在 YARN 上部署#
警告
在 YARN 上运行 Ray 仍在开发中。如果您有关于如何改进本文档的建议或想请求缺失的功能,请随时创建拉取请求或使用下方问题或疑问?部分中的任一渠道与我们联系。
本文档假设您拥有 YARN 集群的访问权限,并将引导您使用 Skein 部署一个 YARN 作业,该作业将启动一个 Ray 集群并在其上运行示例脚本。
Skein 使用声明性规范(可以通过 yaml 文件或 Python API 编写),允许用户无需编写 Java 代码即可启动作业和扩展应用。
您首先需要安装 Skein:pip install skein。
此处使用的 Skein yaml 文件和示例 Ray 程序在 Ray 仓库中提供,以便您快速开始。请参考提供的 yaml 文件,以确保您保留了 Ray 正常运行所需的重要配置选项。
Skein 配置#
Ray 作业配置为运行两个 Skein 服务
启动 Ray head 节点然后运行应用的
ray-head服务。启动加入 Ray 集群的 worker 节点的
ray-worker服务。您可以在此配置中更改实例数量,或在运行时使用skein container scale动态扩缩容集群。
每个服务的规范包括启动服务所需的文件和要运行的命令。
services:
ray-head:
# There should only be one instance of the head node per cluster.
instances: 1
resources:
# The resources for the worker node.
vcores: 1
memory: 2048
files:
...
script:
...
ray-worker:
# Number of ray worker nodes to start initially.
# This can be scaled using 'skein container scale'.
instances: 3
resources:
# The resources for the worker node.
vcores: 1
memory: 2048
files:
...
script:
...
打包依赖#
使用 files 选项指定将复制到 YARN 容器中供应用使用的文件。有关更多信息,请参阅Skein 文件分发页面。
services:
ray-head:
# There should only be one instance of the head node per cluster.
instances: 1
resources:
# The resources for the head node.
vcores: 1
memory: 2048
files:
# ray/doc/yarn/example.py
example.py: example.py
# # A packaged python environment using `conda-pack`. Note that Skein
# # doesn't require any specific way of distributing files, but this
# # is a good one for python projects. This is optional.
# # See https://jcrist.github.io/skein/distributing-files.html
# environment: environment.tar.gz
在 YARN 中设置 Ray#
以下是用于启动 ray-head 和 ray-worker 服务的 bash 命令演练。请注意,此配置会为每个应用启动新的 Ray 集群,而不是复用同一个集群。
Head 节点命令#
首先激活一个预先存在的环境以进行依赖管理。
source environment/bin/activate
在 Skein 键值存储中注册 worker 所需的 Ray head 地址。
skein kv put --key=RAY_HEAD_ADDRESS --value=$(hostname -i) current
启动 Ray head 节点所需的所有进程。默认情况下,我们将对象存储内存和堆内存设置为约 200 MB。这是一个保守值,应根据应用需求进行设置。
ray start --head --port=6379 --object-store-memory=200000000 --memory 200000000 --num-cpus=1
执行包含 Ray 程序的用户脚本。
python example.py
即使应用失败或被杀死,也要清理所有已启动的进程。
ray stop
skein application shutdown current
总而言之,我们有
ray-head:
# There should only be one instance of the head node per cluster.
instances: 1
resources:
# The resources for the head node.
vcores: 1
memory: 2048
files:
# ray/doc/source/cluster/doc_code/yarn/example.py
example.py: example.py
# # A packaged python environment using `conda-pack`. Note that Skein
# # doesn't require any specific way of distributing files, but this
# # is a good one for python projects. This is optional.
# # See https://jcrist.github.io/skein/distributing-files.html
# environment: environment.tar.gz
script: |
# Activate the packaged conda environment
# - source environment/bin/activate
# This stores the Ray head address in the Skein key-value store so that the workers can retrieve it later.
skein kv put current --key=RAY_HEAD_ADDRESS --value=$(hostname -i)
# This command starts all the processes needed on the ray head node.
# By default, we set object store memory and heap memory to roughly 200 MB. This is conservative
# and should be set according to application needs.
#
ray start --head --port=6379 --object-store-memory=200000000 --memory 200000000 --num-cpus=1
# This executes the user script.
python example.py
# After the user script has executed, all started processes should also die.
ray stop
skein application shutdown current
Worker 节点命令#
从 Skein 键值存储中获取 head 节点的地址。
RAY_HEAD_ADDRESS=$(skein kv get current --key=RAY_HEAD_ADDRESS)
在 Ray worker 节点上启动所有必需的进程,阻塞直到被 Skein/YARN 通过 SIGTERM 杀死。接收到 SIGTERM 后,所有已启动的进程也应终止 (ray stop)。
ray start --object-store-memory=200000000 --memory 200000000 --num-cpus=1 --address=$RAY_HEAD_ADDRESS:6379 --block; ray stop
总而言之,我们有
ray-worker:
# The number of instances to start initially. This can be scaled
# dynamically later.
instances: 4
resources:
# The resources for the worker node
vcores: 1
memory: 2048
# files:
# environment: environment.tar.gz
depends:
# Don't start any worker nodes until the head node is started
- ray-head
script: |
# Activate the packaged conda environment
# - source environment/bin/activate
# This command gets any addresses it needs (e.g. the head node) from
# the skein key-value store.
RAY_HEAD_ADDRESS=$(skein kv get --key=RAY_HEAD_ADDRESS current)
# The below command starts all the processes needed on a ray worker node, blocking until killed with sigterm.
# After sigterm, all started processes should also die (ray stop).
ray start --object-store-memory=200000000 --memory 200000000 --num-cpus=1 --address=$RAY_HEAD_ADDRESS:6379 --block; ray stop
运行作业#
在您的 Ray 脚本中,使用以下命令连接到已启动的 Ray 集群
ray.init(address="localhost:6379")
main()
您可以使用以下命令启动 Skein YAML 文件中指定的应用。
skein application submit [TEST.YAML]
提交后,您可以在 YARN dashboard 上看到正在运行的作业。
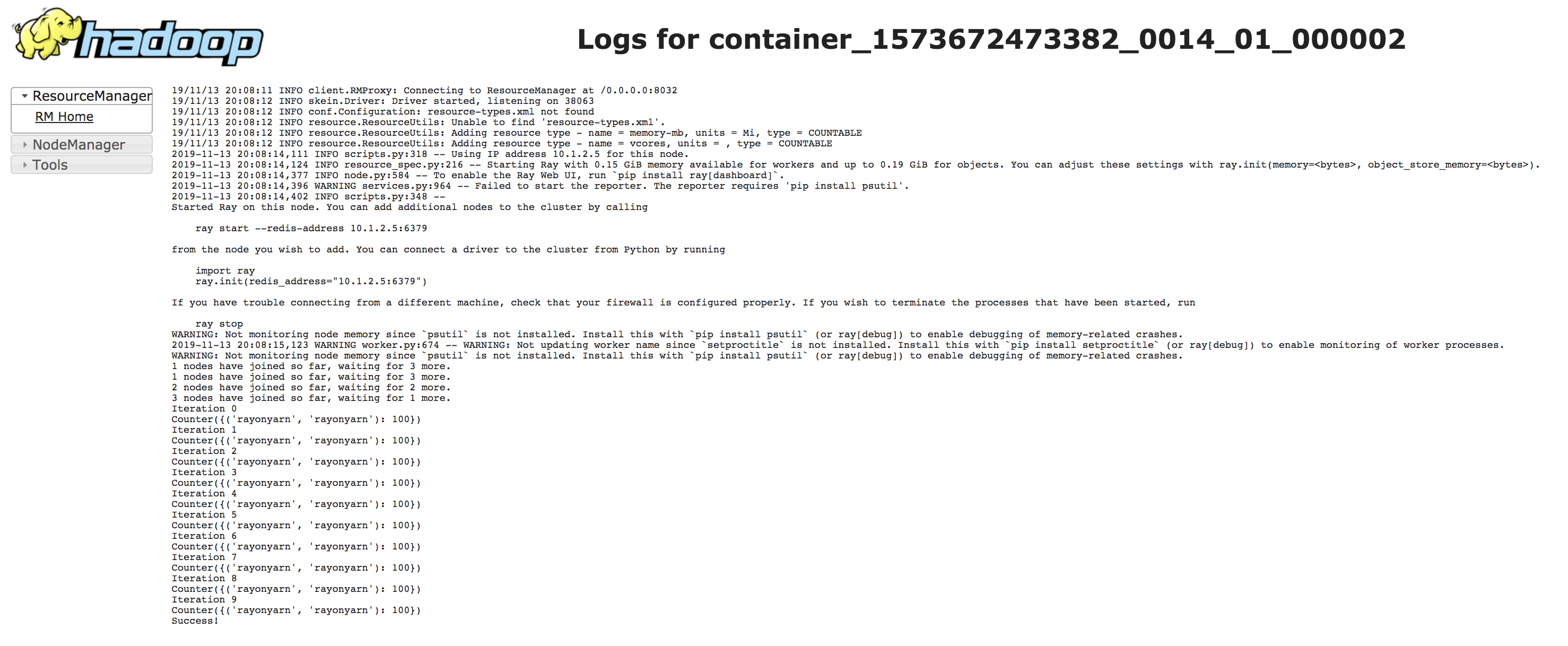
清理#
要清理正在运行的作业,使用以下命令(使用应用 ID)
skein application shutdown $appid
问题或疑问?#
您可以通过以下渠道发布问题、疑问或反馈
讨论区:用于提出关于 Ray 用法的问题或功能请求。
GitHub Issues:用于提交错误报告。
Ray Slack:用于联系 Ray 维护者。
StackOverflow:使用 [ray] 标签提出关于 Ray 的问题。