使用 Ray Train、PyTorch Lightning 和 FSDP 微调 dolly-v2-7b#

在此示例中,我们将演示如何使用 Ray Train 微调 dolly-v2-7b 模型。dolly-v2-7b 是由 Databricks 创建的一个具有 70 亿参数的因果语言模型,源自 EleutherAI 的 Pythia-6.9b,并在一个 约 1.5 万条记录的指令语料库上进行了微调。
我们将预训练模型从 HuggingFace 模型中心加载到 LightningModule 中,并借助 Ray TorchTrainer 在 16 个 T4 GPU 上启动 FSDP 微调作业。正如本例所示,以类似的方式微调其他大型语言模型也很简单。
在开始此示例之前,强烈建议您阅读 Ray Train 关键概念 和 Ray Data 快速入门。
设置 Ray 集群#
在此示例中,我们使用一个 Ray 集群,其中包含一个 g4dn.8xlarge 头节点和 15 个 g4dn.4xlarge 工作节点。每个实例都配备一个 Tesla T4 GPU(16GiB 内存)。
我们定义一个 runtime_env 以在每个节点上安装必要的 Python 库。如果您的 worker 基础镜像中已安装所有必需的包,则可以跳过此步骤。我们使用 lightning==2.0.2 和 transformers==4.29.2 测试了此示例。
import ray
ray.init(
runtime_env={
"pip": [
"datasets",
"evaluate",
"transformers>=4.26.0",
"torch>=1.12.0",
"lightning>=2.0",
]
}
)
MODEL_NAME = "databricks/dolly-v2-7b"
准备你的数据#
我们使用 tiny_shakespeare 进行微调,该数据集包含莎士比亚各种戏剧中的 40,000 行文本。该数据集曾在 Andrej Karpathy 的博客文章 《循环神经网络的不可思议的有效性》中出现。
数据集样本
BAPTISTA:
I know him well: you are welcome for his sake.
GREMIO:
Saving your tale, Petruchio, I pray,
Let us, that are poor petitioners, speak too:
Baccare! you are marvellous forward.
PETRUCHIO:
O, pardon me, Signior Gremio; I would fain be doing.
在这里,我们采用了与另一个演示类似的预处理逻辑:使用 Ray Train 和 DeepSpeed 微调 GPT-J-6B。
import ray
import pandas as pd
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
def split_text(batch: pd.DataFrame) -> pd.DataFrame:
text = list(batch["text"])
flat_text = "".join(text)
split_text = [
x.strip()
for x in flat_text.split("\n")
if x.strip() and not x.strip()[-1] == ":"
]
return pd.DataFrame(split_text, columns=["text"])
def tokenize(batch: pd.DataFrame) -> dict:
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, padding_side="left")
tokenizer.pad_token = tokenizer.eos_token
ret = tokenizer(
list(batch["text"]),
truncation=True,
max_length=256,
padding="max_length",
return_tensors="np",
)
ret["labels"] = ret["input_ids"].copy()
return dict(ret)
hf_dataset = load_dataset("tiny_shakespeare")
train_ds = ray.data.from_huggingface(hf_dataset["train"])
我们首先将原始段落分割成多个句子,然后对它们进行 tokenization(分词)。以下是一些样本
# First split the dataset into multiple sentences.
train_ds = train_ds.map_batches(split_text, batch_format="pandas")
train_ds.take(10)
2023-08-30 11:03:12,182 INFO dataset.py:2380 -- Tip: Use `take_batch()` instead of `take() / show()` to return records in pandas or numpy batch format.
2023-08-30 11:03:12,185 INFO streaming_executor.py:93 -- Executing DAG InputDataBuffer[Input] -> TaskPoolMapOperator[MapBatches(split_text)] -> LimitOperator[limit=10]
2023-08-30 11:03:12,186 INFO streaming_executor.py:94 -- Execution config: ExecutionOptions(resource_limits=ExecutionResources(cpu=None, gpu=None, object_store_memory=None), locality_with_output=False, preserve_order=False, actor_locality_enabled=True, verbose_progress=False)
2023-08-30 11:03:12,187 INFO streaming_executor.py:96 -- Tip: For detailed progress reporting, run `ray.data.DataContext.get_current().execution_options.verbose_progress = True`
[{'text': 'Before we proceed any further, hear me speak.'},
{'text': 'Speak, speak.'},
{'text': 'You are all resolved rather to die than to famish?'},
{'text': 'Resolved. resolved.'},
{'text': 'First, you know Caius Marcius is chief enemy to the people.'},
{'text': "We know't, we know't."},
{'text': "Let us kill him, and we'll have corn at our own price."},
{'text': "Is't a verdict?"},
{'text': "No more talking on't; let it be done: away, away!"},
{'text': 'One word, good citizens.'}]
# Then tokenize the dataset.
train_ds = train_ds.map_batches(tokenize, batch_format="pandas")
定义你的 Lightning 模型#
在此示例中,我们使用 dolly-v2-7b 模型进行微调。这是一个在 Databricks 机器学习平台训练的遵循指令的大语言模型,并获得商业用途许可。我们将模型权重从 Huggingface Model Hub 加载并封装到 pl.LightningModule 中。
注意
确保将 FSDP 包装后的模型参数 self.trainer.model.parameters() 传递给优化器,而不是 self.model.parameters()。
import torch
import lightning.pytorch as pl
class DollyV2Model(pl.LightningModule):
def __init__(self, lr=2e-5, eps=1e-8):
super().__init__()
self.save_hyperparameters()
self.lr = lr
self.eps = eps
self.model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
def forward(self, batch):
outputs = self.model(
batch["input_ids"],
attention_mask=batch["attention_mask"],
labels=batch["labels"]
)
return outputs.loss
def training_step(self, batch, batch_idx):
loss = self.forward(batch)
self.log("train_loss", loss, prog_bar=True, on_step=True)
return loss
def configure_optimizers(self):
if self.global_rank == 0:
print(self.trainer.model)
return torch.optim.AdamW(self.trainer.model.parameters(), lr=self.lr, eps=self.eps)
配置你的 FSDP 策略#
由于 dolly-v2-7b 是一个相对较大的模型,它无法完全适应单个商用 GPU。在此示例中,我们使用 FSDP 策略将模型参数分片到多个 worker 上。这使我们能够避免 GPU 内存不足的问题并支持更大的全局 batch size。
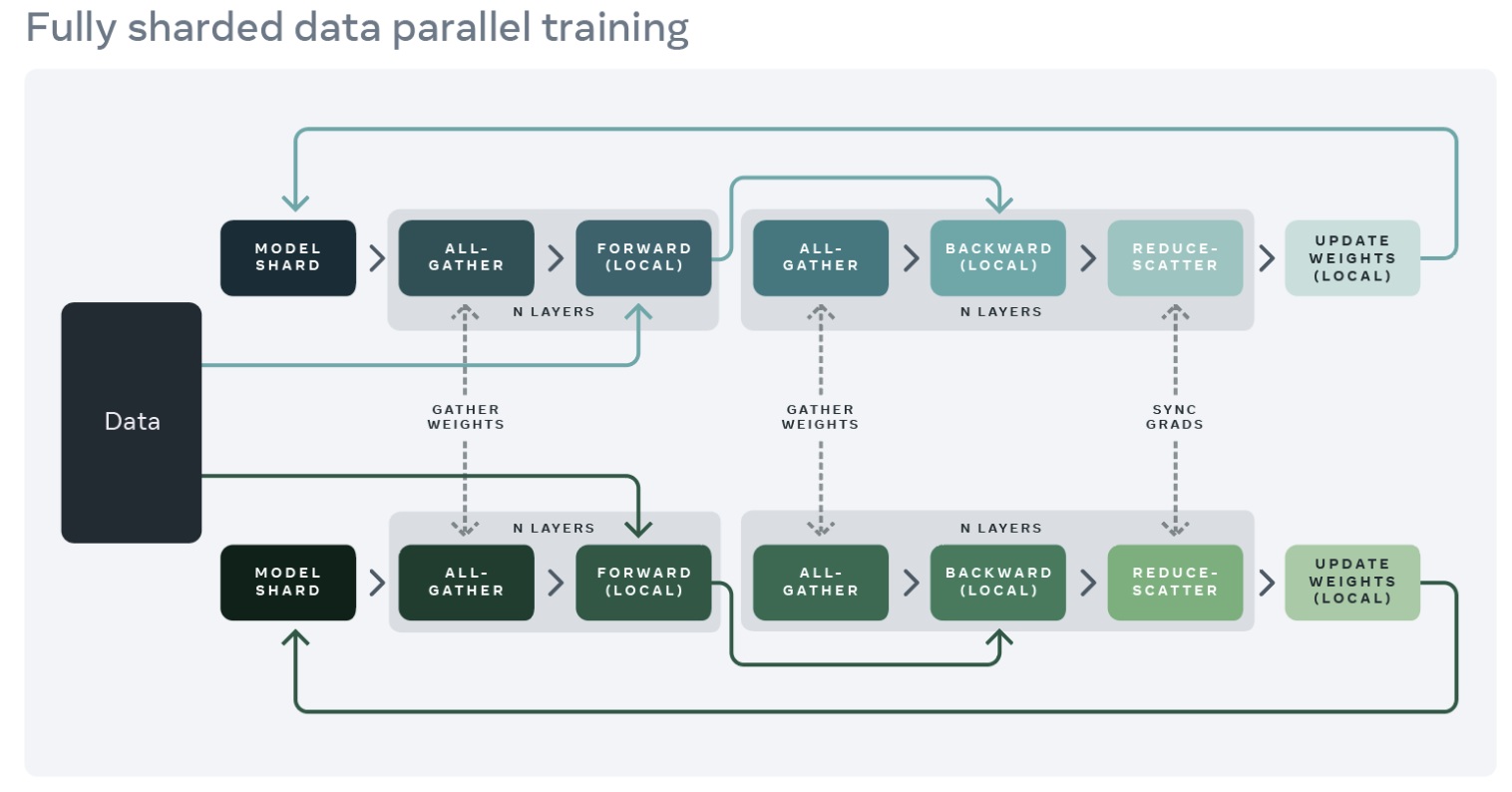 图片来源:Fully Sharded Data Parallel: faster AI training with fewer GPUs
图片来源:Fully Sharded Data Parallel: faster AI training with fewer GPUs
注意
FSDP 是一种数据并行类型,它将模型参数、优化器状态和梯度分片到 DDP 排名中。这受到 Xu 等人的工作以及 DeepSpeed 的 ZeRO Stage 3 的启发。您可以参考以下博客获取更多信息
要开始使用 Lightning 的 FSDPStrategy 进行训练,您只需使用相同的初始化参数创建一个 RayFSDPStrategy。
import functools
import lightning.pytorch as pl
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from torch.distributed.fsdp import ShardingStrategy, BackwardPrefetch
from transformers.models.gpt_neox.modeling_gpt_neox import GPTNeoXLayer
