使用 Ray Serve 扩展 Gradio 应用#
本指南演示如何使用 Ray Serve 扩展您的 Gradio 应用。保持 Gradio 应用的内部架构不变,无需修改代码。只需将应用作为部署包装在 Ray Serve 中,并进行扩展以访问更多资源。
本教程使用运行文本摘要和生成模型的 Gradio 应用,并使用 Hugging Face 的 Pipelines 来访问这些模型。
注意
请记住,如果您想尝试扩展自己的 Gradio 应用,可以用您自己的 Gradio 应用替换本示例应用。
依赖项#
要遵循本教程,您需要 Ray Serve、Gradio 和 transformers。如果您尚未安装,请运行以下命令进行安装:
$ pip install "ray[serve]" gradio==3.50.2 torch transformers
示例 1:使用 GradioServer 扩展 Gradio 应用#
第一个示例使用 T5 Small 模型进行文本摘要,并使用 Hugging Face 的 Pipelines 来访问该模型。它演示了一种将 Gradio 应用部署到 Ray Serve 的简单方法:使用简单的 GradioServer 包装器。示例 2 展示了如何为更定制化的用例使用 GradioIngress。
首先,创建一个名为 demo.py 的 Python 文件。其次,从 Ray Serve 导入 GradioServer 以便稍后部署您的 Gradio 应用,导入 gradio 和 transformers.pipeline 以加载文本摘要模型。
from ray.serve.gradio_integrations import GradioServer
import gradio as gr
from transformers import pipeline
然后,编写一个构建器函数来构造 Gradio 应用 io。
example_input = (
"HOUSTON -- Men have landed and walked on the moon. "
"Two Americans, astronauts of Apollo 11, steered their fragile "
"four-legged lunar module safely and smoothly to the historic landing "
"yesterday at 4:17:40 P.M., Eastern daylight time. Neil A. Armstrong, the "
"38-year-old commander, radioed to earth and the mission control room "
'here: "Houston, Tranquility Base here. The Eagle has landed." The '
"first men to reach the moon -- Armstrong and his co-pilot, Col. Edwin E. "
"Aldrin Jr. of the Air Force -- brought their ship to rest on a level, "
"rock-strewn plain near the southwestern shore of the arid Sea of "
"Tranquility. About six and a half hours later, Armstrong opened the "
"landing craft's hatch, stepped slowly down the ladder and declared as "
"he planted the first human footprint on the lunar crust: \"That's one "
'small step for man, one giant leap for mankind." His first step on the '
"moon came at 10:56:20 P.M., as a television camera outside the craft "
"transmitted his every move to an awed and excited audience of hundreds "
"of millions of people on earth."
)
def gradio_summarizer_builder():
