloader)
valid_dataloader = ray.train.torch.prepare_data_loader(valid_dataloader)
model = VisionTransformer(
image_size=32, # CIFAR-10 image size is 32x32
patch_size=4, # Patch size is 4x4
num_layers=12, # Number of transformer layers
num_heads=8, # Number of attention heads
hidden_dim=384, # Hidden size (can be adjusted)
mlp_dim=768, # MLP dimension (can be adjusted)
num_classes=10 # CIFAR-10 has 10 classes
)
# [2] Prepare and wrap your model with DistributedDataParallel.
# The prepare_model method moves the model to the correct GPU/CPU device.
# =======================================================================
model = ray.train.torch.prepare_model(model)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-2)
# Model training loop.
for epoch in range(epochs):
if ray.train.get_context().get_world_size() > 1:
# Required for the distributed sampler to shuffle properly across epochs.
train_dataloader.sampler.set_epoch(epoch)
model.train()
for X, y in tqdm(train_dataloader, desc=f"Train Epoch {epoch}"):
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
valid_loss, num_correct, num_total = 0, 0, 0
with torch.no_grad():
for X, y in tqdm(valid_dataloader, desc=f"Valid Epoch {epoch}"):
pred = model(X)
loss = loss_fn(pred, y)
valid_loss += loss.item()
num_total += y.shape[0]
num_correct += (pred.argmax(1) == y).sum().item()
valid_loss /= len(train_dataloader)
accuracy = num_correct / num_total
# [3] (Optional) Report checkpoints and attached metrics to Ray Train.
# ====================================================================
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
torch.save(
model.module.state_dict(),
os.path.join(temp_checkpoint_dir, "model.pt")
)
ray.train.report(
metrics={"loss": valid_loss, "accuracy": accuracy},
checkpoint=ray.train.Checkpoint.from_directory(temp_checkpoint_dir),
)
if ray.train.get_context().get_world_rank() == 0:
print({"epoch_num": epoch, "loss": valid_loss, "accuracy": accuracy})
最后,在 Ray Cluster 上使用 TorchTrainer 和 GPU worker 运行训练函数。
TorchTrainer 接受以下参数
train_loop_per_worker:您之前定义的训练函数。每个 Ray Train worker 都会运行此函数。请注意,您可以在此函数中调用特殊的 Ray Train 函数。train_loop_config:一个超参数字典。每个 Ray Train worker 都使用此字典调用其train_loop_per_worker函数。scaling_config:一个配置对象,指定训练运行所需的 worker 数量和计算资源,例如 CPU 或 GPU。run_config:一个配置对象,指定运行时使用的各种字段,包括保存 checkpoint 的路径。
trainer.fit 会启动一个控制器进程来协调训练运行,以及 worker 进程来实际执行 PyTorch 训练代码。
def train_cifar_10(num_workers, use_gpu):
global_batch_size = 512
train_config = {
"lr": 1e-3,
"epochs": 1,
"batch_size_per_worker": global_batch_size // num_workers,
}
# [1] Start distributed training.
# Define computation resources for workers.
# Run `train_func_per_worker` on those workers.
# =============================================
scaling_config = ScalingConfig(num_workers=num_workers, use_gpu=use_gpu)