from ray.train.lightning import RayFSDPStrategy
# Define the model sharding policy:
# Wrap every GPTNeoXLayer as its own FSDP instance
auto_wrap_policy = functools.partial(
transformer_auto_wrap_policy,
transformer_layer_cls = {GPTNeoXLayer}
)
fsdp_strategy = RayFSDPStrategy(
sharding_strategy=ShardingStrategy.FULL_SHARD,
backward_prefetch=BackwardPrefetch.BACKWARD_PRE,
forward_prefetch=True,
auto_wrap_policy=auto_wrap_policy,
limit_all_gathers=True,
activation_checkpointing=[GPTNeoXLayer],
)
提示
FSDP 配置的一些提示
sharding_strategy:ShardingStrategy.NO_SHARD:参数、梯度和优化器状态不进行分片。类似于 DDP。ShardingStrategy.SHARD_GRAD_OP:计算过程中对梯度和优化器状态进行分片,此外,在计算之外对参数进行分片。类似于 ZeRO stage-2。ShardingStrategy.FULL_SHARD:参数、梯度和优化器状态都进行分片。在所有 3 个选项中,其 GRAM 使用量最低。类似于 ZeRO stage-3。
auto_wrap_policy:模型层通常以分层方式使用 FSDP 进行包装。这意味着在正向或反向计算期间,只需要将单个 FSDP 实例中的层的所有参数聚合到单个设备上。
使用
transformer_auto_wrap_policy自动将每个 Transformer Block 包装成一个单独的 FSDP 实例。
backward_prefetch和forward_prefetch在执行当前正向/反向传播时重叠后续的 all-gather 操作。这可以提高吞吐量,但可能会略微增加峰值内存使用量。
使用 Ray TorchTrainer 微调#
Ray TorchTrainer 允许您在多个节点上扩展 PyTorch Lightning 训练工作负载。有关更多详细信息,请参阅配置规模和 GPU。
num_workers = 16
batch_size_per_worker = 10
此外,请记住定义一个用于保存和报告检查点的 Lightning 回调。Ray Train 提供了一个简单的实现,RayTrainReportCallback(),它会在每个训练 epoch 结束时将您的检查点和指标持久化到远程存储中。
注意,您还可以实现自己的报告回调,其中包含自定义逻辑,例如保存自定义检查点文件或以不同的频率报告。
from ray.train import Checkpoint
from ray.train.lightning import RayLightningEnvironment, RayTrainReportCallback, prepare_trainer
# Training function for each worker
def train_func(config):
lr = config["lr"]
eps = config["eps"]
strategy = config["strategy"]
batch_size_per_worker = config["batch_size_per_worker"]
# Model
model = DollyV2Model(lr=lr, eps=eps)
# Ray Data Ingestion
train_ds = ray.train.get_dataset_shard("train")
train_dataloader = train_ds.iter_torch_batches(batch_size=batch_size_per_worker)
# Lightning Trainer
trainer = pl.Trainer(
max_epochs=1,
devices="auto",
accelerator="auto",
precision="16-mixed",
strategy=strategy,
plugins=[RayLightningEnvironment()],
callbacks=[RayTrainReportCallback()],
enable_checkpointing=False,
)
trainer = prepare_trainer(trainer)
trainer.fit(model, train_dataloaders=train_dataloader)
注意
由于此示例在多个节点上运行,我们需要将检查点和其他输出持久化到外部存储中,以便在训练完成后进行访问。您应该设置云存储或 NFS,然后将 storage_path 替换为您自己的云存储桶 URI 或 NFS 路径。
有关更多详细信息,请参阅存储指南。
storage_path="s3://your-bucket-here" # TODO: Set up cloud storage
# storage_path="/mnt/path/to/nfs" # TODO: Alternatively, set up NFS
from ray.train.torch import TorchTrainer
from ray.train import RunConfig, ScalingConfig, CheckpointConfig
# Save Ray Train checkpoints according to the performance on validation set
run_config = RunConfig(
name="finetune_dolly-v2-7b",
storage_path=storage_path,
checkpoint_config=CheckpointConfig(num_to_keep=1),
)
# Scale the FSDP training workload across 16 GPUs
# You can change this config based on your compute resources.
scaling_config = ScalingConfig(
num_workers=num_workers, use_gpu=True, trainer_resources={"memory": 100 * 1024 ** 3}
)
# Configuration to pass into train_func
train_config = {
"lr": 2e-5,
"eps": 1e-8,
"strategy": fsdp_strategy,
"batch_size_per_worker": 10
}
# Define a TorchTrainer and launch you training workload
ray_trainer = TorchTrainer(
train_func,
train_loop_config=train_config,
run_config=run_config,
scaling_config=scaling_config,
datasets={"train": train_ds},
)
result = ray_trainer.fit()
result
Tune 状态
| 当前时间 | 2023-08-30 11:51:22 |
| 运行时间 | 00:47:57.19 |
| 内存 | 39.3/124.3 GiB |
系统信息
使用 FIFO 调度算法。逻辑资源使用情况:193.0/272 CPUs,16.0/16 GPUs (0.0/16.0 accelerator_type:None)
Trial 状态
| Trial 名称 | 状态 | loc | iter | 总时间 (秒) | train_loss | epoch | step |
|---|---|---|---|---|---|---|---|
| TorchTrainer_839b5_00000 | TERMINATED | 10.0.23.226:66074 | 1 | 2868.15 | 0.176025 | 0 | 135 |
(TrainTrainable pid=66074) StorageContext on SESSION (rank=None):
(TrainTrainable pid=66074) StorageContext<
(TrainTrainable pid=66074) storage_path=/mnt/cluster_storage
(TrainTrainable pid=66074) storage_local_path=/home/ray/ray_results
(TrainTrainable pid=66074) storage_filesystem=<pyarrow._fs.LocalFileSystem object at 0x7f8b0a2cd7f0>
(TrainTrainable pid=66074) storage_fs_path=/mnt/cluster_storage
(TrainTrainable pid=66074) experiment_dir_name=finetune_dolly-v2-7b
(TrainTrainable pid=66074) trial_dir_name=TorchTrainer_839b5_00000_0_2023-08-30_11-03-25
(TrainTrainable pid=66074) current_checkpoint_index=0
(TrainTrainable pid=66074) >
(TorchTrainer pid=66074) Starting distributed worker processes: ['66181 (10.0.23.226)', '14250 (10.0.40.16)', '13932 (10.0.2.17)', '13832 (10.0.41.56)', '14288 (10.0.53.250)', '13909 (10.0.41.152)', '13803 (10.0.14.94)', '47214 (10.0.44.99)', '13836 (10.0.58.27)', '13838 (10.0.58.206)', '13755 (10.0.62.244)', '13828 (10.0.9.99)', '13771 (10.0.43.35)', '13726 (10.0.59.245)', '13829 (10.0.58.178)', '13861 (10.0.46.116)']
(RayTrainWorker pid=66181) Setting up process group for: env:// [rank=0, world_size=16]
(RayTrainWorker pid=66181) StorageContext on SESSION (rank=0):
(RayTrainWorker pid=14250, ip=10.0.40.16) StorageContext< [repeated 2x across cluster] (Ray deduplicates logs by default. Set RAY_DEDUP_LOGS=0 to disable log deduplication, or see https://docs.rayai.org.cn/en/master/ray-observability/ray-logging.html#log-deduplication for more options.)