summarizer = pipeline("summarization", model="t5-small")
def model(text):
summary_list = summarizer(text)
summary = summary_list[0]["summary_text"]
return summary
return gr.Interface(
fn=model,
inputs=[gr.Textbox(value=example_input, label="Input prompt")],
outputs=[gr.Textbox(label="Model output")],
)
部署 Gradio Server#
要将您的 Gradio 应用部署到 Ray Serve 上,您需要将 Gradio 应用包装在 Serve deployment 中。GradioServer 充当此包装器。它在 Ray Serve 上远程服务您的 Gradio 应用,以便它可以处理并响应 HTTP 请求。
通过将您的应用包装在 GradioServer 中,您可以增加可供应用使用的 CPU 和/或 GPU 数量。
注意
Ray Serve 不支持将请求路由到 GradioServer 的多个副本,因此您应该只拥有一个副本。
注意
GradioServer 只是 GradioIngress,但包装在 Serve 部署中。您可以将 GradioServer 用于简单的包装和部署用例,但在下一节中,您可以使用 GradioIngress 定义您自己的 Gradio Server,以实现更定制化的用例。
注意
Ray 无法 pickle Gradio。相反,传递一个构造 Gradio 界面的构建器函数。
使用构建器函数构造的 Gradio 应用 io,或您自己的 Gradio 应用(类型为 Interface、Block、Parallel 等),将应用包装在您的 Gradio Server 中。将构建器函数作为输入传递给您的 Gradio Server。Ray Serve 使用构建器函数在 Ray 集群上构造您的 Gradio 应用。
app = GradioServer.options(ray_actor_options={"num_cpus": 4}).bind(
gradio_summarizer_builder
)
最后,部署您的 Gradio Server。假设您将文件保存为 demo.py,在您的终端中运行以下命令:
$ serve run demo:app
在 https://:8000 访问您的 Gradio 应用。输出应如下图所示: 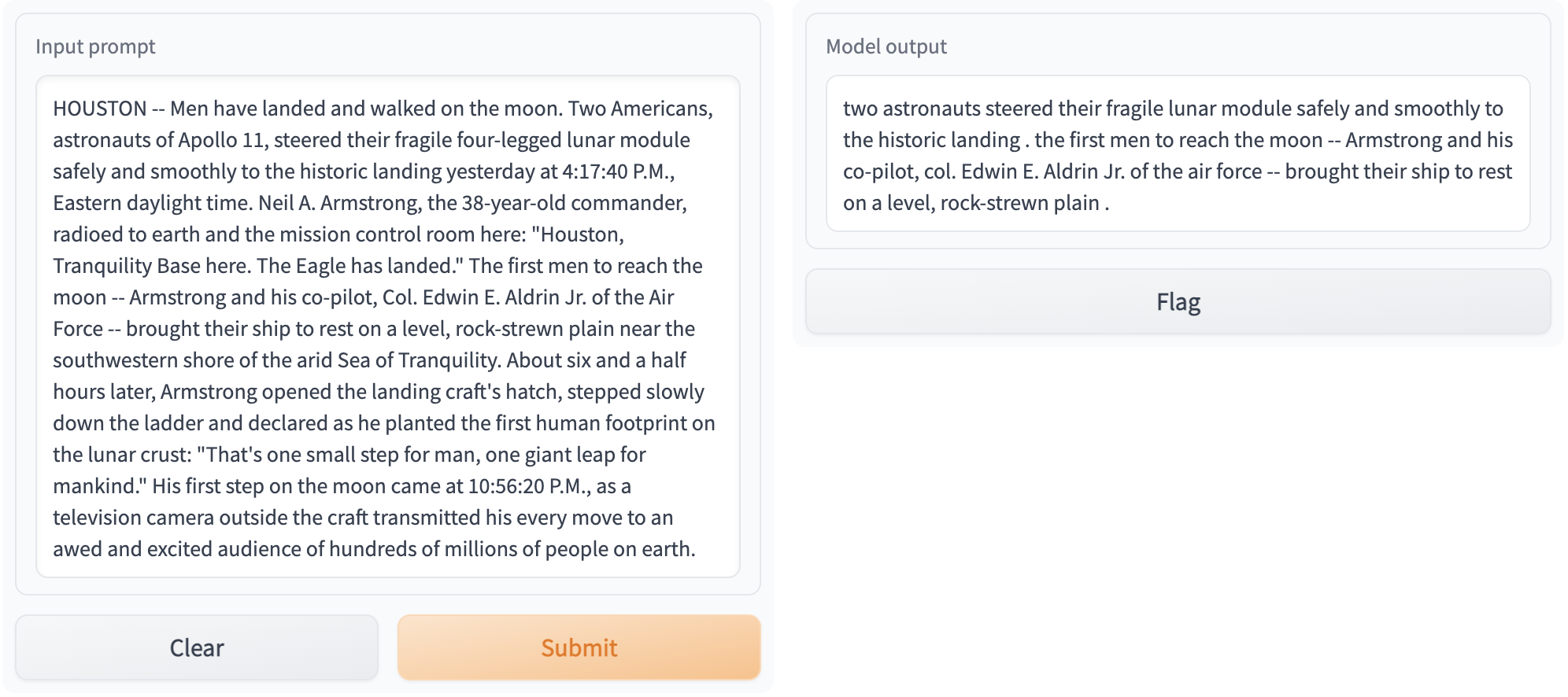
有关如何在生产环境中部署应用的更多信息,请参阅 生产指南。
示例 2:使用 Ray Serve 并行化模型#
您可以通过使用 Ray Serve 中的 模型组合 来使用 Ray Serve 并行运行多个模型。
假设您想运行以下程序。
获取两个文本生成模型:
gpt2和distilgpt2。在相同的输入文本上运行这两个模型,以便生成的文本最小长度为 20,最大长度为 100。
使用 Gradio 显示两个模型的输出。
以下是使用普通 Gradio 的非并行化方法与使用 Ray Serve 的并行化方法的比较。
普通 Gradio#
这是典型的实现代码
generator1 = pipeline("text-generation", model="gpt2")
generator2 = pipeline("text-generation", model="distilgpt2")
def model1(text):
generated_list = generator1(text, do_sample=True, min_length=20, max_length=100)
generated = generated_list[0]["generated_text"]
return generated
def model2(text):
generated_list = generator2(text, do_sample=True, min_length=20, max_length=100)
generated = generated_list[0]["generated_text"]
return generated
demo = gr.Interface(
lambda text: f"{model1(text)}\n------------\n{model2(text)}", "textbox", "textbox"
)
使用此命令启动 Gradio 应用