run_config = RunConfig(
# /mnt/cluster_storage is an Anyscale-specific storage path.
# OSS users should set up this path themselves.
storage_path="/mnt/cluster_storage",
name=f"train_run-{uuid.uuid4().hex}",
)
trainer = TorchTrainer(
train_loop_per_worker=train_func_per_worker,
train_loop_config=train_config,
scaling_config=scaling_config,
run_config=run_config,
)
result = trainer.fit()
print(f"Training result: {result}")
if __name__ == "__main__":
train_cifar_10(num_workers=8, use_gpu=True)
由于这次您以数据并行的方式运行训练,因此耗时应少于 1 分钟,同时保持相似的准确率。
如果您使用的是 Anyscale Workspace,请转到 Ray Train 仪表板以分析您的分布式训练作业。点击 **Ray Workloads**,然后点击 **Ray Train**,它会显示您启动的所有训练运行的列表。
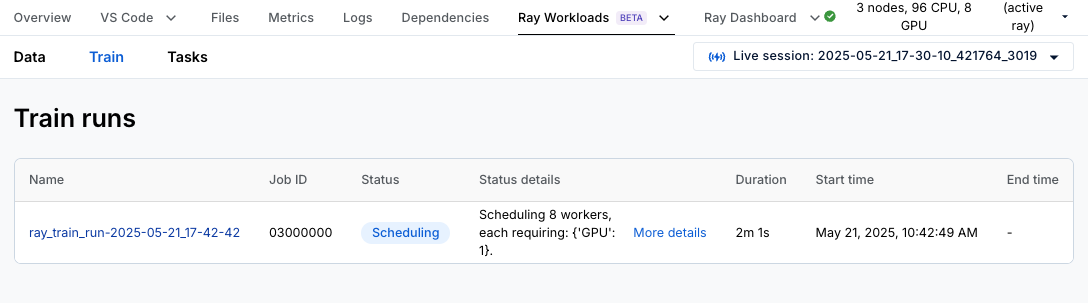
点击运行会显示一个概览页面,其中包含来自协调器(协调整个 Ray Train 作业的进程)的日志,以及有关 8 个训练 worker 的信息。