(RayTrainWorker pid=14250, ip=10.0.40.16) storage_path=/mnt/cluster_storage [repeated 2x across cluster]
(RayTrainWorker pid=14250, ip=10.0.40.16) storage_local_path=/home/ray/ray_results [repeated 2x across cluster]
(RayTrainWorker pid=14250, ip=10.0.40.16) storage_filesystem=<pyarrow._fs.LocalFileSystem object at 0x7ff145c40b30> [repeated 2x across cluster]
(RayTrainWorker pid=14250, ip=10.0.40.16) storage_fs_path=/mnt/cluster_storage [repeated 2x across cluster]
(RayTrainWorker pid=14250, ip=10.0.40.16) current_checkpoint_index=0 [repeated 6x across cluster]
(RayTrainWorker pid=14250, ip=10.0.40.16) > [repeated 2x across cluster]
(SplitCoordinator pid=66292) Auto configuring locality_with_output=['5ed99d043a52f67deb150f34202c09b77bd37409502ebf6e581b0544', '8efe8198d7c04d45714ae757f298c316117405f3a8b25b87a71e0d9e', 'e3754d1e1017e68dd919b35d35ea62ed7b005ad96452f371721fc9fa', '8bd0f431ab3733c4b423c1d50db06460e3c210de47355b3b4d215c31', '73a8b9377fe9531a84eaa7b30c966fbb11bc36aff070d55c8f7acd1a', 'ef922c93f3b2fc93ebe5a521426d24fb8aae7e13c65f9fbd106aea2a', '5249cff3eab41121f840c17a79e6a3cd0af0f059def707a39e055fcf', '042b668e5553a589a4f6693c45deee0abe57a1d754812172af425acb', '9ed138bfe1f9c7dca484ee08d8311806389adb3af7a76566a6f4dfaa', '7e2fcb5dfe4ab1b572d87257f9e13bbc22b33ba968b1e67a79505589', '39b1ef4da8493a22e321a1ea9dd13387f50d9a6e2d2fbad58ad5fe9c', '9484193409a5346c0838a4a19a0a08eec122477682ea1cb0ad3e305a', '0158084645ec305bdd2ab11a6f35c44ad206405ca810e65f24b09398', 'fe5b11633900d1c437b2e3ee4ea44c18cf68f3dece546537d2090c63', '573645f42162f531a66d20776a95ba05102fae8e4b8090d48b94b233', '47e317ad5d0eb94cabb78871541160763283629d0d3f3b77b69521ae']
(RayTrainWorker pid=66181) Using 16bit Automatic Mixed Precision (AMP)
(RayTrainWorker pid=66181) GPU available: True (cuda), used: True
(RayTrainWorker pid=66181) TPU available: False, using: 0 TPU cores
(RayTrainWorker pid=66181) IPU available: False, using: 0 IPUs
(RayTrainWorker pid=66181) HPU available: False, using: 0 HPUs
(RayTrainWorker pid=13726, ip=10.0.59.245) StorageContext on SESSION (rank=13): [repeated 15x across cluster]
(RayTrainWorker pid=13726, ip=10.0.59.245) StorageContext< [repeated 14x across cluster]
(RayTrainWorker pid=13726, ip=10.0.59.245) storage_path=/mnt/cluster_storage [repeated 14x across cluster]
(RayTrainWorker pid=13726, ip=10.0.59.245) storage_local_path=/home/ray/ray_results [repeated 14x across cluster]
(RayTrainWorker pid=13726, ip=10.0.59.245) storage_filesystem=<pyarrow._fs.LocalFileSystem object at 0x7fc9841d7a70> [repeated 14x across cluster]
(RayTrainWorker pid=13726, ip=10.0.59.245) storage_fs_path=/mnt/cluster_storage [repeated 14x across cluster]
(RayTrainWorker pid=13726, ip=10.0.59.245) current_checkpoint_index=0 [repeated 42x across cluster]
(RayTrainWorker pid=13726, ip=10.0.59.245) > [repeated 14x across cluster]
(RayTrainWorker pid=66181) Missing logger folder: /home/ray/ray_results/finetune_dolly-v2-7b/TorchTrainer_839b5_00000_0_2023-08-30_11-03-25/lightning_logs
(RayTrainWorker pid=13832, ip=10.0.41.56) Using 16bit Automatic Mixed Precision (AMP)
(RayTrainWorker pid=13836, ip=10.0.58.27) Using 16bit Automatic Mixed Precision (AMP)
(RayTrainWorker pid=13832, ip=10.0.41.56) Missing logger folder: /home/ray/ray_results/finetune_dolly-v2-7b/TorchTrainer_839b5_00000_0_2023-08-30_11-03-25/lightning_logs
(RayTrainWorker pid=13726, ip=10.0.59.245) Using 16bit Automatic Mixed Precision (AMP) [repeated 13x across cluster]
(RayTrainWorker pid=47214, ip=10.0.44.99) Missing logger folder: /home/ray/ray_results/finetune_dolly-v2-7b/TorchTrainer_839b5_00000_0_2023-08-30_11-03-25/lightning_logs [repeated 13x across cluster]
(RayTrainWorker pid=13909, ip=10.0.41.152) LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
(RayTrainWorker pid=66181) FullyShardedDataParallel(
(RayTrainWorker pid=66181) (_fsdp_wrapped_module): _LightningModuleWrapperBase(
(RayTrainWorker pid=66181) (_forward_module): DollyV2Model(
(RayTrainWorker pid=66181) (model): GPTNeoXForCausalLM(
(RayTrainWorker pid=66181) (gpt_neox): GPTNeoXModel(
(RayTrainWorker pid=66181) (embed_in): Embedding(50280, 4096)
(RayTrainWorker pid=66181) (layers): ModuleList(
(RayTrainWorker pid=66181) (0-31): 32 x FullyShardedDataParallel(
(RayTrainWorker pid=66181) (_fsdp_wrapped_module): CheckpointWrapper(
(RayTrainWorker pid=66181) (_checkpoint_wrapped_module): GPTNeoXLayer(
(RayTrainWorker pid=66181) (input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(RayTrainWorker pid=66181) (post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(RayTrainWorker pid=66181) (attention): GPTNeoXAttention(
(RayTrainWorker pid=66181) (rotary_emb): RotaryEmbedding()
(RayTrainWorker pid=66181) (query_key_value): Linear(in_features=4096, out_features=12288, bias=True)
(RayTrainWorker pid=66181) (dense): Linear(in_features=4096, out_features=4096, bias=True)
(RayTrainWorker pid=66181) )
(RayTrainWorker pid=66181) (mlp): GPTNeoXMLP(
(RayTrainWorker pid=66181) (dense_h_to_4h): Linear(in_features=4096, out_features=16384, bias=True)
(RayTrainWorker pid=66181) (dense_4h_to_h): Linear(in_features=16384, out_features=4096, bias=True)
(RayTrainWorker pid=66181) (act): GELUActivation()
(RayTrainWorker pid=66181) )
(RayTrainWorker pid=66181) )
(RayTrainWorker pid=66181) )
(RayTrainWorker pid=66181) )
(RayTrainWorker pid=66181) )
(RayTrainWorker pid=66181) (final_layer_norm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(RayTrainWorker pid=66181) )
(RayTrainWorker pid=66181) (embed_out): Linear(in_features=4096, out_features=50280, bias=False)