demo.launch()
使用 Ray Serve 并行化#
使用 Ray Serve,您可以通过将每个模型包装在单独的 Ray Serve deployment 中来实现两个文本生成模型的并行化。您可以通过使用 @serve.deployment 装饰器装饰 Python 类或函数来定义部署。这些部署通常包装您希望部署到 Ray Serve 上以处理传入请求的模型。
按照以下步骤实现并行化。首先,导入依赖项。请注意,您需要导入 GradioIngress 而不是像之前那样导入 GradioServer,因为在本例中,您正在构建一个定制的 MyGradioServer,它可以并行运行模型。
from ray import serve
from ray.serve.handle import DeploymentHandle
from ray.serve.gradio_integrations import GradioIngress
import gradio as gr
import asyncio
from transformers import pipeline
然后,将 gpt2 和 distilgpt2 模型包装在名为 TextGenerationModel 的 Serve 部署中。
@serve.deployment
class TextGenerationModel:
def __init__(self, model_name):
self.generator = pipeline("text-generation", model=model_name)
def __call__(self, text):
generated_list = self.generator(
text, do_sample=True, min_length=20, max_length=100
)
generated = generated_list[0]["generated_text"]
return generated
app1 = TextGenerationModel.bind("gpt2")
app2 = TextGenerationModel.bind("distilgpt2")
接下来,不是简单地将 Gradio 应用包装在 GradioServer 部署中,而是构建您自己的 MyGradioServer,它会重新路由 Gradio 应用,使其运行 TextGenerationModel 部署。
@serve.deployment
class MyGradioServer(GradioIngress):
def __init__(
self, downstream_model_1: DeploymentHandle, downstream_model_2: DeploymentHandle
):
self._d1 = downstream_model_1
self._d2 = downstream_model_2
super().__init__(lambda: gr.Interface(self.fanout, "textbox", "textbox"))
async def fanout(self, text):
[result1, result2] = await asyncio.gather(
self._d1.remote(text), self._d2.remote(text)
)
return (
f"[Generated text version 1]\n{result1}\n\n"
f"[Generated text version 2]\n{result2}"
)
最后,将所有内容连接起来
app = MyGradioServer.bind(app1, app2)
注意
此步骤将您在 Serve 部署中包装的两个文本生成模型绑定到 MyGradioServer._d1 和 MyGradioServer._d2,形成一个 模型组合。在此示例中,Gradio Interface io 调用 MyGradioServer.fanout(),该函数将请求发送到您部署在 Ray Serve 上的两个文本生成模型。
现在,您可以运行您的可扩展应用,以在 Ray Serve 上并行提供这两个文本生成模型服务。使用以下命令运行您的 Gradio 应用:
$ serve run demo:app
在 https://:8000 访问您的 Gradio 应用,您应该看到以下交互式界面: 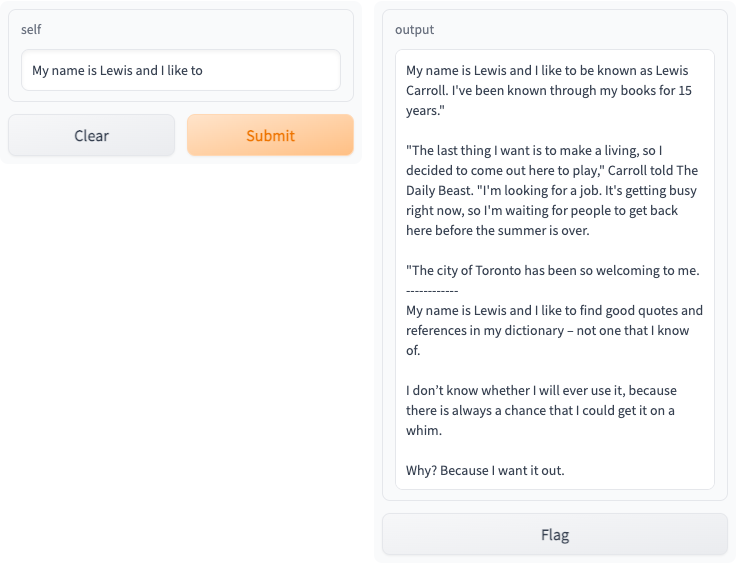
有关如何在生产环境中部署应用的更多信息,请参阅 生产指南。