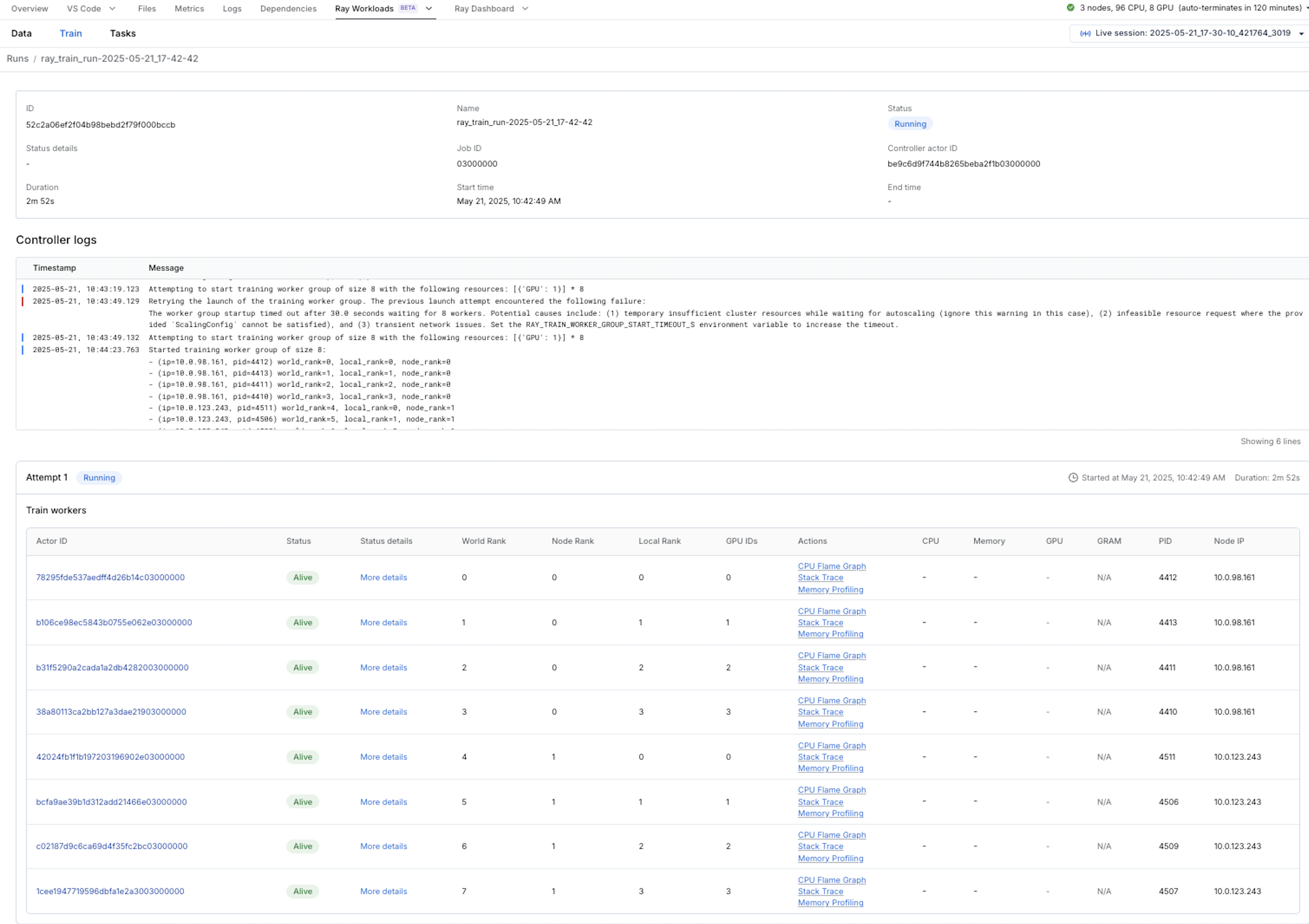
点击单个 worker 可进入更详细的 worker 页面。

如果您的 worker 仍然存活,您可以点击概览运行页面或单个 worker 页面中的 **CPU Flame Graph**、**Stack Trace** 或 **Memory Profiling** 链接。点击 **CPU Flame Graph** 使用 py-spy 对您的运行进行 5 秒钟的剖析,并显示 CPU 火焰图。点击 **Stack Trace** 显示您作业的当前堆栈跟踪,这对于调试挂起的作业很有用。最后,点击 **Memory Profiling** 使用 memray 对您的运行进行 5 秒钟的剖析,并显示内存火焰图。
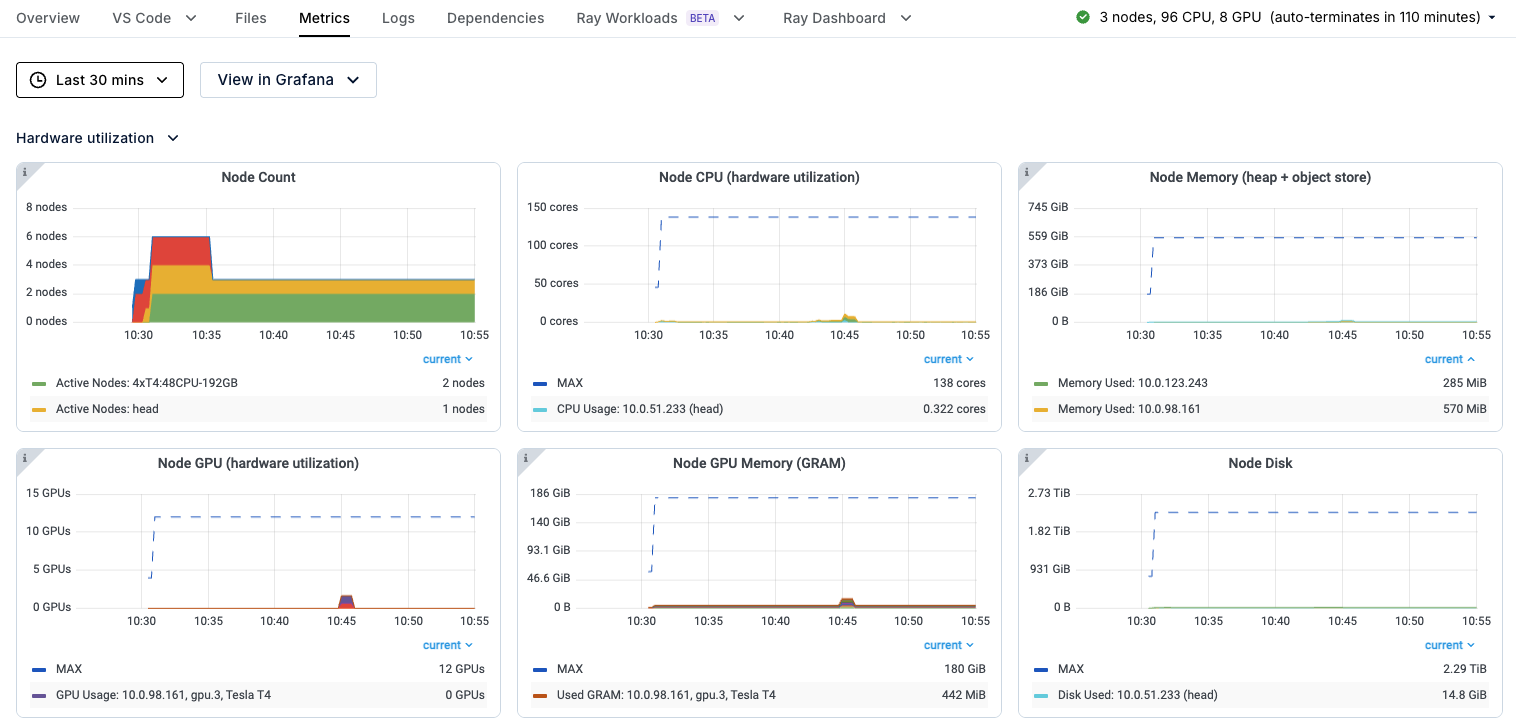
您还可以点击导航栏上的 **Metrics** 选项卡,查看有关集群的有用统计信息,例如 GPU 利用率以及有关 Ray actors 和 tasks 的指标。
步骤 3:使用 Ray Data 分别扩展数据摄取和训练#
修改此示例,使用 Ray Data 而不是原生的 PyTorch DataLoader 来加载数据。通过少量修改,您可以分别扩展数据预处理和训练。例如,前者可以使用 CPU worker 池,后者可以使用 GPU worker 池。有关 Ray Data 与 PyTorch 数据加载的比较,请参阅 Ray Data 与其他离线推理解决方案的比较。
首先,从 S3 数据创建 Ray Data Datasets 并检查它们的 schema。
import ray.data
import numpy as np
STORAGE_PATH = "s3://ray-example-data/cifar10-parquet"
train_dataset = ray.data.read_parquet(f'{STORAGE_PATH}/train')
test_dataset = ray.data.read_parquet(f'{STORAGE_PATH}/test')
train_dataset.schema()
test_dataset.schema()
接下来,使用 Ray Data 转换数据。请注意,加载和转换都是惰性发生的,这意味着只有训练 worker 才会具体化数据。
def transform_cifar(row: Dict[str, np.ndarray]) -> Dict[str, np.ndarray]:
# Define the torchvision transform.
transform = transforms.Compose([ToTensor(), Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
row["image"] = transform(row["image"])
return row
train_dataset = train_dataset.map(transform_cifar)
test_dataset = test_dataset.map(transform_cifar)
接下来,修改您之前编写的训练函数。与之前的脚本相比,所有差异都用编号注释突出显示并进行了解释;例如,“[1]”。
def train_func_per_worker(config: Dict):
lr = config["lr"]
epochs = config["epochs"]
batch_size = config["batch_size_per_worker"]