(RayTrainWorker pid=66181) )
(RayTrainWorker pid=66181) )
(RayTrainWorker pid=66181) )
(RayTrainWorker pid=66181) )
Epoch 0: 0%| | 0/134 [00:00<?, ?it/s]
(RayTrainWorker pid=66181)
(RayTrainWorker pid=66181) | Name | Type | Params
(RayTrainWorker pid=66181) ---------------------------------------------
(RayTrainWorker pid=66181) 0 | model | GPTNeoXForCausalLM | 402 M
(RayTrainWorker pid=66181) ---------------------------------------------
(RayTrainWorker pid=66181) 402 M Trainable params
(RayTrainWorker pid=66181) 0 Non-trainable params
(RayTrainWorker pid=66181) 402 M Total params
(RayTrainWorker pid=66181) 1,611.039 Total estimated model params size (MB)
(RayTrainWorker pid=13726, ip=10.0.59.245) Missing logger folder: /home/ray/ray_results/finetune_dolly-v2-7b/TorchTrainer_839b5_00000_0_2023-08-30_11-03-25/lightning_logs
(RayTrainWorker pid=13803, ip=10.0.14.94) LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0] [repeated 15x across cluster]
(SplitCoordinator pid=66292) Executing DAG InputDataBuffer[Input] -> TaskPoolMapOperator[MapBatches(split_text)->MapBatches(tokenize)] -> OutputSplitter[split(16, equal=True)]
(SplitCoordinator pid=66292) Execution config: ExecutionOptions(resource_limits=ExecutionResources(cpu=None, gpu=None, object_store_memory=2000000000.0), locality_with_output=['5ed99d043a52f67deb150f34202c09b77bd37409502ebf6e581b0544', '8efe8198d7c04d45714ae757f298c316117405f3a8b25b87a71e0d9e', 'e3754d1e1017e68dd919b35d35ea62ed7b005ad96452f371721fc9fa', '8bd0f431ab3733c4b423c1d50db06460e3c210de47355b3b4d215c31', '73a8b9377fe9531a84eaa7b30c966fbb11bc36aff070d55c8f7acd1a', 'ef922c93f3b2fc93ebe5a521426d24fb8aae7e13c65f9fbd106aea2a', '5249cff3eab41121f840c17a79e6a3cd0af0f059def707a39e055fcf', '042b668e5553a589a4f6693c45deee0abe57a1d754812172af425acb', '9ed138bfe1f9c7dca484ee08d8311806389adb3af7a76566a6f4dfaa', '7e2fcb5dfe4ab1b572d87257f9e13bbc22b33ba968b1e67a79505589', '39b1ef4da8493a22e321a1ea9dd13387f50d9a6e2d2fbad58ad5fe9c', '9484193409a5346c0838a4a19a0a08eec122477682ea1cb0ad3e305a', '0158084645ec305bdd2ab11a6f35c44ad206405ca810e65f24b09398', 'fe5b11633900d1c437b2e3ee4ea44c18cf68f3dece546537d2090c63', '573645f42162f531a66d20776a95ba05102fae8e4b8090d48b94b233', '47e317ad5d0eb94cabb78871541160763283629d0d3f3b77b69521ae'], preserve_order=False, actor_locality_enabled=True, verbose_progress=False)
(SplitCoordinator pid=66292) Tip: For detailed progress reporting, run `ray.data.DataContext.get_current().execution_options.verbose_progress = True`
Epoch 0: 1%| | 1/134 [00:25<57:20, 25.87s/it, v_num=0, train_loss=12.90]
Epoch 0: 1%|▏ | 2/134 [00:43<47:24, 21.55s/it, v_num=0, train_loss=12.50]
Epoch 0: 2%|▏ | 3/134 [01:00<43:55, 20.12s/it, v_num=0, train_loss=12.50]
Epoch 0: 3%|▎ | 4/134 [01:21<44:23, 20.49s/it, v_num=0, train_loss=12.50]
Epoch 0: 4%|▎ | 5/134 [01:39<42:42, 19.87s/it, v_num=0, train_loss=12.50]
Epoch 0: 4%|▍ | 6/134 [01:56<41:29, 19.45s/it, v_num=0, train_loss=12.50]
(autoscaler +4m7s) Tip: use `ray status` to view detailed cluster status. To disable these messages, set RAY_SCHEDULER_EVENTS=0.
(autoscaler +4m7s) [workspace snapshot] New snapshot created successfully (size: 448.90 KB).
Epoch 0: 5%|▌ | 7/134 [02:13<40:30, 19.14s/it, v_num=0, train_loss=12.50]
Epoch 0: 6%|▌ | 8/134 [02:31<39:43, 18.92s/it, v_num=0, train_loss=12.50]
Epoch 0: 7%|▋ | 9/134 [02:48<39:04, 18.76s/it, v_num=0, train_loss=12.50]
Epoch 0: 7%|▋ | 9/134 [02:48<39:06, 18.77s/it, v_num=0, train_loss=12.50]
Epoch 0: 7%|▋ | 10/134 [03:06<38:33, 18.66s/it, v_num=0, train_loss=12.50]
Epoch 0: 7%|▋ | 10/134 [03:06<38:35, 18.67s/it, v_num=0, train_loss=0.587]
Epoch 0: 8%|▊ | 11/134 [03:24<38:02, 18.56s/it, v_num=0, train_loss=0.587]
Epoch 0: 8%|▊ | 11/134 [03:24<38:04, 18.57s/it, v_num=0, train_loss=0.600]
Epoch 0: 9%|▉ | 12/134 [03:41<37:34, 18.48s/it, v_num=0, train_loss=0.600]
Epoch 0: 9%|▉ | 12/134 [03:41<37:36, 18.49s/it, v_num=0, train_loss=0.590]
Epoch 0: 10%|▉ | 13/134 [03:59<37:08, 18.41s/it, v_num=0, train_loss=0.590]
Epoch 0: 10%|▉ | 13/134 [03:59<37:09, 18.43s/it, v_num=0, train_loss=0.591]
Epoch 0: 10%|█ | 14/134 [04:17<36:44, 18.37s/it, v_num=0, train_loss=0.591]
Epoch 0: 10%|█ | 14/134 [04:17<36:45, 18.38s/it, v_num=0, train_loss=0.590]
Epoch 0: 11%|█ | 15/134 [04:34<36:19, 18.32s/it, v_num=0, train_loss=0.590]
Epoch 0: 11%|█ | 15/134 [04:34<36:21, 18.33s/it, v_num=0, train_loss=0.551]
Epoch 0: 12%|█▏ | 16/134 [04:52<35:57, 18.29s/it, v_num=0, train_loss=0.551]
Epoch 0: 12%|█▏ | 16/134 [04:52<35:58, 18.29s/it, v_num=0, train_loss=0.521]
Epoch 0: 13%|█▎ | 17/134 [05:10<35:35, 18.25s/it, v_num=0, train_loss=0.521]
Epoch 0: 13%|█▎ | 17/134 [05:10<35:36, 18.26s/it, v_num=0, train_loss=0.522]
Epoch 0: 13%|█▎ | 18/134 [05:28<35:14, 18.23s/it, v_num=0, train_loss=0.522]
Epoch 0: 13%|█▎ | 18/134 [05:28<35:15, 18.23s/it, v_num=0, train_loss=0.518]
Epoch 0: 14%|█▍ | 19/134 [05:45<34:52, 18.19s/it, v_num=0, train_loss=0.518]
Epoch 0: 14%|█▍ | 19/134 [05:45<34:52, 18.20s/it, v_num=0, train_loss=0.476]
Epoch 0: 15%|█▍ | 20/134 [06:03<34:30, 18.16s/it, v_num=0, train_loss=0.476]
Epoch 0: 15%|█▍ | 20/134 [06:03<34:31, 18.17s/it, v_num=0, train_loss=0.457]
Epoch 0: 16%|█▌ | 21/134 [06:23<34:23, 18.26s/it, v_num=0, train_loss=0.457]
Epoch 0: 16%|█▌ | 21/134 [06:23<34:23, 18.27s/it, v_num=0, train_loss=0.476]
Epoch 0: 16%|█▋ | 22/134 [06:42<34:09, 18.30s/it, v_num=0, train_loss=0.476]
Epoch 0: 16%|█▋ | 22/134 [06:42<34:10, 18.31s/it, v_num=0, train_loss=0.447]
(autoscaler +9m7s) [workspace snapshot] New snapshot created successfully (size: 451.39 KB).
Epoch 0: 17%|█▋ | 23/134 [07:00<33:49, 18.28s/it, v_num=0, train_loss=0.447]
Epoch 0: 17%|█▋ | 23/134 [07:00<33:49, 18.29s/it, v_num=0, train_loss=0.412]
Epoch 0: 18%|█▊ | 24/134 [07:19<33:33, 18.31s/it, v_num=0, train_loss=0.412]
Epoch 0: 18%|█▊ | 24/134 [07:19<33:34, 18.31s/it, v_num=0, train_loss=0.385]
Epoch 0: 19%|█▊ | 25/134 [07:37<33:13, 18.29s/it, v_num=0, train_loss=0.385]
Epoch 0: 19%|█▊ | 25/134 [07:37<33:13, 18.29s/it, v_num=0, train_loss=0.384]
Epoch 0: 19%|█▉ | 26/134 [07:54<32:52, 18.27s/it, v_num=0, train_loss=0.384]
Epoch 0: 19%|█▉ | 26/134 [07:55<32:53, 18.27s/it, v_num=0, train_loss=0.406]
Epoch 0: 20%|██ | 27/134 [08:12<32:32, 18.25s/it, v_num=0, train_loss=0.406]
Epoch 0: 20%|██ | 27/134 [08:12<32:32, 18.25s/it, v_num=0, train_loss=0.380]
Epoch 0: 21%|██ | 28/134 [08:30<32:12, 18.23s/it, v_num=0, train_loss=0.380]
Epoch 0: 21%|██ | 28/134 [08:30<32:12, 18.23s/it, v_num=0, train_loss=0.405]
Epoch 0: 22%|██▏ | 29/134 [08:48<31:52, 18.21s/it, v_num=0, train_loss=0.405]
Epoch 0: 22%|██▏ | 29/134 [08:48<31:52, 18.22s/it, v_num=0, train_loss=0.355]
Epoch 0: 22%|██▏ | 30/134 [09:06<31:32, 18.20s/it, v_num=0, train_loss=0.355]
Epoch 0: 22%|██▏ | 30/134 [09:06<31:33, 18.21s/it, v_num=0, train_loss=0.376]
Epoch 0: 23%|██▎ | 31/134 [09:23<31:12, 18.18s/it, v_num=0, train_loss=0.376]
Epoch 0: 23%|██▎ | 31/134 [09:23<31:13, 18.19s/it, v_num=0, train_loss=0.330]
Epoch 0: 24%|██▍ | 32/134 [09:41<30:53, 18.17s/it, v_num=0, train_loss=0.330]
Epoch 0: 24%|██▍ | 32/134 [09:41<30:53, 18.17s/it, v_num=0, train_loss=0.359]
Epoch 0: 25%|██▍ | 33/134 [09:59<30:33, 18.15s/it, v_num=0, train_loss=0.359]
Epoch 0: 25%|██▍ | 33/134 [09:59<30:33, 18.16s/it, v_num=0, train_loss=0.319]
Epoch 0: 25%|██▌ | 34/134 [10:16<30:14, 18.14s/it, v_num=0, train_loss=0.319]
Epoch 0: 25%|██▌ | 34/134 [10:16<30:14, 18.15s/it, v_num=0, train_loss=0.359]
Epoch 0: 26%|██▌ | 35/134 [10:34<29:54, 18.13s/it, v_num=0, train_loss=0.359]
Epoch 0: 26%|██▌ | 35/134 [10:34<29:54, 18.13s/it, v_num=0, train_loss=0.405]
Epoch 0: 27%|██▋ | 36/134 [10:52<29:35, 18.12s/it, v_num=0, train_loss=0.405]
Epoch 0: 27%|██▋ | 36/134 [10:52<29:35, 18.12s/it, v_num=0, train_loss=0.362]
Epoch 0: 28%|██▊ | 37/134 [11:09<29:16, 18.10s/it, v_num=0, train_loss=0.362]
Epoch 0: 28%|██▊ | 37/134 [11:10<29:16, 18.11s/it, v_num=0, train_loss=0.343]
Epoch 0: 28%|██▊ | 38/134 [11:27<28:56, 18.09s/it, v_num=0, train_loss=0.343]
Epoch 0: 28%|██▊ | 38/134 [11:27<28:57, 18.10s/it, v_num=0, train_loss=0.335]
Epoch 0: 29%|██▉ | 39/134 [11:45<28:38, 18.08s/it, v_num=0, train_loss=0.335]
Epoch 0: 29%|██▉ | 39/134 [11:45<28:38, 18.09s/it, v_num=0, train_loss=0.325]
(autoscaler +14m8s) [workspace snapshot] New snapshot created successfully (size: 455.47 KB).
Epoch 0: 30%|██▉ | 40/134 [12:03<28:19, 18.08s/it, v_num=0, train_loss=0.325]
Epoch 0: 30%|██▉ | 40/134 [12:03<28:19, 18.08s/it, v_num=0, train_loss=0.344]
Epoch 0: 31%|███ | 41/134 [12:20<27:59, 18.06s/it, v_num=0, train_loss=0.344]
Epoch 0: 31%|███ | 41/134 [12:20<28:00, 18.06s/it, v_num=0, train_loss=0.312]
Epoch 0: 31%|███▏ | 42/134 [12:38<27:40, 18.05s/it, v_num=0, train_loss=0.312]
Epoch 0: 31%|███▏ | 42/134 [12:38<27:40, 18.05s/it, v_num=0, train_loss=0.338]
Epoch 0: 32%|███▏ | 43/134 [12:55<27:21, 18.04s/it, v_num=0, train_loss=0.338]
Epoch 0: 32%|███▏ | 43/134 [12:55<27:21, 18.04s/it, v_num=0, train_loss=0.315]
Epoch 0: 33%|███▎ | 44/134 [13:13<27:02, 18.03s/it, v_num=0, train_loss=0.315]
Epoch 0: 33%|███▎ | 44/134 [13:13<27:02, 18.03s/it, v_num=0, train_loss=0.330]
Epoch 0: 34%|███▎ | 45/134 [13:31<26:44, 18.02s/it, v_num=0, train_loss=0.330]
Epoch 0: 34%|███▎ | 45/134 [13:31<26:44, 18.03s/it, v_num=0, train_loss=0.253]
Epoch 0: 34%|███▍ | 46/134 [13:48<26:25, 18.02s/it, v_num=0, train_loss=0.253]
Epoch 0: 34%|███▍ | 46/134 [13:49<26:25, 18.02s/it, v_num=0, train_loss=0.310]
Epoch 0: 35%|███▌ | 47/134 [14:06<26:07, 18.01s/it, v_num=0, train_loss=0.310]
Epoch 0: 35%|███▌ | 47/134 [14:06<26:07, 18.01s/it, v_num=0, train_loss=0.294]
Epoch 0: 36%|███▌ | 48/134 [14:24<25:48, 18.01s/it, v_num=0, train_loss=0.294]
Epoch 0: 36%|███▌ | 48/134 [14:24<25:48, 18.01s/it, v_num=0, train_loss=0.302]
Epoch 0: 37%|███▋ | 49/134 [14:41<25:29, 18.00s/it, v_num=0, train_loss=0.302]
Epoch 0: 37%|███▋ | 49/134 [14:42<25:30, 18.00s/it, v_num=0, train_loss=0.325]
Epoch 0: 37%|███▋ | 50/134 [14:59<25:11, 17.99s/it, v_num=0, train_loss=0.325]
Epoch 0: 37%|███▋ | 50/134 [14:59<25:11, 18.00s/it, v_num=0, train_loss=0.250]
Epoch 0: 38%|███▊ | 51/134 [15:17<24:53, 17.99s/it, v_num=0, train_loss=0.250]
Epoch 0: 38%|███▊ | 51/134 [15:17<24:53, 17.99s/it, v_num=0, train_loss=0.291]
Epoch 0: 39%|███▉ | 52/134 [15:34<24:34, 17.98s/it, v_num=0, train_loss=0.291]
Epoch 0: 39%|███▉ | 52/134 [15:35<24:34, 17.98s/it, v_num=0, train_loss=0.261]
Epoch 0: 40%|███▉ | 53/134 [15:52<24:15, 17.98s/it, v_num=0, train_loss=0.261]
Epoch 0: 40%|███▉ | 53/134 [15:52<24:16, 17.98s/it, v_num=0, train_loss=0.292]
Epoch 0: 40%|████ | 54/134 [16:10<23:57, 17.97s/it, v_num=0, train_loss=0.292]
Epoch 0: 40%|████ | 54/134 [16:10<23:58, 17.98s/it, v_num=0, train_loss=0.245]
Epoch 0: 41%|████ | 55/134 [16:28<23:39, 17.97s/it, v_num=0, train_loss=0.245]
Epoch 0: 41%|████ | 55/134 [16:28<23:39, 17.97s/it, v_num=0, train_loss=0.265]
Epoch 0: 42%|████▏ | 56/134 [16:45<23:20, 17.96s/it, v_num=0, train_loss=0.265]
Epoch 0: 42%|████▏ | 56/134 [16:45<23:21, 17.96s/it, v_num=0, train_loss=0.233]
(autoscaler +19m8s) [workspace snapshot] New snapshot created successfully (size: 458.23 KB).