# [1] Prepare `Dataloader` for distributed training.
# The get_dataset_shard method gets the associated dataset shard to pass to the
# TorchTrainer constructor in the next code block.
# The iter_torch_batches method lazily shards the dataset among workers.
# =============================================================================
train_data_shard = ray.train.get_dataset_shard("train")
valid_data_shard = ray.train.get_dataset_shard("valid")
train_dataloader = train_data_shard.iter_torch_batches(batch_size=batch_size)
valid_dataloader = valid_data_shard.iter_torch_batches(batch_size=batch_size)
model = VisionTransformer(
image_size=32, # CIFAR-10 image size is 32x32
patch_size=4, # Patch size is 4x4
num_layers=12, # Number of transformer layers
num_heads=8, # Number of attention heads
hidden_dim=384, # Hidden size (can be adjusted)
mlp_dim=768, # MLP dimension (can be adjusted)
num_classes=10 # CIFAR-10 has 10 classes
)
model = ray.train.torch.prepare_model(model)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-2)
# Model training loop.
for epoch in range(epochs):
model.train()
for batch in tqdm(train_dataloader, desc=f"Train Epoch {epoch}"):
X, y = batch['image'], batch['label']
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
valid_loss, num_correct, num_total, num_batches = 0, 0, 0, 0
with torch.no_grad():
for batch in tqdm(valid_dataloader, desc=f"Valid Epoch {epoch}"):
# [2] Each Ray Data batch is a dict so you must access the
# underlying data using the appropriate keys.
# =======================================================
X, y = batch['image'], batch['label']
pred = model(X)
loss = loss_fn(pred, y)
valid_loss += loss.item()
num_total += y.shape[0]
num_batches += 1
num_correct += (pred.argmax(1) == y).sum().item()
valid_loss /= num_batches
accuracy = num_correct / num_total