Epoch 0: 43%|████▎ | 57/134 [17:03<23:02, 17.96s/it, v_num=0, train_loss=0.233]
Epoch 0: 43%|████▎ | 57/134 [17:03<23:02, 17.96s/it, v_num=0, train_loss=0.228]
Epoch 0: 43%|████▎ | 58/134 [17:21<22:44, 17.96s/it, v_num=0, train_loss=0.228]
Epoch 0: 43%|████▎ | 58/134 [17:21<22:45, 17.96s/it, v_num=0, train_loss=0.222]
Epoch 0: 44%|████▍ | 59/134 [17:39<22:26, 17.96s/it, v_num=0, train_loss=0.222]
Epoch 0: 44%|████▍ | 59/134 [17:39<22:27, 17.96s/it, v_num=0, train_loss=0.240]
Epoch 0: 45%|████▍ | 60/134 [17:57<22:08, 17.96s/it, v_num=0, train_loss=0.240]
Epoch 0: 45%|████▍ | 60/134 [17:57<22:08, 17.96s/it, v_num=0, train_loss=0.220]
Epoch 0: 46%|████▌ | 61/134 [18:15<21:50, 17.95s/it, v_num=0, train_loss=0.220]
Epoch 0: 46%|████▌ | 61/134 [18:15<21:50, 17.95s/it, v_num=0, train_loss=0.235]
Epoch 0: 46%|████▋ | 62/134 [18:32<21:32, 17.95s/it, v_num=0, train_loss=0.235]
Epoch 0: 46%|████▋ | 62/134 [18:32<21:32, 17.95s/it, v_num=0, train_loss=0.230]
Epoch 0: 47%|████▋ | 63/134 [18:50<21:14, 17.95s/it, v_num=0, train_loss=0.230]
Epoch 0: 47%|████▋ | 63/134 [18:50<21:14, 17.95s/it, v_num=0, train_loss=0.247]
Epoch 0: 48%|████▊ | 64/134 [19:08<20:55, 17.94s/it, v_num=0, train_loss=0.247]
Epoch 0: 48%|████▊ | 64/134 [19:08<20:56, 17.94s/it, v_num=0, train_loss=0.243]
Epoch 0: 49%|████▊ | 65/134 [19:25<20:37, 17.94s/it, v_num=0, train_loss=0.243]
Epoch 0: 49%|████▊ | 65/134 [19:26<20:37, 17.94s/it, v_num=0, train_loss=0.233]
Epoch 0: 49%|████▉ | 66/134 [19:43<20:19, 17.93s/it, v_num=0, train_loss=0.233]
Epoch 0: 49%|████▉ | 66/134 [19:43<20:19, 17.94s/it, v_num=0, train_loss=0.253]
Epoch 0: 50%|█████ | 67/134 [20:01<20:01, 17.93s/it, v_num=0, train_loss=0.253]
Epoch 0: 50%|█████ | 67/134 [20:01<20:01, 17.93s/it, v_num=0, train_loss=0.235]
Epoch 0: 51%|█████ | 68/134 [20:19<19:43, 17.93s/it, v_num=0, train_loss=0.235]
Epoch 0: 51%|█████ | 68/134 [20:19<19:43, 17.93s/it, v_num=0, train_loss=0.270]
Epoch 0: 51%|█████▏ | 69/134 [20:37<19:25, 17.93s/it, v_num=0, train_loss=0.270]
Epoch 0: 51%|█████▏ | 69/134 [20:37<19:25, 17.93s/it, v_num=0, train_loss=0.220]
Epoch 0: 52%|█████▏ | 70/134 [20:54<19:07, 17.93s/it, v_num=0, train_loss=0.220]
Epoch 0: 52%|█████▏ | 70/134 [20:55<19:07, 17.93s/it, v_num=0, train_loss=0.249]
Epoch 0: 53%|█████▎ | 71/134 [21:12<18:49, 17.93s/it, v_num=0, train_loss=0.249]
Epoch 0: 53%|█████▎ | 71/134 [21:12<18:49, 17.93s/it, v_num=0, train_loss=0.231]
Epoch 0: 54%|█████▎ | 72/134 [21:30<18:31, 17.92s/it, v_num=0, train_loss=0.231]
Epoch 0: 54%|█████▎ | 72/134 [21:30<18:31, 17.92s/it, v_num=0, train_loss=0.206]
Epoch 0: 54%|█████▍ | 73/134 [21:48<18:13, 17.92s/it, v_num=0, train_loss=0.206]
Epoch 0: 54%|█████▍ | 73/134 [21:48<18:13, 17.92s/it, v_num=0, train_loss=0.266]
(autoscaler +24m8s) [workspace snapshot] New snapshot created successfully (size: 462.71 KB).
Epoch 0: 55%|█████▌ | 74/134 [22:05<17:55, 17.92s/it, v_num=0, train_loss=0.266]
Epoch 0: 55%|█████▌ | 74/134 [22:06<17:55, 17.92s/it, v_num=0, train_loss=0.252]
Epoch 0: 56%|█████▌ | 75/134 [22:23<17:37, 17.92s/it, v_num=0, train_loss=0.252]
Epoch 0: 56%|█████▌ | 75/134 [22:23<17:37, 17.92s/it, v_num=0, train_loss=0.218]
Epoch 0: 57%|█████▋ | 76/134 [22:41<17:19, 17.92s/it, v_num=0, train_loss=0.218]
Epoch 0: 57%|█████▋ | 76/134 [22:41<17:19, 17.92s/it, v_num=0, train_loss=0.195]
Epoch 0: 57%|█████▋ | 77/134 [22:59<17:01, 17.91s/it, v_num=0, train_loss=0.195]
Epoch 0: 57%|█████▋ | 77/134 [22:59<17:01, 17.91s/it, v_num=0, train_loss=0.210]
Epoch 0: 58%|█████▊ | 78/134 [23:17<16:42, 17.91s/it, v_num=0, train_loss=0.210]
Epoch 0: 58%|█████▊ | 78/134 [23:17<16:43, 17.91s/it, v_num=0, train_loss=0.198]
Epoch 0: 59%|█████▉ | 79/134 [23:34<16:24, 17.91s/it, v_num=0, train_loss=0.198]
Epoch 0: 59%|█████▉ | 79/134 [23:34<16:24, 17.91s/it, v_num=0, train_loss=0.232]
Epoch 0: 60%|█████▉ | 80/134 [23:52<16:06, 17.90s/it, v_num=0, train_loss=0.232]
Epoch 0: 60%|█████▉ | 80/134 [23:52<16:06, 17.90s/it, v_num=0, train_loss=0.267]
Epoch 0: 60%|██████ | 81/134 [24:09<15:48, 17.90s/it, v_num=0, train_loss=0.267]
Epoch 0: 60%|██████ | 81/134 [24:10<15:48, 17.90s/it, v_num=0, train_loss=0.244]
Epoch 0: 61%|██████ | 82/134 [24:27<15:30, 17.90s/it, v_num=0, train_loss=0.244]
Epoch 0: 61%|██████ | 82/134 [24:27<15:30, 17.90s/it, v_num=0, train_loss=0.173]
Epoch 0: 62%|██████▏ | 83/134 [24:45<15:12, 17.89s/it, v_num=0, train_loss=0.173]
Epoch 0: 62%|██████▏ | 83/134 [24:45<15:12, 17.89s/it, v_num=0, train_loss=0.225]
Epoch 0: 63%|██████▎ | 84/134 [25:02<14:54, 17.89s/it, v_num=0, train_loss=0.225]
Epoch 0: 63%|██████▎ | 84/134 [25:03<14:54, 17.89s/it, v_num=0, train_loss=0.231]
Epoch 0: 63%|██████▎ | 85/134 [25:20<14:36, 17.89s/it, v_num=0, train_loss=0.231]
Epoch 0: 63%|██████▎ | 85/134 [25:20<14:36, 17.89s/it, v_num=0, train_loss=0.235]
Epoch 0: 64%|██████▍ | 86/134 [25:38<14:18, 17.88s/it, v_num=0, train_loss=0.235]
Epoch 0: 64%|██████▍ | 86/134 [25:38<14:18, 17.89s/it, v_num=0, train_loss=0.257]
Epoch 0: 65%|██████▍ | 87/134 [25:55<14:00, 17.88s/it, v_num=0, train_loss=0.257]
Epoch 0: 65%|██████▍ | 87/134 [25:56<14:00, 17.89s/it, v_num=0, train_loss=0.297]
Epoch 0: 66%|██████▌ | 88/134 [26:13<13:42, 17.88s/it, v_num=0, train_loss=0.297]
Epoch 0: 66%|██████▌ | 88/134 [26:13<13:42, 17.88s/it, v_num=0, train_loss=0.277]
Epoch 0: 66%|██████▋ | 89/134 [26:31<13:24, 17.88s/it, v_num=0, train_loss=0.277]
Epoch 0: 66%|██████▋ | 89/134 [26:31<13:24, 17.88s/it, v_num=0, train_loss=0.264]
Epoch 0: 67%|██████▋ | 90/134 [26:49<13:06, 17.88s/it, v_num=0, train_loss=0.264]
Epoch 0: 67%|██████▋ | 90/134 [26:49<13:06, 17.88s/it, v_num=0, train_loss=0.269]
(autoscaler +29m8s) [workspace snapshot] New snapshot created successfully (size: 465.81 KB).
Epoch 0: 68%|██████▊ | 91/134 [27:06<12:48, 17.88s/it, v_num=0, train_loss=0.269]
Epoch 0: 68%|██████▊ | 91/134 [27:07<12:48, 17.88s/it, v_num=0, train_loss=0.268]
Epoch 0: 69%|██████▊ | 92/134 [27:24<12:30, 17.88s/it, v_num=0, train_loss=0.268]
Epoch 0: 69%|██████▊ | 92/134 [27:24<12:30, 17.88s/it, v_num=0, train_loss=0.200]
Epoch 0: 69%|██████▉ | 93/134 [27:42<12:12, 17.87s/it, v_num=0, train_loss=0.200]
Epoch 0: 69%|██████▉ | 93/134 [27:42<12:12, 17.88s/it, v_num=0, train_loss=0.229]
Epoch 0: 70%|███████ | 94/134 [28:00<11:54, 17.87s/it, v_num=0, train_loss=0.229]
Epoch 0: 70%|███████ | 94/134 [28:00<11:54, 17.87s/it, v_num=0, train_loss=0.248]
Epoch 0: 71%|███████ | 95/134 [28:17<11:37, 17.87s/it, v_num=0, train_loss=0.248]
Epoch 0: 71%|███████ | 95/134 [28:18<11:37, 17.87s/it, v_num=0, train_loss=0.217]
Epoch 0: 72%|███████▏ | 96/134 [28:35<11:19, 17.87s/it, v_num=0, train_loss=0.217]
Epoch 0: 72%|███████▏ | 96/134 [28:35<11:19, 17.87s/it, v_num=0, train_loss=0.217]
Epoch 0: 72%|███████▏ | 97/134 [28:53<11:01, 17.87s/it, v_num=0, train_loss=0.217]
Epoch 0: 72%|███████▏ | 97/134 [28:53<11:01, 17.87s/it, v_num=0, train_loss=0.238]
Epoch 0: 73%|███████▎ | 98/134 [29:11<10:43, 17.87s/it, v_num=0, train_loss=0.238]
Epoch 0: 73%|███████▎ | 98/134 [29:11<10:43, 17.87s/it, v_num=0, train_loss=0.168]
Epoch 0: 74%|███████▍ | 99/134 [29:28<10:25, 17.87s/it, v_num=0, train_loss=0.168]
Epoch 0: 74%|███████▍ | 99/134 [29:29<10:25, 17.87s/it, v_num=0, train_loss=0.198]
Epoch 0: 75%|███████▍ | 100/134 [29:46<10:07, 17.87s/it, v_num=0, train_loss=0.198]
Epoch 0: 75%|███████▍ | 100/134 [29:46<10:07, 17.87s/it, v_num=0, train_loss=0.205]
Epoch 0: 75%|███████▌ | 101/134 [30:04<09:49, 17.86s/it, v_num=0, train_loss=0.205]
Epoch 0: 75%|███████▌ | 101/134 [30:04<09:49, 17.87s/it, v_num=0, train_loss=0.165]
Epoch 0: 76%|███████▌ | 102/134 [30:21<09:31, 17.86s/it, v_num=0, train_loss=0.165]
Epoch 0: 76%|███████▌ | 102/134 [30:22<09:31, 17.86s/it, v_num=0, train_loss=0.261]
Epoch 0: 77%|███████▋ | 103/134 [30:39<09:13, 17.86s/it, v_num=0, train_loss=0.261]
Epoch 0: 77%|███████▋ | 103/134 [30:39<09:13, 17.86s/it, v_num=0, train_loss=0.250]
Epoch 0: 78%|███████▊ | 104/134 [30:57<08:55, 17.86s/it, v_num=0, train_loss=0.250]
Epoch 0: 78%|███████▊ | 104/134 [30:57<08:55, 17.86s/it, v_num=0, train_loss=0.161]
Epoch 0: 78%|███████▊ | 105/134 [31:15<08:37, 17.86s/it, v_num=0, train_loss=0.161]
Epoch 0: 78%|███████▊ | 105/134 [31:15<08:38, 17.86s/it, v_num=0, train_loss=0.202]
Epoch 0: 79%|███████▉ | 106/134 [31:33<08:20, 17.86s/it, v_num=0, train_loss=0.202]
Epoch 0: 79%|███████▉ | 106/134 [31:33<08:20, 17.86s/it, v_num=0, train_loss=0.177]
Epoch 0: 80%|███████▉ | 107/134 [31:50<08:02, 17.86s/it, v_num=0, train_loss=0.177]
Epoch 0: 80%|███████▉ | 107/134 [31:51<08:02, 17.86s/it, v_num=0, train_loss=0.225]
(autoscaler +34m8s) [workspace snapshot] New snapshot created successfully (size: 470.30 KB).