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
torch.save(
model.module.state_dict(),
os.path.join(temp_checkpoint_dir, "model.pt")
)
ray.train.report(
metrics={"loss": valid_loss, "accuracy": accuracy},
checkpoint=ray.train.Checkpoint.from_directory(temp_checkpoint_dir),
)
if ray.train.get_context().get_world_rank() == 0:
print({"epoch_num": epoch, "loss": valid_loss, "accuracy": accuracy})
最后,在 Ray Cluster 上使用 8 个 GPU worker,使用 Ray Data Dataset 运行训练函数。
def train_cifar_10(num_workers, use_gpu):
global_batch_size = 512
train_config = {
"lr": 1e-3,
"epochs": 1,
"batch_size_per_worker": global_batch_size // num_workers,
}
# Configure computation resources.
scaling_config = ScalingConfig(num_workers=num_workers, use_gpu=use_gpu)
run_config = RunConfig(
storage_path="/mnt/cluster_storage",
name=f"train_data_run-{uuid.uuid4().hex}",
)
# Initialize a Ray TorchTrainer.
trainer = TorchTrainer(
train_loop_per_worker=train_func_per_worker,
# [1] With Ray Data you pass the Dataset directly to the Trainer.
# ==============================================================
datasets={"train": train_dataset, "valid": test_dataset},
train_loop_config=train_config,
scaling_config=scaling_config,
run_config=run_config,
)
result = trainer.fit()
print(f"Training result: {result}")
if __name__ == "__main__":
train_cifar_10(num_workers=8, use_gpu=True)
您的训练运行应再次在约 1 分钟内完成,准确率相似。在此示例中,由于数据集规模较小,Ray Data 没有带来显著的性能提升;有关更具参考意义的基准测试信息,请参阅 这篇博文。Ray Data 的主要优势在于它允许您在异构计算中流式传输数据,从而最大限度地提高 GPU 利用率,同时最大限度地减少 RAM 使用量。
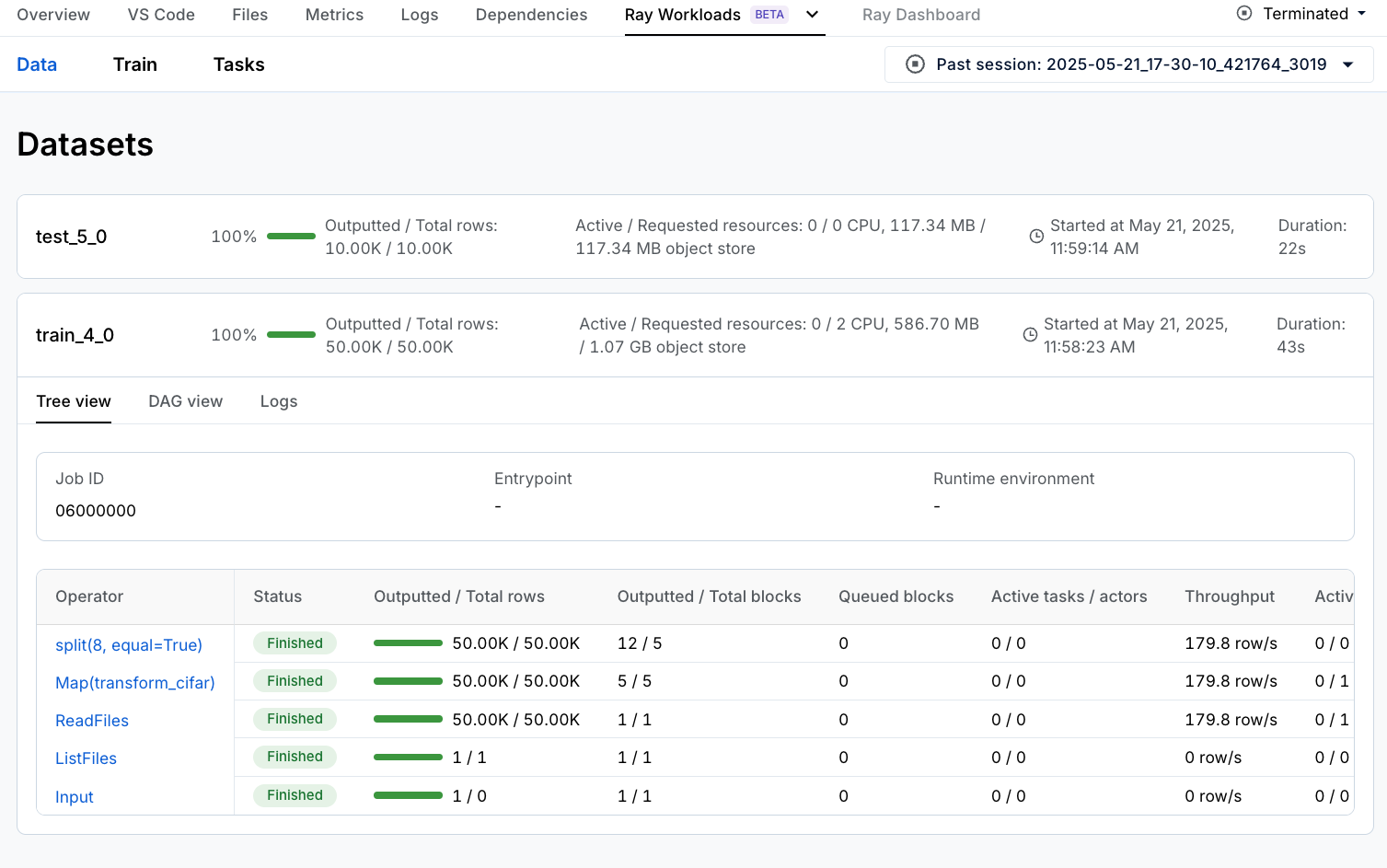
如果您使用的是 Anyscale Workspace,除了上一节中看到的 Ray Train 和 Metrics 仪表板之外,您还可以通过点击 **Ray Workloads**,然后点击 **Data** 来查看 Ray Data 仪表板,在那里您可以查看每个 Ray Data operator 的吞吐量和状态。
总结#
在本 notebook 中,您将
使用 Ray Train 和 Ray Data 在具有多个 GPU worker 的 Ray Cluster 上训练了 PyTorch VisionTransformer 模型
验证了速度得到提升,但准确率未受影响
通过各种仪表板深入了解了您的分布式训练和数据预处理工作负载