Epoch 0: 81%|████████ | 108/134 [32:08<07:44, 17.86s/it, v_num=0, train_loss=0.225]
Epoch 0: 81%|████████ | 108/134 [32:08<07:44, 17.86s/it, v_num=0, train_loss=0.188]
Epoch 0: 81%|████████▏ | 109/134 [32:26<07:26, 17.86s/it, v_num=0, train_loss=0.188]
Epoch 0: 81%|████████▏ | 109/134 [32:26<07:26, 17.86s/it, v_num=0, train_loss=0.205]
Epoch 0: 82%|████████▏ | 110/134 [32:44<07:08, 17.86s/it, v_num=0, train_loss=0.205]
Epoch 0: 82%|████████▏ | 110/134 [32:44<07:08, 17.86s/it, v_num=0, train_loss=0.218]
Epoch 0: 83%|████████▎ | 111/134 [33:02<06:50, 17.86s/it, v_num=0, train_loss=0.218]
Epoch 0: 83%|████████▎ | 111/134 [33:02<06:50, 17.86s/it, v_num=0, train_loss=0.259]
Epoch 0: 84%|████████▎ | 112/134 [33:20<06:32, 17.86s/it, v_num=0, train_loss=0.259]
Epoch 0: 84%|████████▎ | 112/134 [33:20<06:32, 17.86s/it, v_num=0, train_loss=0.255]
Epoch 0: 84%|████████▍ | 113/134 [33:38<06:15, 17.86s/it, v_num=0, train_loss=0.255]
Epoch 0: 84%|████████▍ | 113/134 [33:38<06:15, 17.86s/it, v_num=0, train_loss=0.221]
Epoch 0: 85%|████████▌ | 114/134 [33:55<05:57, 17.86s/it, v_num=0, train_loss=0.221]
Epoch 0: 85%|████████▌ | 114/134 [33:56<05:57, 17.86s/it, v_num=0, train_loss=0.185]
Epoch 0: 86%|████████▌ | 115/134 [34:13<05:39, 17.86s/it, v_num=0, train_loss=0.185]
Epoch 0: 86%|████████▌ | 115/134 [34:13<05:39, 17.86s/it, v_num=0, train_loss=0.189]
Epoch 0: 87%|████████▋ | 116/134 [34:31<05:21, 17.86s/it, v_num=0, train_loss=0.189]
Epoch 0: 87%|████████▋ | 116/134 [34:31<05:21, 17.86s/it, v_num=0, train_loss=0.168]
Epoch 0: 87%|████████▋ | 117/134 [34:48<05:03, 17.85s/it, v_num=0, train_loss=0.168]
Epoch 0: 87%|████████▋ | 117/134 [34:49<05:03, 17.86s/it, v_num=0, train_loss=0.166]
Epoch 0: 88%|████████▊ | 118/134 [35:06<04:45, 17.85s/it, v_num=0, train_loss=0.166]
Epoch 0: 88%|████████▊ | 118/134 [35:06<04:45, 17.86s/it, v_num=0, train_loss=0.184]
Epoch 0: 89%|████████▉ | 119/134 [35:24<04:27, 17.85s/it, v_num=0, train_loss=0.184]
Epoch 0: 89%|████████▉ | 119/134 [35:24<04:27, 17.86s/it, v_num=0, train_loss=0.230]
Epoch 0: 90%|████████▉ | 120/134 [35:42<04:09, 17.85s/it, v_num=0, train_loss=0.230]
Epoch 0: 90%|████████▉ | 120/134 [35:42<04:09, 17.86s/it, v_num=0, train_loss=0.251]
Epoch 0: 90%|█████████ | 121/134 [36:00<03:52, 17.86s/it, v_num=0, train_loss=0.251]
Epoch 0: 90%|█████████ | 121/134 [36:00<03:52, 17.86s/it, v_num=0, train_loss=0.244]
Epoch 0: 91%|█████████ | 122/134 [36:18<03:34, 17.85s/it, v_num=0, train_loss=0.244]
Epoch 0: 91%|█████████ | 122/134 [36:18<03:34, 17.86s/it, v_num=0, train_loss=0.232]
Epoch 0: 92%|█████████▏| 123/134 [36:35<03:16, 17.85s/it, v_num=0, train_loss=0.232]
Epoch 0: 92%|█████████▏| 123/134 [36:36<03:16, 17.85s/it, v_num=0, train_loss=0.200]
Epoch 0: 93%|█████████▎| 124/134 [36:53<02:58, 17.85s/it, v_num=0, train_loss=0.200]
Epoch 0: 93%|█████████▎| 124/134 [36:53<02:58, 17.85s/it, v_num=0, train_loss=0.152]
(autoscaler +39m8s) [workspace snapshot] New snapshot created successfully (size: 473.57 KB).
Epoch 0: 93%|█████████▎| 125/134 [37:11<02:40, 17.86s/it, v_num=0, train_loss=0.152]
Epoch 0: 93%|█████████▎| 125/134 [37:12<02:40, 17.86s/it, v_num=0, train_loss=0.162]
Epoch 0: 94%|█████████▍| 126/134 [37:29<02:22, 17.86s/it, v_num=0, train_loss=0.162]
Epoch 0: 94%|█████████▍| 126/134 [37:29<02:22, 17.86s/it, v_num=0, train_loss=0.184]
Epoch 0: 95%|█████████▍| 127/134 [37:47<02:04, 17.86s/it, v_num=0, train_loss=0.184]
Epoch 0: 95%|█████████▍| 127/134 [37:47<02:04, 17.86s/it, v_num=0, train_loss=0.186]
Epoch 0: 96%|█████████▌| 128/134 [38:05<01:47, 17.85s/it, v_num=0, train_loss=0.186]
Epoch 0: 96%|█████████▌| 128/134 [38:05<01:47, 17.86s/it, v_num=0, train_loss=0.208]
Epoch 0: 96%|█████████▋| 129/134 [38:23<01:29, 17.85s/it, v_num=0, train_loss=0.208]
Epoch 0: 96%|█████████▋| 129/134 [38:23<01:29, 17.85s/it, v_num=0, train_loss=0.243]
Epoch 0: 97%|█████████▋| 130/134 [38:40<01:11, 17.85s/it, v_num=0, train_loss=0.243]
Epoch 0: 97%|█████████▋| 130/134 [38:41<01:11, 17.85s/it, v_num=0, train_loss=0.243]
Epoch 0: 98%|█████████▊| 131/134 [38:58<00:53, 17.85s/it, v_num=0, train_loss=0.243]
Epoch 0: 98%|█████████▊| 131/134 [38:58<00:53, 17.85s/it, v_num=0, train_loss=0.213]
Epoch 0: 99%|█████████▊| 132/134 [39:16<00:35, 17.85s/it, v_num=0, train_loss=0.213]
Epoch 0: 99%|█████████▊| 132/134 [39:16<00:35, 17.85s/it, v_num=0, train_loss=0.214]
Epoch 0: 99%|█████████▉| 133/134 [39:34<00:17, 17.85s/it, v_num=0, train_loss=0.214]
Epoch 0: 99%|█████████▉| 133/134 [39:34<00:17, 17.85s/it, v_num=0, train_loss=0.182]
Epoch 0: 100%|██████████| 134/134 [39:52<00:00, 17.85s/it, v_num=0, train_loss=0.182]
Epoch 0: 100%|██████████| 134/134 [39:52<00:00, 17.85s/it, v_num=0, train_loss=0.174]
Epoch 0: : 135it [40:10, 17.85s/it, v_num=0, train_loss=0.174]
Epoch 0: : 135it [40:10, 17.85s/it, v_num=0, train_loss=0.176]
(RayTrainWorker pid=13861, ip=10.0.46.116) Checkpoint successfully created at: Checkpoint(filesystem=local, path=/mnt/cluster_storage/finetune_dolly-v2-7b/TorchTrainer_839b5_00000_0_2023-08-30_11-03-25/checkpoint_000000)
(autoscaler +44m9s) [workspace snapshot] New snapshot created successfully (size: 477.63 KB).
(RayTrainWorker pid=66181) Checkpoint successfully created at: Checkpoint(filesystem=local, path=/mnt/cluster_storage/finetune_dolly-v2-7b/TorchTrainer_839b5_00000_0_2023-08-30_11-03-25/checkpoint_000000) [repeated 15x across cluster]
Epoch 0: : 135it [46:03, 20.47s/it, v_num=0, train_loss=0.176]
(RayTrainWorker pid=66181) `Trainer.fit` stopped: `max_epochs=1` reached.
(RayTrainWorker pid=66181) RayFSDPStrategy: tearing down strategy...
2023-08-30 11:51:22,248 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-30 11:51:22,253 INFO tune.py:1142 -- Total run time: 2877.24 seconds (2877.14 seconds for the tuning loop).
Result(
metrics={'train_loss': 0.176025390625, 'epoch': 0, 'step': 135},
path='/mnt/cluster_storage/finetune_dolly-v2-7b/TorchTrainer_839b5_00000_0_2023-08-30_11-03-25',
filesystem='local',
checkpoint=Checkpoint(filesystem=local, path=/mnt/cluster_storage/finetune_dolly-v2-7b/TorchTrainer_839b5_00000_0_2023-08-30_11-03-25/checkpoint_000000)
)
我们在 2877 秒内完成了训练。按需 g4dn.4xlarge 实例的价格为 $1.204/小时,而 g4dn.8xlarge 实例的价格为 $2.176/小时。总成本将是 ($1.204 * 15 + $2.176) * 2877 / 3600 = $16.17。
使用 HuggingFace Pipeline 进行文本生成#
我们可以使用 HuggingFace Pipeline 从我们微调过的模型生成预测。让我们输入一些提示,看看我们调优过的 Dolly 能否像莎士比亚一样说话
import os
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, padding_side="right")
ckpt_path = os.path.join(result.checkpoint.path, "checkpoint.ckpt")
dolly = DollyV2Model.load_from_checkpoint(ckpt_path, map_location=torch.device("cpu"))
nlp_pipeline = pipeline(
task="text-generation",
model=dolly.model,
tokenizer=tokenizer,
device_map="auto"
)
for prompt in ["This is", "I am", "Once more"]:
print(nlp_pipeline(prompt, max_new_tokens=20, do_sample=True, pad_token_id=tokenizer.eos_token_id))
[{'generated_text': "This is the day that our hearts live to love. Now come, go in; I'll sit here:"}]
[{'generated_text': 'I am very sorry, not a jot. What would you have? your pardon? my good lord?'}]
[{'generated_text': 'Once more, look up, look up, my sovereign; look up this night!'}]
参考资料